This document explains to researchers, data scientists, and business analysts the processes and considerations for analyzing Fast Healthcare Interoperability Resources (FHIR) data in BigQuery.
Specifically, this document focuses on patient resource data that is exported from the FHIR store in the Cloud Healthcare API. This document also steps through a series of queries that demonstrate how FHIR schema data works in a relational format, and shows you how to access these queries for reuse through views.
Using BigQuery for analyzing FHIR data
The FHIR-specific API of the Cloud Healthcare API is designed for real-time transactional interaction with FHIR data at the level of a single FHIR resource or a collection of FHIR resources. However, the FHIR API is not designed for analytics use cases. For these use cases, we recommend exporting your data from the FHIR API to BigQuery. BigQuery is a serverless, scalable data warehouse that lets you analyze large quantities of data retrospectively or prospectively.
Additionally, BigQuery conforms to ANSI:2011 SQL, which makes data accessible to data scientists and business analysts through tools that they typically use, such as Tableau, Looker, or Vertex AI Workbench.
In some applications, such as Vertex AI Workbench, you get access through built-in clients, such as the Python Client library for BigQuery. In these cases, the data returned to the application is available through built-in language data structures.
Accessing BigQuery
You can access BigQuery through the BigQuery web UI in the Google Cloud console, and also with the following tools:
- The BigQuery command-line tool
- The BigQuery REST API or client libraries
- ODBC and JDBC drivers
By using these tools, you can integrate BigQuery into almost any application.
Working with the FHIR data structure
The built-in FHIR standard data structure is complex, with nested and embedded
FHIR data types
throughout any FHIR resource. These embeddable FHIR data types are referred to
as
complex data types.
Arrays and structures are also referred to as complex data types in relational
databases. The built-in FHIR standard data structure works well serialized as
XML or JSON files in a document-oriented system, but the structure can be
challenging to work with when translated into relational databases.
The following screenshot shows a partial view of a FHIR
patient resource
data type that illustrates the complex nature of the built-in FHIR standard data
structure.
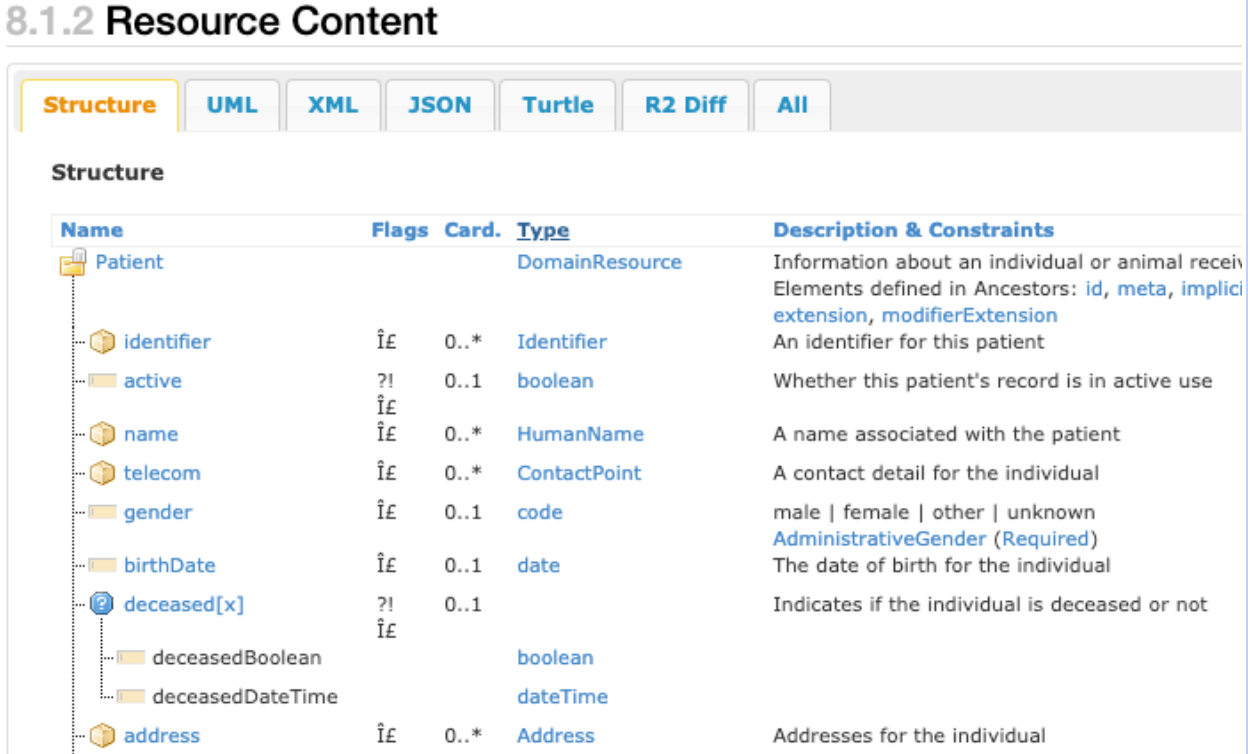
The preceding screenshot shows the primary components of a FHIR patient
resource data type. For example, the
cardinality
column (indicated in the table as Card.) shows several items that can have
zero, one, or more than one entries. The Type column shows the
Identifier,
HumanName,
and
Address
data types, which are examples of complex data types that comprise the patient
resource data type. Each of these rows can be recorded multiple times, as an
array of structures.
Using arrays and structures
BigQuery supports arrays and
STRUCT data types—nested,
repeated data structures—as they are represented in FHIR resources, which makes
data conversion from FHIR to BigQuery possible.
In BigQuery, an array is an ordered list consisting of zero or
more values of the same data type. You can construct arrays of simple data
types, such as the INT64 data type, and complex data types, such as the
STRUCT data type. The exception is the ARRAY data type, because arrays of
arrays are not currently supported. In BigQuery, an array of
structures appears as a repeatable record.
You can specify nested data, or nested and repeated data, in the
BigQuery UI or in a JSON schema file. To specify nested columns,
or nested and repeated columns, use the RECORD (STRUCT) data type.
The Cloud Healthcare API supports the
SQL on FHIR schema
in BigQuery. This analytics schema is the default schema on the
ExportResources() method and is supported by the FHIR community.
BigQuery supports denormalized data. This means that when you store your data, instead of creating a relational schema such as a star or snowflake schema, you can denormalize your data and use nested and repeated columns. Nested and repeated columns maintain relationships between data elements without the performance impact of preserving a relational (normalized) schema.
Accessing your data through the UNNEST operator
Every FHIR resource in the FHIR API is exported into BigQuery as
one row of data. You can think of an array or structure inside any row as an
embedded table. You can access data in that "table" in either the SELECT
clause or the WHERE clause of your query by
flattening the array or structure by using the UNNEST operator.
The UNNEST operator takes an array and returns a table with a single row for
each element in the array. For more information, see
working with arrays in standard SQL.
The UNNEST operation doesn't preserve the order of the array elements, but
you can reorder the table by using the optional WITH OFFSET clause. This
returns an additional column with the OFFSET clause for each array element.
You can then use the ORDER BY clause to order the rows by their offset.
When joining unnested data, BigQuery uses a
correlated CROSS JOIN
operation that references the column of arrays from each item in the array with
the source table, which is the table that directly precedes the call to UNNEST
in the FROM clause. For each row in the source table, the UNNEST operation
flattens the array from that row into a set of rows containing the array
elements. The correlated CROSS JOIN operation joins this new set of rows with
the single row from the source table.
Investigating the schema with queries
To query FHIR data in BigQuery, it's important to understand the
schema that's created through the export process. BigQuery lets
you inspect the column structure of every table in the dataset through the
INFORMATION_SCHEMA
feature, a series of views that display metadata. The remainder of this document
refers to the
SQL on FHIR schema,
which is designed to be accessible for retrieving data.
The following sample query explores the column details for the patient table in the SQL on FHIR schema. The query references the Synthea Generated Synthetic Data in FHIR public dataset, which hosts over 1 million synthetic patient records generated in the Synthea and FHIR formats.
When you query the
INFORMATION_SCHEMA.COLUMNS
view, the query results contain one row for each column (field) in a table. The
following query returns all columns in the patient table:
SELECT * FROM `bigquery-public-data.fhir_synthea.INFORMATION_SCHEMA.COLUMNS` WHERE table_name='patient'
The following screenshot of the query result shows the identifier data type,
and the array within the data type that contains the STRUCT data types.

Using the FHIR patient resource in BigQuery
The patient medical record number (MRN), a critical piece of information stored in your FHIR data, is used throughout an organization's clinical and operational data systems for all patients. Any method of accessing data for an individual patient or a set of patients must filter for or return the MRN, or do both.
The following sample query returns the internal FHIR server identifier to the patient resource itself, including the MRN and the date of birth for all patients. The filter to query on a specific MRN is also included, but is commented out in this example.
In this query, you unnest the identifier complex data type twice. You also use
correlated CROSS JOIN operations to join unnested data with its source table.
The bigquery-public-data.fhir_synthea.patient table in the query was created
by using the
SQL on FHIR schema version of the FHIR to BigQuery export.
SELECT id, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b"
The output is similar to the following:
In the preceding query, the identifier.type.coding.code value set is the
FHIR identifier value set
that enumerates available identity data types, such as the MRN (MR identity
data type), driver's license (DL identity data type), and passport number
(PPN identity data type). Because the identifier.type.coding value set is an
array, there can be any number of identifiers listed for a patient. But in this
case, you want the MRN (MR identity data type).
Joining the patient table with other tables
Building on the patient table query, you can join the patient table with other tables in this dataset, such as the conditions table. The conditions table is where patient diagnoses are recorded.
The following sample query retrieves all entries for the medical condition of hypertension.
SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003'
The output is similar to the following:
In the preceding query, you reuse the UNNEST method to flatten the
code.coding field. The abatement.dateTime and onset.dateTime code
elements in the SELECT statement are aliased because they both end in
dateTime, which would result in ambiguous column names in the output of a
SELECT statement. When you select the Hypertension code, you also need to
declare the terminology system that the code comes from—in this case, the
SNOMED CT
clinical terminology system.
As the final step, you use the subject.patientid key to join the condition
table with the patient table. This key points to the identifier of the patient
resource itself within the FHIR server.
Bringing the queries together
In the following sample query, you use the queries from the two preceding
sections and join them by using the
WITH
clause, while performing some simple calculations.
WITH patient AS ( SELECT id as patientid, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b" ), condition AS ( SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003' ) SELECT patient.patientid, patient.MRN, patient.birthDate as birthDate_string, #current patient age. now - birthdate CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH)/12 AS INT) as patient_current_age_years, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH) AS INT) as patient_current_age_months, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),DAY) AS INT) as patient_current_age_days, #age at onset. onset date - birthdate DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset, condition.onset_dateTime, condition.code.code, condition.code.display, condition.code.system FROM patient JOIN condition ON patient.patientid = condition.patientid
The output is similar to the following:
In the preceding sample query, the WITH clause lets you isolate subqueries
into their own defined segments. This approach can help with legibility, which
becomes more important as your query grows larger. In this query, you isolate
the subquery for patients and conditions into their own WITH segments, and
then join them in the main SELECT segment.
You can also apply calculations to raw data. The following sample code, a
SELECT statement, shows how to calculate patient's age at disease onset.
DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset
As indicated in the preceding code sample, you can perform a number of
operations on the supplied dateTime string, condition.onset_dateTime. First,
you select the date component of the string with the
SUBSTR
value. Then you convert the string into a DATE data type by using the
CAST
syntax. You also convert the patient.birthDate field to the DATEfield.
Finally, you calculate the difference between the two dates by using the
DATE_DIFF
function.
What's next
- Analyze clinical data using BigQuery and AI Platform Notebooks.
- Visualizing BigQuery data in a Jupyter notebook.
- Cloud Healthcare API security.
- BigQuery access control.
- Healthcare and life sciences solutions in Google Cloud Marketplace.
- Explore reference architectures, diagrams, and best practices about Google Cloud. Take a look at our Cloud Architecture Center.