
Wikisłownik:Bar/Dyskusje ogólne
Stolik, przy którym omawiamy tematy ogólne dotyczące Wikisłownika, kierunków rozwoju, jak również wszystkie kwestie, niepasujące do innych stolików. Miłych i owocnych dyskusji!
Zobacz też osobne stoliki barowe
- Wikisłownik:Bar/Logo
- Wikisłownik:Bar/Gdy hasło pęka w szwach
- Wikisłownik:Bar/Aspekt czasownika
- Wikisłownik:Bar/propozycje programistyczne
- Wikisłownik:Bar/wymowa, IPA, AS, sylaby
- Wikisłownik:Bar/tłumaczenie interfejsu
- Wikisłownik:Bar/nazwiska i imiona
- Wikisłownik:Bar/formy (nie)deprecjatywne
Nazwiska i imiona
Dyskusję przeniesiono do stolika Wikisłownik:Bar/nazwiska i imiona. Proszę nie archiwizować tej sekcji – tymczasowo pozostawiono ją, aby linki prowadzące do niej nadal działały. Peter Bowman (dyskusja) 12:03, 19 sie 2016 (CEST)
Formy (nie)deprecjatywne w tabelkach odmiany
Dyskusję przeniesiono do stolika Wikisłownik:Bar/formy (nie)deprecjatywne. Proszę nie archiwizować tej sekcji – tymczasowo pozostawiono ją, aby linki prowadzące do niej nadal działały. Peter Bowman (dyskusja) 17:25, 1 sty 2017 (CET)
Gwara śląska a kwalifikatory
Kwestia, która mnie zastanawia od dłuższego czasu. (Chyba była gdzieś wcześniej wspomniana przez innego edytora). Dlaczego gwara (tj. elementy niebędące częścią języka ogólnego) śląska jest u nas oznaczana jako regionalizmy (tj. elementy należące do regionalnej odmiany języka ogólnego)? Jest to mylenie pojęć. Duża część tak oznaczonych definicji jest daleka od polszczyzny ogólnej, o podanych przykładach, które są dla większości Polaków trudne do zrozumienia, nie wspomnę. Sugeruję zastąpić szablon {{reg}} szablonem {{gw}} w szablonie {{śląsk}}, zmienić nazwę Kategoria:Regionalizmy śląskie i przyjrzeć się innym regionalizmom. PiotrekDDYSKUSJA 20:08, 7 gru 2016 (CET)
- Problem zasygnalizował wcześniej Ksymil w poniższych wątkach:
- Przed podjęciem próby uporządkowania szablonów i kategorii spytałbym: jak można by rozróżnić wyrazy należące do danego etnolektu (gwara) od właściwych regionalizmów? Sama kategoria Kategoria:Regionalizmy śląskie zawiera prawie 800 stron, prawdopodobnie większość nie została uźródłowiona. Pozdrawiam, Peter Bowman (dyskusja) 15:30, 1 sty 2017 (CET)
- @Peter Bowman
- Um, dobre pytanie. Występowanie pojedynczego słowa można sprawdzić w słownikach standardowej polszczyzny, gorzej, gdy jest ich 800. Na moje oko większość się wydaje gwarowa, ale nie jestem w temacie zbytnio. Dla bezpieczeństwa (tj. nieraczenia czytelników błędnymi informacjami) proponowałbym przekształcić {{śląsk}} i zmienić nazwę kategorii.
- Warto zwrócić uwagę na „regionalizmy” poznańskie. Jest ich dużo, większość ma źródło (chwała twórcy za to!), jakim jest {{Gruchmanowa1997online}}. Już sam tytuł słownika sugeruje, że mamy kontakt z gwarą miejską. Tutaj bez wahania IMO powinniśmy zmienić {{poznań}} i przemianować kategorię.
- Pozdrawiam, PiotrekDDYSKUSJA 21:48, 10 lut 2017 (CET)
- @PiotrekD: wydaje mi się, że w takim układzie łatwo się pogubić, nie wiedząc, które wystąpienia szablonów należy przejrzeć po tych przetasowaniach. Tzn. przekształcimy {{śląsk}} i {{poznań}}, przemianujemy kategorie, ale wszystko to w założeniu, że większość haseł została odwrotnie skategoryzowana, czyli po pierwsze kierujemy się intuicją, a nie źródłami (może nie w takim stopniu w przypadku szablonu {{poznań}}, ale rozumiem, że przeglądzie podglega cały szereg pozostałych gwar/dialektów/regionalizmów), a po drugie nadal część haseł będzie wymagała poprawek – tylko nadal nie wiadomo, która. Ponieważ obecne szablony z serii {{regionalizm}} nie są doskonałe, rozważyłbym porzucenie ich na rzecz nowej rodziny szablonów. Swego czasu napisałem {{reg-es}}, który w pojedynkę obsługuje wszystkie regionalizmy hiszpańskie. Może więc {{reg-pl}} i {{gw-pl}}? Bezpieczeństwo natomiast można osiągnąć w inny sposób: wyłączając kategoryzację i ukrywając skrót reg. do czasu uporządkowania haseł. Pozdrawiam, Peter Bowman (dyskusja) 00:35, 11 lut 2017 (CET)
- @Peter Bowman: Wydaje mi się to dobrym rozwiązaniem, szczególnie że drogi @Abraham zajął się właśnie opisywaniem gwary Śląska Cieszyńskiego na podstawie drukowanego źródła. Pozdrawiam, PiotrekDDYSKUSJA 16:16, 20 mar 2017 (CET) Odpowiedź zawsze na czas…
- @Peter Bowman: Pingu. Ostatnio nam przybywa trochę haseł śląskich. PiotrekDDYSKUSJA 17:06, 4 kwi 2017 (CEST)
- @PiotrekD: zerknę w ten weekend. Peter Bowman (dyskusja) 17:43, 4 kwi 2017 (CEST)
- @Peter Bowman: Jak tam zerkanie? Jeśli nie masz czasu, mogę ja sam się tym zająć. Nie chciałbym Ci tylko wchodzić w drogę, jeśli sam chcesz się tym zająć. Pozdrawiam serdecznie, PiotrekDDYSKUSJA 18:23, 16 cze 2017 (CEST)
- @PiotrekD: za tydzień zacznę odhaczać zaległości, kwestia regionalizmów pójdzie na pierwszy ogień. Dam znać, jeżeli coś mnie znowu zatrzyma i nie dam rady. Przepraszam, Peter Bowman (dyskusja) 21:32, 16 cze 2017 (CEST)
- @PiotrekD: przykro mi, znowu się nie udało. Jeżeli nikt się tym nie zajmie, spróbuję ponownie. Pozdrawiam, Peter Bowman (dyskusja) 01:12, 3 lip 2017 (CEST)
- @Peter Bowman: Mam jeszcze dwie kwestie, nim przystąpię do działania. Czy planujemy w dłuższej perspektywie całkowicie zrezygnować ze {{śląsk}}, {{lwów}} i podobnych (ja tak bym to widział)? Czy postałe szablony powinny kategoryzować wedle schematu używanego obecnie w języku polskim (Kategoria:Regionalizmy REGIONALNE) czy wedle schematu używanego obecnie w języku hiszpańskim (Kategoria:Regionalizmy hiszpańskie - REGION)? Pozdrawiam, PiotrekDDYSKUSJA 11:32, 4 lip 2017 (CEST)
- @PiotrekD: na dłuższą metę trudno mi to ocenić, skróty mogą się przydać; w każdym razie tych szablonów nie należy kasować. Jest jeszcze inna opcja: {{reg-es}} stosuje format (Region1, Region2, ...), jednak wewnątrz nawiasów (chyba że je opuścimy) mogą widnieć właśnie skróty – (reg. śl., reg. pozn...). Kiedyś {{reg-es}} dopuszczał rozwijanie {{hiszpam}}, jednak porzuciłem tę możliwość na rzecz ujednolicenia zapisu regionów. Schemat kategorii wg mnie powinien ulec zmianie, abyśmy się nie pogubili przy rozróżnianiu wywołań nowych i starych szablonów. Ja bym dla porządku uwzględnił w nim nazwę języka, ponadto ta sama nazwa regionu mogłaby odpowiadać więcej niż jednemu językowi. Pozdrawiam, Peter Bowman (dyskusja) 16:46, 4 lip 2017 (CEST)
- @Peter Bowman: Zgadzam się w kwestii kategorii. W kwestii skrótów – ja generalnie widziałbym te wywołania tak:
- Nie widzę powodu powtarzania {{reg}} czy {{gw}} wielokroć, nawiasy na samym początku definicji wedle mnie źle wyglądają (to dotyczy także sprawy imię męskie i imię żeńskie w obcych językach, ale nie o tym tutaj mowa). Skrótów bym chciał uniknąć ze względu na czytelność i możliwą liczbę terytoriów, gdy mowa o gwarach. Pozdrawiam, PiotrekDDYSKUSJA 17:15, 4 lip 2017 (CEST)
- @PiotrekD: na dłuższą metę trudno mi to ocenić, skróty mogą się przydać; w każdym razie tych szablonów nie należy kasować. Jest jeszcze inna opcja: {{reg-es}} stosuje format (Region1, Region2, ...), jednak wewnątrz nawiasów (chyba że je opuścimy) mogą widnieć właśnie skróty – (reg. śl., reg. pozn...). Kiedyś {{reg-es}} dopuszczał rozwijanie {{hiszpam}}, jednak porzuciłem tę możliwość na rzecz ujednolicenia zapisu regionów. Schemat kategorii wg mnie powinien ulec zmianie, abyśmy się nie pogubili przy rozróżnianiu wywołań nowych i starych szablonów. Ja bym dla porządku uwzględnił w nim nazwę języka, ponadto ta sama nazwa regionu mogłaby odpowiadać więcej niż jednemu językowi. Pozdrawiam, Peter Bowman (dyskusja) 16:46, 4 lip 2017 (CEST)
- @Peter Bowman: Mam jeszcze dwie kwestie, nim przystąpię do działania. Czy planujemy w dłuższej perspektywie całkowicie zrezygnować ze {{śląsk}}, {{lwów}} i podobnych (ja tak bym to widział)? Czy postałe szablony powinny kategoryzować wedle schematu używanego obecnie w języku polskim (Kategoria:Regionalizmy REGIONALNE) czy wedle schematu używanego obecnie w języku hiszpańskim (Kategoria:Regionalizmy hiszpańskie - REGION)? Pozdrawiam, PiotrekDDYSKUSJA 11:32, 4 lip 2017 (CEST)
- @Peter Bowman: Jak tam zerkanie? Jeśli nie masz czasu, mogę ja sam się tym zająć. Nie chciałbym Ci tylko wchodzić w drogę, jeśli sam chcesz się tym zająć. Pozdrawiam serdecznie, PiotrekDDYSKUSJA 18:23, 16 cze 2017 (CEST)
- @PiotrekD: zerknę w ten weekend. Peter Bowman (dyskusja) 17:43, 4 kwi 2017 (CEST)
- @PiotrekD: wydaje mi się, że w takim układzie łatwo się pogubić, nie wiedząc, które wystąpienia szablonów należy przejrzeć po tych przetasowaniach. Tzn. przekształcimy {{śląsk}} i {{poznań}}, przemianujemy kategorie, ale wszystko to w założeniu, że większość haseł została odwrotnie skategoryzowana, czyli po pierwsze kierujemy się intuicją, a nie źródłami (może nie w takim stopniu w przypadku szablonu {{poznań}}, ale rozumiem, że przeglądzie podglega cały szereg pozostałych gwar/dialektów/regionalizmów), a po drugie nadal część haseł będzie wymagała poprawek – tylko nadal nie wiadomo, która. Ponieważ obecne szablony z serii {{regionalizm}} nie są doskonałe, rozważyłbym porzucenie ich na rzecz nowej rodziny szablonów. Swego czasu napisałem {{reg-es}}, który w pojedynkę obsługuje wszystkie regionalizmy hiszpańskie. Może więc {{reg-pl}} i {{gw-pl}}? Bezpieczeństwo natomiast można osiągnąć w inny sposób: wyłączając kategoryzację i ukrywając skrót reg. do czasu uporządkowania haseł. Pozdrawiam, Peter Bowman (dyskusja) 00:35, 11 lut 2017 (CET)
@Peter Bowman: Czas leci, a temat ciągle w miejscu. W październiku utworzyłem {{reg-pl}} i {{gw-pl}}, a wraz z nimi Moduł:reg-pl i Moduł:reg-pl/dane. Co o nich sądzisz (i co o nim sądzą inni zainteresowani)? Trzeba tylko dorobić do niego drzewko kategorii, dodać dokumentację i być może uzupełnić listę regionów. Czy nie ma żadnych przeciwwskazań, bym zaczął go stosować w artykułach i przenosić stare regionalizmy/gwarę na nowy system w miarę dostępu do źródeł? PiotrekDDYSKUSJA 19:17, 18 sty 2018 (CET)
- @PiotrekD: szablony działają, mechanizm jest sprawdzony (od dawna działa na nim {{reg-es}}), sprzeciwów dotychczas nie było. Ostatni komentarz jest jednak z lipca, więc wstawiłbym wpis na TO, aby edytorzy przypomnieli sobie / poznali tę propozycję, może wyjawią się wtedy jakieś niezauważone wady. Wspomnij też o botowaniu, przy czym Twój bot mógłby rozpocząć pracę za tydzień lub dwa. Pozdrawiam, Peter Bowman (dyskusja) 21:18, 18 sty 2018 (CET)
- PS dzięki, że znalazłeś czas na to i podjąłeś się jego realizacji :).
@Peter Bowman: Czasu trochę znów upłynęło, ale w końcu dałem ogłoszenie na tablicy ogłoszeń. Przykład użycia nowego systemu widać już teraz w haśle perć. PiotrekDDYSKUSJA 13:39, 7 lut 2018 (CET)
Propozycja zmian w numeracji przypisów rzeczowych (uwag)
Witam serdecznie. Zwracam się do Społeczności z prośbą o poparcie mojej propozycji zmiany numeracji przypisów rzeczowych (uwag) w hasłach. Jak dotąd mamy do czynienia w przypisach do źródeł z numeracją cyframi od 1 wzwyż. Uwagi numerowane są także numerycznie, ale przy pojawiających się wywołaniach takiego przypisu-uwagi mamy rozwlekły zapis: [uwaga 1], co nie wygląda za dobrze, i bardzo rozciąga np. tabele odmiany przy umieszczeniu uwagi wewnątrz niej, np.:
| Aktualnie | Proponowana wersja | ||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
W Wikipedii i wielu innych projektach uwagi numerowane są przy użyciu małych liter alfabetu – znacznie skraca to zapis w haśle, np. [a]. Co sądzicie o takiej zmianie? Pozdrawiam, Karol Szapsza (dyskusja) 16:24, 10 cze 2017 (CEST)
- Patrząc na moje doświadczenia z {{współczesna}}, preferowałbym nie dodawać tej informacji jako przypis, ale jako zwykłą uwagę w uwagach. PiotrekDDYSKUSJA 23:06, 10 cze 2017 (CEST)
- Postąpiłbym jak Piotrek. W zasadzie zastanawiam się, czy nie lepiej zrezygnować z tego typu przypisów – wiążą się one ze wstawieniem dodatkowej pary znaczników w tekście, zdarzają się wątpliwości, łatwo popełnić błąd (Specjalna:Diff/5619740). Wspomnę przy okazji, że skutkiem ubocznym proponowanej zmiany będzie zamiana zapisu liczbowego w polu „źródła” na alfabetyczny, w przypadku przypisów wielokrotnych: por. kot#pl • w:Minecraft#Przypis (u nas:
1. ↑ 1,0 1,1; w Wikipedii:1. ↑ a b). Pozdrawiam, Peter Bowman (dyskusja) 23:46, 10 cze 2017 (CEST)
Część mowy – jęz. rosyjski
rzeczownik żywotny, rodzaj męski, czy rzeczownik, rodzaj męski żywotny? Karol Szapsza (dyskusja) 20:06, 12 cze 2017 (CEST)
- Tak jak w szablonie: rzeczownik żywotny, rodzaj jakiś tam, bo kategoria żywotności nie jest uzależniona od rodzaju w j. ros. :) 20:44, 13 cze 2017 (CEST)
Ok dziękuję za odpowiedź, robiłem dotychczas niepoprawnie. Karol Szapsza (dyskusja) 21:55, 13 cze 2017 (CEST)
- Zatem popraw swoje niepoprawne edycje i miłego edytowania:) Krokus (dyskusja) 22:06, 13 cze 2017 (CEST)
- Przeanalizowałem rosyjskie rzeczowniki, znalazłem tylko szesnaście wystąpień
męski/żeński żywotnyw polu znaczeń – poprawiłem ręcznie. Pozdrawiam, Peter Bowman (dyskusja) 00:47, 7 lip 2017 (CEST)
Wymowa w hasłach łacińskich – transkrypcja fonetyczna, czy fonemiczna?
Jakim szablonem posłużyć się przy dodawaniu wymowy do haseł łacińskich – {{IPA}} (wym. fonemiczna), czy {{IPA3}} (wym. fonetyczna)? W hasłach polskich dodajemy IPA3, w angielskich IPA, w rosyjskich IPA3. Problem mam przy hasłach łacińskich, albowiem w angielskim Wikisłowniku podaje się oba zapisy – np. dura lex, sed lex: /ˈduː.ra ˈleːks sed ˈleːks/, [ˈduː.ra ˈɫeːks sɛd ˈɫeːks]. Karol Szapsza (dyskusja) 21:17, 16 cze 2017 (CEST)
- Zacznijmy może od tego, że należałoby w tych hasłach uporządkować warianty wymowy, bo łacina to język martwy i nie ma jednej określonej fonologii. Pozdrawiam, PiotrekDDYSKUSJA 23:22, 16 cze 2017 (CEST)
Zaznaczanie akcentu w dzieleniu wyrazu (szablon: {{dzielenie}})
Witam, chciałbym zapytać Społeczność o opinię w kwestii zaznaczania lub niezaznaczania akcentów wyrazowych w hasłach rosyjskich w szablonie dzielenia wyrazu. Jak powinno to wyglądać?
- podział przy przenoszeniu wyrazu: стер•ве́ц
czy
- podział przy przenoszeniu wyrazu: стер•вец
W chwili bieżącej zaznaczanie akcentu powoduje błędy – jeśli mamy je zaznaczać, trzeba zmodyfikować kod szablonu. Proszę o opinie. Karol Szapsza (dyskusja) 22:02, 11 lip 2017 (CEST)
- @Karol Szapsza: Ja najchętniej widziałbym akcent zaznaczany wszędzie – również w dzieleniu i w tłumaczeniach w haśle polskim – dla ułatwienia życia czytelników poprzez ograniczenie konieczności skakania po hasłach. (Zdaje się, że @Krokus ma inne zdanie w związku z ruchomością akcentu w odmianie niektórych słów, ping). Problemem jest jednak to, że zaznaczenie akcentu wymaga używania bardzo problematycznych znaków łączących. Jakiś czas temu prowadziłem luźną dyskusję na ten temat na kanale IRC z Peterem. Można byłoby to ułatwić np. poprzez stosowanie specjalnego szablonu, który konwertowałby na znak akcentu choćby apostrofy, które łatwo wprowadzić; „
{{l|д'ома}}” i/lub „{{l|дома|д'ома}}” (ten drugi wariant raczej przy linkowaniu form zależnych; przy formach podstawowych chyba lepszy byłby pierwszy wariant, który sam usuwałby apostrof z adresu docelowego, jednocześnie oznaczając odpowiednio akcent w warstwie wizualnej) dawałoby „до́ма”. (Szablonu do linkowania używają już na es.wikt, tylko tam nieco w innym celu: wikt:es:Plantilla:l). O wszystkim można pomyśleć. (O, swoją drogą – tej samej technologii można byłoby użyć do zaznaczania łacińskiego iloczasu). Pozdrawiam, PiotrekDDYSKUSJA 14:31, 16 lip 2017 (CEST)
Dyskusja zamarła… Co dalej z szablonem i ww. propozycjami? @Peter Bowman, wypowiesz się? Karol Szapsza (dyskusja) 21:23, 8 wrz 2017 (CEST)
- @Karol Szapsza: nie było sprzeciwu, więc chyba możemy dopuścić obecność akcentów w szablonie dzielenia. Chwilowo się tego nie podejmę, ale proponuję utworzenie modułu zamieniającego dowolny znak (lub listę znaków) na inny, plus drugi moduł do wydajnego generowania linków dla dowolnej liczby parametrów w {{dzielenie}} i podobnych. Pierwszy z tych modułów można by wykorzystać w ewentualnym szablonie {{l}}, jak proponuje wyżej Piotrek, jednak tę kwestię (wprowadzenie akcentów wszędzie, gdzie to możliwe) omówiłbym w osobnym wątku. Pozdrawiam, Peter Bowman (dyskusja) 13:55, 9 wrz 2017 (CEST)
odmiana-przymiotnik-białoruski
Witam, proponuję utworzenie nowego szablonu na kształt szablonu z tej strony. Póki co posiłkuję się szablonem odmiana-rzeczownik-białoruski i efekt jest taki. Pozdrawiam Superjurek (dyskusja) 10:06, 27 lip 2017 (CEST)
- Popieram. Wstawiałem ręcznie sporo odmian przymiotników np. камуністычны. W tabeli byłoby przejrzyściej. Proponowałbym przystosować nasz szablon dotyczący rosyjskich przymiotników. Gramatyka rosyjska i białoruska się nie różni, jeśli chodzi o odmianę przymiotników. Mamy takie same przypadki, analogiczny wpływ żywotności na odmianę, podobnie jest z obocznością w narzędniku rodzaju żeńskiego (tego akurat w szablonie z angielskiego Wikisłownika nie ma). Pozdrawiam. Sankoff64 (dyskusja) 10:59, 27 lip 2017 (CEST)
Accessible editing buttons
Możesz już zobaczyć starszy i nowy wygląd. Większość edytujących zauważy tylko, że niektóre przyciski są nieco większe i mają inne kolory.
- Porównanie starego i nowego stylu
-
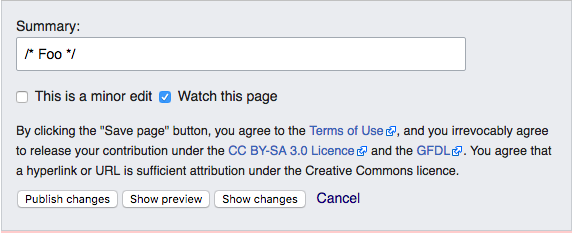 Przyciski przed zmianą
Przyciski przed zmianą -
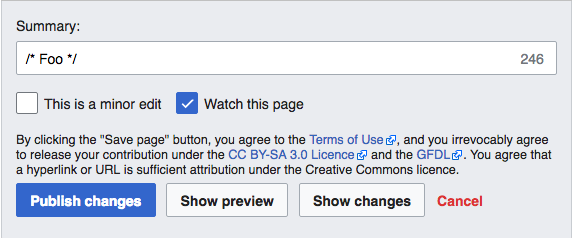 Przyciski po zmianie
Przyciski po zmianie


Może to jednak wpłynąć na niektóre skrypty użytkowników i gadżety. Niestety, niektóre z nich mogą nie działać zbyt dobrze w nowym systemie. Jeżeli utrzymujesz jakieś skrypty użytkowników lub gadżety, które są wykorzystywane podczas edycji, zobacz mw:Contributors/Projects/Accessible editing buttons po informacje o tym, jak testować i poprawiać skrypty. Przestarzałe skrypty można już testować i poprawiać.
Ta zmiana prawdopodobnie dotrze na tę wiki we wtorek 1 sierpnia 2017. Zostaw informację na mw:Talk:Contributors/Projects/Accessible editing buttons jeżeli potrzebujesz pomocy.--Whatamidoing (WMF) (talk) 18:56, 27 lip 2017 (CEST)
czterdziestodwuminutowy, trzydziestosześciopiętrowy
Zacząłem dodawanie haseł takich jak двенадцатиминутный, jednak nurtuje mnie pytanie, jak daleko powinniśmy brnąć przy tworzeniu tego typu haseł? O ile pospolite są zrosty piętnastominutowy, czteropiętrowy, czy trzystopniowy, o tyle wyrazy czterdziestodwuminutowy, trzydziestosześciopiętrowy, dwudziestosiedmiostopniowy są mniej popularne – ale nie mniej poprawne. Czy zasługują zatem na miejsce w słowniku? Kiedy powinniśmy zatrzymać się, aby nie dotrzeć przypadkiem do tysiącstopięćdziesięcioczterostopniowy?:) Interesuje mnie, czy istnieją już jakieś wytyczne. Pozdrawiam, Karol Szapsza (dyskusja) 19:21, 30 lip 2017 (CEST)
- Póki dany wyraz występuje w słownikach i korpusach, to nie powinno być problemu. We wszystkim jednak trzeba się kierować rozsądkiem i umiarem. Sankoff64 (dyskusja) 19:41, 30 lip 2017 (CEST)
nazwy geograficzne: jak zaznaczyć, że celowo brak przymiotnika odrzeczownikowego
Czy ktoś może zaglądał do mojego pytania? Dyskusja szablonu:przym KaMan (dyskusja) 17:30, 14 sie 2017 (CEST)
Związki frazeologiczne
Czy istnieje możliwość, aby sekcja związki frazeologicznie była zorganizowana w postaci 2 lub 3 (może nawet 4) kolumn? W podobny sposób jak sekcja tłumaczenia? Myślę, że spowodowałoby to większą czytelność (dla czytelników), a także większą czytelność (dla edytorów) takich stron jak np. ręka, głowa itp. Zetzecik (dyskusja) 23:03, 20 sie 2017 (CEST)
Columns for references
Witajcie,
Na życzenie edytujących Wikipedię została dodana nowa funkcjonalność do MediaWiki. Długie listy przypisów będą automatycznie dzielone na kolumny. Ułatwi to większości czytanie przypisów, zwłaszcza na wąskich ekranach. Nie wpłynie to na krótsze listy przypisów.
Planowane włączenie tej funkcji na tej wiki to poniedziałek, 11 września 2017. Po tym czasie wystarczy użyć zwykłego znacznika <references /> na stronie z dużą liczbą przypisów, aby ta funkcja zadziałała. Jeżeli jednak na danej stronie przypisy nie mają wyświetlać się w kolumnach, użyj tego wikikodu: <references responsive="0" />
20:23, 1 wrz 2017 (CEST)
- Przykład: po polskiemu (permalink). Peter Bowman (dyskusja) 13:55, 26 maj 2018 (CEST)
burzliwa dyskusja nad odmiennością rzeczownika kakao
Drodzy Współredaktorzy Wikisłownika,
Z racji, iż obawiam się eskalacji niepotrzebnych w tym temacie i w tym miejscu negatywnych emocji, proponuję wspólne przedyskutowanie problemu zaistniałego przy ustaleniu, jak należy umocować w haśle kakao istnienie nienormatywnych, ale coraz częściej wykorzystywanych i co najważniejsze popartych encyklopedycznym źródłem w postaci SGJP. Osobiście uważam, iż Wikisłownik nie powinien być odzwierciedleniem poglądów tylko jednego autorytety w dziedzinie języka polskiego, którym jest powszechnie szanowany i przytaczany prof. Jan Miodek. Wikisłownik podobnie jak Wikipedia ma za zadanie przedstawiać wielość naszej wiedzy o świecie. Tak więc moim zdaniem nie powinniśmy bezzasadnie cenzurować informacji odzwierciedlających rzeczywistość (ograniczenie informacji do Uwag w haśle uważam za cenzurę – używanie szablonu {{potencjalnie}} ma różne oblicza w Wikisłowniku i nie uważam abym w tej materii popełnił błąd). Aby nie mnożyć bytów i kopiować innych wcześniej wysuniętych argumentów, to osobom zainteresowanym rozwiązaniem tego konfliktu polecam zapoznanie się z wcześniej odbytymi rozmowami w dyskusjach: mojej, kolegi Sankoff'a oraz kolegi Piotrka. Proszę przy tym też o neutralny język i merytoryczność wpisów; gdyż jakby nie było, Bar jest następną instancją w prowadzeniu rozmów, po wyczerpaniu pozytywnych rokowań na dyskusjach wikipedystów oraz gdy dalsza dyskusja wymagałaby rozbijania wymiany wpisów po kilku stronach dyskusji. Pozdrawiam Superjurek (dyskusja) 17:54, 8 wrz 2017 (CEST)
Śledziłem wcześniejsze spokojne i rzeczowe argumenty Sankoff64 i PiotrkaD i zgadzam się z nimi KaMan (dyskusja) 18:13, 8 wrz 2017 (CEST)
- [Konflikt edycji, i to na ogromnej stronie…]
- Pozwoliłem sobie poświęcić mój czas i przejrzeć wszystkie słowniki, do których mam teraz dostęp, w poszukiwaniu odmiennego słowa „kakao”. Oto wyniki:
- Słowo występuje wyłącznie jako nieodmienne w źródłach: Słownik ortograficzny S. Jodłowskiego i W. Taszyckiego z '58 (Ossolińskich), {{Doroszewski1958}} (oraz {{DoroszewskiOnline}}), Mały słownik języka polskiego pod red. S. Skorupki z '68 (PWN), {{Szymczak1978}}, {{Doroszewski1980}} (potępia odmianę), {{USJPonline}}, Młodzieżowy słownik ortograficzny W. Wichrowskiej z '03 (Wilga), {{Drabik2006}}, {{Podlawska2009}}, {{BańkoISJP2014}}, Wielki słownik ortograficzny PWN pod red. E. Polańskiego z '16 (również w internetowej wersji {{SWOonline}}).
- {{MarkowskiWSPP2004}} podaje w uwadze (nie w odmianie), że można uznać za dopuszczalne w bardzo swobodnej polszczyźnie.
- {{GrzeniaSPP2004}} podaje w uwadze (nie w odmianie), że tylko w języku potocznym.
- {{SGJPonline}} podaje jako niezalecane.
- Dlatego proszę o niezarzucanie mi opieranie się na prywatnych awersjach w miejscu encyklopedycznych pozycyj i z góry za to dziękuję. (Zwłaszcza że po drugiej stronie żadne źródło poza SGJP nie padło, o ile dobrze widzę).
- Spośród wymienionych źródeł dwie mają rekomendację Rady Języka Polskiego – Uniwersalny słownik języka polskiego i Wielki słownik ortograficzny PWN (we wcześniejszym wydaniu, ale w tej kwestii raczej nic się od tamtego czasu nie zmieniło)[1]. Oba podają, że jest to słowo wyłącznie nieodmienne. O SGJP, na który się powoływano, już pisałem; raczę tylko wskazać, że jest to dzieło o zdecydowanie niższym poważaniu niż wspomniane słowniki zarekomendowane przez RJP czy pewuanowskie słowniki poprawnej polszczyzny, bardzo permisywne, a nawet ono używa kwalifikatora niezal.
- Proszę też dyskutanta o niezarzucanie osobom o odmiennym zdaniu chęci cenzurowania Wikisłownika, omawiana tu kwestia nie jest kwestią o takiej randze, która wymagałaby takich środków i takich słów.
- Pozdrawiam, PiotrekDDYSKUSJA 18:42, 8 wrz 2017 (CEST)
- PS: Swoje zdanie o zakresie użycia {{potencjalnie}} podtrzymuję, ale to może być już temat na inną dyskusję.
- PPS: Pozwolę sobie na ciekawostkę, odnosząc się do rzekomych prywatnych awersyj. Nie mam nic przeciwko odmienianiu „kakao” samemu w sobie, sam czasami odmieniam, bo prywatnie uważam, że należy odmieniać to, co się da zgodnie z gramatyką. Mam natomiast coś przeciwko nieuzasadnionym gramatycznie formom „kakale” i „kakał”. Moje prywatne zdanie jednak nie ma tu znaczenia, bo uważam, że Wikisłownik winien być oparty na źródłach, nie „a mnie i mojej grupie kolegów się widzi”.
- @PiotrekD Wobec ogromu Twoich argumentów nie pozostaję mi nic innego niż przyznać Ci rację i przerosić za zarzucenie prywatnych awersyj oraz za zarzucenie cenzury. Pierwszą z tych rzeczy zarzuciłem ze względu na emocjonalność z jaką zaprotestowałeś na stronie mojej dyskusji. Poczyłem się po prostu zaatakowany. Jeśli zaś chodzi o bezzasadną cenzurę to zarzuciłem ją, gdyż wcześniej nie padły tak precyzyjne argumenty wykazujące brak zasadności umieszczenia wariantów fleksyjnych w rubryczce Odmiana. Dalej jednak utrzymuję, że szablon {{potencjalnie}} ma w takich sytuacjach zastosowanie. Podobnie jak przy tworzeniu 1.os lp rodzaju nijakiego np. zrobiłom albo 2.os zrobiłoś. Żadna z tych form nie jest stosowana na co dzień, choć potencjalnie są możliwe do utworzenia, tak więc na Wikisłowniku formy -om/-oś istnieją jako potencjalne. Formy fleksyjne rzeczownika kakao nie są aprobowane, ale ich stworzenie jest możliwe do stworzenia. Przy czym szara czcionka tego szablonu uwidacznia nierównocenność odmienności i nieodmienności tego rzeczownika. Natomiast do uwag zamieszczonych już w haśle ja osobiście nie mam żadnych zastrzeżeń. Jedynie uważam, że w oparciu o nie zasadne jest umieszczenie form odmiennych opatrzonych szablonem {{potencjalnie}}. Jeśli zaś chodzi o formy kakał i kakale, to jak w takim razie można wyjaśnić istnienie powiedzenia Makao i po makale!? Przez analogię do słowa makao, które ma zbliżoną budowę do słowa kakao dałoby się powiedzieć, iż forma (o) kakale jest zasadna. Natomiast w przypadku formy kakał, chciałbym zwrócić uwagę, że w D. lm zachodzi skrócenie sufiksu. O ile kakau jest wymawiane dłużej, to w D. lm dochodzi do skrócenia końcówki słowotwórczej. Jeśli się mylę to jestem gotów przyznać rację moim oponentom, natomiast w ten sposób argumentuję swoje stanowisko. Superjurek (dyskusja) 07:00, 9 wrz 2017 (CEST)
- Nie wiem, czy poczułeś się zaatakowany mą wypowiedzią, ale na pewno nie taki był mój cel, gdym ją pisał. Ja sam nie widzę w niej też nic nader emocjonalnego, ot na wstępie „śmiem się wtrącić i stanowczo sprzeciwić” (za {{USJPonline}}: Śmiem twierdzić, wątpić «zwrot używany w sytuacji, gdy chce się grzecznie, lecz stanowczo wyrazić swoją opinię, często przeciwstawiając się innym»), następnie pozwoliłem sobie, odnosząc się do „l”/„ł” bez uzasadnienia gramatycznego, użyć – niepotrzebnie, jeśli wywołało to taki odbiór – słowa „rzyć”, które jednak nie jest wulgarne ni pospolite, o czym już pisałem na Twej dyskusji. Przepraszam, jeśli Cię to uraziło. Komunikacja tekstowa ma tę wadę (i zarazem zaletę), że nie widać rozmówcy i jego mowy ciała, przez co trudne może być odgadywanie emocyj i intencyj osoby siedzącej po drugiej stronie. (Między innymi dlatego myślę, że dobrym pomysłem byłoby spotkanie się w świecie realnym między 27 a 29 października w Poznaniu i podyskutowanie tam. Więcej informacyj: 1, 2. Wybaczcie nieco reklamową wstawkę, ale naprawdę wydaje mi się, że to dobry pomysł ;)). Pozdrawiam serdecznie, PiotrekDDYSKUSJA 10:31, 9 wrz 2017 (CEST)
- @PiotrekD Wobec ogromu Twoich argumentów nie pozostaję mi nic innego niż przyznać Ci rację i przerosić za zarzucenie prywatnych awersyj oraz za zarzucenie cenzury. Pierwszą z tych rzeczy zarzuciłem ze względu na emocjonalność z jaką zaprotestowałeś na stronie mojej dyskusji. Poczyłem się po prostu zaatakowany. Jeśli zaś chodzi o bezzasadną cenzurę to zarzuciłem ją, gdyż wcześniej nie padły tak precyzyjne argumenty wykazujące brak zasadności umieszczenia wariantów fleksyjnych w rubryczce Odmiana. Dalej jednak utrzymuję, że szablon {{potencjalnie}} ma w takich sytuacjach zastosowanie. Podobnie jak przy tworzeniu 1.os lp rodzaju nijakiego np. zrobiłom albo 2.os zrobiłoś. Żadna z tych form nie jest stosowana na co dzień, choć potencjalnie są możliwe do utworzenia, tak więc na Wikisłowniku formy -om/-oś istnieją jako potencjalne. Formy fleksyjne rzeczownika kakao nie są aprobowane, ale ich stworzenie jest możliwe do stworzenia. Przy czym szara czcionka tego szablonu uwidacznia nierównocenność odmienności i nieodmienności tego rzeczownika. Natomiast do uwag zamieszczonych już w haśle ja osobiście nie mam żadnych zastrzeżeń. Jedynie uważam, że w oparciu o nie zasadne jest umieszczenie form odmiennych opatrzonych szablonem {{potencjalnie}}. Jeśli zaś chodzi o formy kakał i kakale, to jak w takim razie można wyjaśnić istnienie powiedzenia Makao i po makale!? Przez analogię do słowa makao, które ma zbliżoną budowę do słowa kakao dałoby się powiedzieć, iż forma (o) kakale jest zasadna. Natomiast w przypadku formy kakał, chciałbym zwrócić uwagę, że w D. lm zachodzi skrócenie sufiksu. O ile kakau jest wymawiane dłużej, to w D. lm dochodzi do skrócenia końcówki słowotwórczej. Jeśli się mylę to jestem gotów przyznać rację moim oponentom, natomiast w ten sposób argumentuję swoje stanowisko. Superjurek (dyskusja) 07:00, 9 wrz 2017 (CEST)
- Znalazłem ten wpis Grzegorza Jagodzińskiego nt. odmiany wyrazu „kakao”: [2]. Zgadzam się z Piotrkiem – nie takie jest przeznaczenie szablonu {{potencjalnie}}, natomiast te formy lepiej zostawić wyłącznie w polu uwag (obecnie dostatecznie rozwiniętym i uźródłowionym, więc nie doceniam tu wspomnianej cenzury). Pozdrawiam, Peter Bowman (dyskusja) 16:06, 9 wrz 2017 (CEST)
- Forma niezalecana nie jest formą potencjalną, bo jest niestey, przynajmniej przez niektórych, używana. Dla mnie jest to forma błędna, a wtedy odpowiedniejszy jest szablon {{źle}} w sekcji uwagi. Zetzecik (dyskusja) 23:50, 9 wrz 2017 (CEST)
- Pragnę zauważyć, że tak jak stwierdził to przywołany powyżej Grzegorz Jagodziński: Nade wszystko okazuje się ona jednak mało adekwatna do rzeczywistości: odmienne formy wyrazu kakao słyszy się w normalnej polszczyźnie powszechnie, a więc nie tylko w języku bardzo swobodnym. Wyrażenie ciasto z kakao wydaje się wręcz nienaturalne i niezrozumiałe (zrobiono je z kakaa czy też jedynie posypano kakaem?).; tak też ja mówiłem wcześniej. Autorytety językowe postulują pewne wzorce, które nie zawsze odpowiadają rzeczywistości, tworząc nijako własną rzeczywistość zwaną puryzmem językowym. Pytanie, czy na każdym kroku należy zaklinać rzeczywistość wedle usankcjonowanych reguł językowych, czy może lepiej opisywać mechanizmy językowe, które w języku zachodzą spontanicznie? Nieraz te procesy językowe zachodzą wbrew myśleniu życzeniowemu językoznawców, czego przykładem jest potępiany przez wielu (ale pospolity) Ms. lp o kakale oraz D. lm kakał, na bazie których powstało zdrobnienie kakałko. Moim skromnym zdaniem, które mogę wyrazić w przestrzeni technicznej, język polski jest tworem żywym, a gdy wpadnie do niego wyraz pochodzenia obcego, to jego los może być różny: jeśli używany jest rzadko, to pozostaje nieodmienny; jeśli zaś używany jest bardzo często to nieuniknione jest jego uplastycznienie w postaci form fleksyjnych. Dobrym tego przykładem jest radio które pierwotnie było nieodmienne, a dziś używanie go jako nieodmiennego przemawia za ekscentryzmem użytkownika języka. Mimo iż prywatnie popieram odmienianie kakaa, to skłonię się ku stwierdzeniu, że obie formy mają swoje wady i zalety. W środowiskach korzystających z kakaa na każdym kroku ciężko byłoby mówić ciągle kakao, kakao, kakao, kakao... bez dodatkowych informacyj o pozycji tego słowa w zdaniu (przykładem jest Zrobiłem ciasto z kakao. rozumianym dwojako: Zrobiłem ciasto z kakaa. lub Zrobiłem ciasto z kakaem.); wówczas bardzo praktycznym staje się odmienianie kakaa przez przypadki. Z drugiej jednak strony w pełni rozumiem przedstawicieli środowisk naukowych, gdzie operuje się ogromnym zasobem słownictwa i gdzie liczy się stosowanie możliwie najprostszych form językowych – np. na potrzeby wyszukiwarek słów kluczowych (po napisaniu słowa kakao mało prawdopodobne, aby Google Scholar wyświetlił mi pracę, gdzie jednorazowo przewinęło się zdanie ze słowem kakaem). Oprócz wspomnianych przeze mnie i nie tylko mnie słów makao, rodeo, wideo oraz radio dorzucę jeszcze jedno – Maroko. Czy słowo to mimo, iż jest wyrazem pochodzenia obcego jest nieodmienne? Ano jest odmienne! Podczas gdy w języku rosyjskim zarówno какао, макао, радио i Марокко są nieodmienne. Superjurek (dyskusja) 11:41, 10 wrz 2017 (CEST)
- Nie wiem w sumie, czy z tej wypowiedzi wynika coś więcej niż z wypowiedzi na stronie dyskusji Sankoffa, ale na wszelki wypadek zalinkuję w:WP:OR. PiotrekDDYSKUSJA 13:23, 10 wrz 2017 (CEST)
- Pragnę zauważyć, że tak jak stwierdził to przywołany powyżej Grzegorz Jagodziński: Nade wszystko okazuje się ona jednak mało adekwatna do rzeczywistości: odmienne formy wyrazu kakao słyszy się w normalnej polszczyźnie powszechnie, a więc nie tylko w języku bardzo swobodnym. Wyrażenie ciasto z kakao wydaje się wręcz nienaturalne i niezrozumiałe (zrobiono je z kakaa czy też jedynie posypano kakaem?).; tak też ja mówiłem wcześniej. Autorytety językowe postulują pewne wzorce, które nie zawsze odpowiadają rzeczywistości, tworząc nijako własną rzeczywistość zwaną puryzmem językowym. Pytanie, czy na każdym kroku należy zaklinać rzeczywistość wedle usankcjonowanych reguł językowych, czy może lepiej opisywać mechanizmy językowe, które w języku zachodzą spontanicznie? Nieraz te procesy językowe zachodzą wbrew myśleniu życzeniowemu językoznawców, czego przykładem jest potępiany przez wielu (ale pospolity) Ms. lp o kakale oraz D. lm kakał, na bazie których powstało zdrobnienie kakałko. Moim skromnym zdaniem, które mogę wyrazić w przestrzeni technicznej, język polski jest tworem żywym, a gdy wpadnie do niego wyraz pochodzenia obcego, to jego los może być różny: jeśli używany jest rzadko, to pozostaje nieodmienny; jeśli zaś używany jest bardzo często to nieuniknione jest jego uplastycznienie w postaci form fleksyjnych. Dobrym tego przykładem jest radio które pierwotnie było nieodmienne, a dziś używanie go jako nieodmiennego przemawia za ekscentryzmem użytkownika języka. Mimo iż prywatnie popieram odmienianie kakaa, to skłonię się ku stwierdzeniu, że obie formy mają swoje wady i zalety. W środowiskach korzystających z kakaa na każdym kroku ciężko byłoby mówić ciągle kakao, kakao, kakao, kakao... bez dodatkowych informacyj o pozycji tego słowa w zdaniu (przykładem jest Zrobiłem ciasto z kakao. rozumianym dwojako: Zrobiłem ciasto z kakaa. lub Zrobiłem ciasto z kakaem.); wówczas bardzo praktycznym staje się odmienianie kakaa przez przypadki. Z drugiej jednak strony w pełni rozumiem przedstawicieli środowisk naukowych, gdzie operuje się ogromnym zasobem słownictwa i gdzie liczy się stosowanie możliwie najprostszych form językowych – np. na potrzeby wyszukiwarek słów kluczowych (po napisaniu słowa kakao mało prawdopodobne, aby Google Scholar wyświetlił mi pracę, gdzie jednorazowo przewinęło się zdanie ze słowem kakaem). Oprócz wspomnianych przeze mnie i nie tylko mnie słów makao, rodeo, wideo oraz radio dorzucę jeszcze jedno – Maroko. Czy słowo to mimo, iż jest wyrazem pochodzenia obcego jest nieodmienne? Ano jest odmienne! Podczas gdy w języku rosyjskim zarówno какао, макао, радио i Марокко są nieodmienne. Superjurek (dyskusja) 11:41, 10 wrz 2017 (CEST)
- Forma niezalecana nie jest formą potencjalną, bo jest niestey, przynajmniej przez niektórych, używana. Dla mnie jest to forma błędna, a wtedy odpowiedniejszy jest szablon {{źle}} w sekcji uwagi. Zetzecik (dyskusja) 23:50, 9 wrz 2017 (CEST)
- To kiedy uzupełnimy tabelę odmiany czasownika "pójść" o błędną (niezalecaną?) formę "poszłem", skoro jest prostsza i powszechnie używana przez niepurystów językowych?
- A co zrobić z formami odmiany charakterystycznymi dla naturalnego języka dziecięcego, np. "człowieki", "piesy" itd. Zetzecik (dyskusja) 20:29, 11 wrz 2017 (CEST)
{{słow}}
Proponuję usunąć szablon {{słow}} (w zamierzeniu: słowiański(e)) i zastąpić go komunikatem ostrzegawczym na wzór {{fr}}, {{ar}} czy {{turk}}. Szablon / skrót ten był dotąd rzadko używany i zawsze błędnie: albo chodziło o słowacki, albo o słoweński, albo o prasłowiański, ewentualnie o jakiś konkretny język słowiański do wydedukowania ze źródła albo z hasła. Przydatność słow. jest w słowniku praktycznie żadna, najczęściej oznacza to, że autor sam nie wie, co tak konkretnie chce napisać (albo nie chce mu się sprawdzić, o jaki język czy też jaki etap rozwojowy języka mu chodzi). Słowem: mylące i niejasne. W razie potrzeby wskazania wszystkich / wielu języków słowiańskich, ale nie na etapie prasłowiańskim, można skorzystać z szablonu {{ogsłow}}. Maitake (dyskusja) 12:45, 16 wrz 2017 (CEST)
- Popieram. PiotrekDDYSKUSJA 17:07, 16 wrz 2017 (CEST)
"termin" w rozwinięciach skrótów
Informuję że od jakiegoś czasu dodaję do skrótów wskazujących na dziedzinę wiedzy słówko "termin" przed przymiotnikiem. Bez niego rozwinięte skróty w tekście brzmią dziwnie. Przykładowo https://pl.wiktionary.org/w/index.php?title=Szablon%3Aanat&type=revision&diff=6047704&oldid=4437939 KaMan (dyskusja) 18:41, 23 wrz 2017 (CEST)
- Hm, ale w polskich słownikach nie ma słówka „termin”. Proponuję najpierw ustalić a potem zmieniać. Pozdrawiam, --SolLuna dyskusja 18:56, 23 wrz 2017 (CEST)
- W polskich słownikach nie są też te skróty rozwijane do dwóch (a czasem nawet czterech słów) z których oba są innymi częściami mowy. Moje wcześniejsze takie zmiany miały zatwierdzane wersje przejrzane więc wydawało mi się że jest przyzwolenie i że to dobry kierunek. Skoro są wątpliwości to się wstrzymam, a w razie czego szybko wycofam. KaMan (dyskusja) 19:29, 23 wrz 2017 (CEST)
- Rozumiem. Zob. [3]. Pozdrawiam, --SolLuna dyskusja 19:52, 23 wrz 2017 (CEST)
- Zatwierdzałem pierwsze edycje z błędnego przekonania, że już gdzieś widziałem cząstkę „termin” i inne warianty – jeżeli wykaz WS:SKR stosunkowo wiernie odzwierciedla stan aktualny, to byłem w błędzie. Oznacza to też, że aktualny uzus (z wyjątkami) to właśnie konstrukcja „rzeczownik, przymiotnik”, wbrew proponowanym zmianom. Bez wnikania w adekwatność słowa „termin” zauważę, że rodzina szablonów {{skrót}} przyjmuje czwarty, opcjonalny parametr – dodatkowy opis, niewyświetlany na stronie po rozwinięciu skrótów. Przykładowo kwalifikator {{książk}}, wewnętrznie zakodowany jako
{{skrót|książk.|książkowy|Aneks:Skróty używane w Wikisłowniku#K|książkowy styl}}- po najechaniu kursorem wyświetla „książkowy – książkowy styl”, natomiast na stronie po naciśnięciu na „Rozwiń skróty” – wyłącznie „książkowy” (dowód: książk.). Można by zbadać przydatność tego parametru. Pozdrawiam, Peter Bowman (dyskusja) 22:05, 23 wrz 2017 (CEST)
- Rozumiem. Zob. [3]. Pozdrawiam, --SolLuna dyskusja 19:52, 23 wrz 2017 (CEST)
- W polskich słownikach nie są też te skróty rozwijane do dwóch (a czasem nawet czterech słów) z których oba są innymi częściami mowy. Moje wcześniejsze takie zmiany miały zatwierdzane wersje przejrzane więc wydawało mi się że jest przyzwolenie i że to dobry kierunek. Skoro są wątpliwości to się wstrzymam, a w razie czego szybko wycofam. KaMan (dyskusja) 19:29, 23 wrz 2017 (CEST)
Wobec wątpliwości wycofuje się z wprowadzonych zmian. KaMan (dyskusja) 17:27, 28 wrz 2017 (CEST)
rodzaj męskozwierzęcy
Wycofałem wczoraj z mieszanymi uczuciami edycję anonimowego Wikipedysty, który w haśle Krak (pot. «Kraków») zmienił rodzaj tego rzeczownika z następującym opisem: „rodzaj rzeczownika (z męskozwierzęcy(?) na męski”. Przyznam, że to przymiotnik „męskozwierzęcy” strasznie mi rani uszy. To skojarzenie mężczyzny ze zwierzęciem, trącące Freudem. Okropne, w dodatku pewnie nawet seksistowskie. Mało tego, określenie jest trochę mylące, bo — wbrew nazwie — według modelu męskozwierzęcego odmieniają się nie tylko zwierzęta. Próbowałem sprawdzić, czy jest to określenie powszechnie uznane i przyjęte wśród językoznawców. Okazuje się, że nie jest. Zamiennie używa się też określeń: „rodzaj męski nieosobowy żywotny” lub krócej „rodzaj męskożywotny”. Wiem, że dawno temu nazewnictwo rodzajów było już dyskutowane w Barze. Skończyło się na zasadzie konsensusu i przyjęciu nazewnictwa już wcześniej najczęściej używanego w Wikisłowniku. Nie chciałbym burzyć całkowicie tych ustaleń, dlatego sugeruję, czy nie warto byłoby dopisywać zamienić dotychczasowy „rodzaj męskozwierzęcy” na „rodzaj męskożywotny (męskozwierzęcy)”, natomiast „rodzaj męskorzeczowy” na „rodzaj męskonieżywotny (męskorzeczowy)”? Albo też w wersji — bez nawiasów. Zapraszam do dyskusji. Sankoff64 (dyskusja) 15:56, 2 paź 2017 (CEST)
- Jakiś czas temu proponowałem ujęcie tych objaśnień w dymku na wzór mechanizmu działającego obecnie na frazach: #Dymek informacyjny i rzeczowniki rodzaju męsko-X. Licząc, że czytelnik najedzie kursorem na tytuł, powinien otrzymać pełniejszy opis wraz z prostym przykładem odmiany. Peter Bowman (dyskusja) 21:00, 3 paź 2017 (CEST)
- @Sankoff64: Nie wiem, skąd u Ciebie wniosek, że nie jest to określenie powszechnie przyjęte. Wiem, że używa go ISJP i że pojawia się nieraz w poradni językowej PWN-u. Skojarzenia z Freudem wydają mi się natomiast mocną nadwrażliwością. Nie widzę potrzeby robienia rewolucji w tej kwestii, bardzo podoba mi się natomiast Peterowy pomysł dymków. (@Peter Bowman. Szkoda, żem wcześniej nie zauważył tej propozycji w barze). Swoją drogą – jakiś czas temu – chyba na zlocie zimowym – zastanawiałem się nad możliwością dodania takich dymków do nagłówków sekcyj z -imami, które dla wielu czytelników brzmią tajemniczo. Może i ten pomysł byśmy rozważyli? Pozdrawiam, PiotrekDDYSKUSJA 22:14, 5 paź 2017 (CEST)
- @PiotrekD: Zaglądałem do archiwum Baru, gdzie czytałem wątek: „Rodzaje męskie”. Przeczytałem tam, że w wyszukiwarce Google (3.04.2011) męskożywotny miał przewagę nad męskozwierzęcym. Teraz jest odwrotnie, ale sami jako Wikisłownik mieliśmy na to walny wpływ. Nazewnictwo naukowe nie zostało do końca ujednolicone. W publikacjach spotyka się różne określenia tych samych pojęć. Zobaczcie, co się dzieje ostatnio z kwalifikowaniem liczebników jako podrodzaju przymiotników. Co do wrażenia estetycznego wywoływanego przez wyraz „męskozwierzęcy” wypowiedział się np. Mirosław Bańko: nazwy są konwencjonalne (zwłaszcza rodzaj męskozwierzęcy budzi opór niektórych osób, wolą one etykietę męskożywotny) [4]. Podkreślę też jeszcze raz, że określenie „męskozwierzęcy” może być mylące. Odmiana męskożywotna jest typowa dla odmiany zwierząt, ale istnienie też ogromna liczba wyrazów mających ten rodzaj, ale nie będących nazwami zwierząt np. nazwy grzybów, jednostek monetarnych, gwiazdozbiorów; wyrazy typu: trup, fiut, burgund, cherubin, cymbergaj, durian i cała masa innych. Co do pomysłu z dymkami, może warto byłoby pokazać jakiś przykład, żeby to naocznie zobaczyć? Sankoff64 (dyskusja) 08:35, 6 paź 2017 (CEST)
- Nie mam zdania co do nazewnictwa, byłbym jednak ostrożny z rosnącym przenoszeniem interfejsu do dymków. Użycie ekranów dotykowych dynamicznie rośnie a tam dymki nie działają. KaMan (dyskusja) 13:31, 6 paź 2017 (CEST)
formy fleksyjne przyimków
Zastanawiam się, czy przyimki aby na pewno są nieodmiennymi częściami mowy. Moje wątpliwości wynikają z tego, że raz mówi się w piątek a raz mówi się we wtorek. Lub o ile mówi się od Ciebie, to w innym przypadku mówi się ode mnie. Nie mniej formy ode albo we nie są formami podstawowymi i jako takie nie powinny stanowić samodzielnych haseł (tak jak imiesłowy). Czy wobec tego można uznać, że przyimki kończące się na spółgłoskę są odmienne? (oczywiście wtedy takie przyimki miałyby 2 przypadki) Superjurek (dyskusja) 11:37, 10 paź 2017 (CEST)
- Na pewno nie jest to odmiana przez przypadki. Wybór "w" albo "we" zależy nie od przypadku rzeczownika, tylko od wymowy początku następnego słowa. Normalnie należałoby odnieść się do definicji pojęć, jak "odmienność" i sprawdzić doświadczalnie, jak dane słowo się zachowuje. Polonistyka nie jest jednak nauką ścisłą, bardziej od definicji liczy się autorytet profesora, który powtarza po swoim profesorze. Poloniści mają wskutek tego pewne zasady wykute w kamieniu od czasu gramatyk łacińskich, które niezbyt się nadawały do opisu polszczyzny. Wyróżniają deklinację, koniugację, a inne zmiany form podstawowych wyrazów to już nie jest fleksja, tylko luźne relacje między niezależnymi wyrazami w formie podstawowej, jak np. czysta para aspektowa czasowników lub zdrobnienia. Tym samym w każdej gramatyce przeczytasz że "przyimek jest nieodmienny", inne stwierdzenie to herezja. Podobnie nie jest uważana za ósmy przypadek stara forma celownika (czym jest "polsku" w "po polsku", albo "ojcowsku" w "po ojcowsku"?), jak również pewne konstrukcje, które w angielskim są osobnym czasem ("Mam od tygodnia sprzedany samochód") w polskich gramatykach nie są uważane za realne zjawisko. Zresztą, nawet gdyby uznać "ode" i "we" za jakąś odmianę "od" i "w", to byłyby to formy nieregularne i jako takie miałyby rację bytu jako osobne hasła. Olaf (dyskusja) 15:24, 10 paź 2017 (CEST)
- Jeszcze jedno – wydaje mi się, że akurat wymiana "od" na "ode" oraz "w" na "we" nie jest zjawiskiem gramatycznym tylko fonetycznym. A więc nie będzie to odmiana (fleksja) tylko raczej oboczność fonetyczna, która znalazła odzwierciedlenie i w zapisie. Tym samym "we" i "ode" będą formami przyimków "w" oraz "od", ale nie są to formy fleksyjne, tylko raczej oboczności fonetyczne, jak wymiana "-s" na "-es" w liczbie mnogiej niektórych słów angielskich. I w ten sposób przyimki mogą mieć różne formy, pozostając nieodmienne. :-) Olaf (dyskusja) 15:37, 10 paź 2017 (CEST)
polskie czasowniki dwuaspektowe
Stosujemy wersje:
- dokonany i niedokonany
- dokonany lub niedokonany
Pewnie też się znajdą w odwrotnej kolejności (niedokonany i/lub dokonany). Co sądzicie, żeby to zmienić na "dwuaspektowy"? Zmienić to również na liście dozwolonych i zrobić nową kategorię dla takich czasowników. Znalazłem listę, wygląda na to, że ich pula jest dość ograniczona. // user:Azureus (dyskusja) 03:48, 27 paź 2017 (CEST)
- Ja jestem za. Olaf (dyskusja) 08:20, 27 paź 2017 (CEST)
- Będzie jednolicie, także - za. Sankoff64 (dyskusja) 10:31, 27 paź 2017 (CEST)
- dwuaspektowe są tylko te z "i". Te z "lub" są jednoaspektowe. Tak przynajmniej wynika z encyklopedii. KaMan (dyskusja) 14:58, 27 paź 2017 (CEST)
- Jak to rozumiecie? Czyli mogą być:
- czasownik dwuaspektowy
- czasownik dokonany jednoaspektowy
- czasownik niedokonany jednoaspektowy
- ?? // user:Azureus (dyskusja) 18:07, 27 paź 2017 (CEST)
- raczej
- tylko dokonany
- tylko niedokonany
- dokonany i niedokonany czyli dwuaspektowy
- dokonany lub niedokonany czyli jednoaspektowy
- tak ja rozumiem zapis w Wikipedii. Pozostaje problem czy i oraz lub są u nas wstawione poprawnie KaMan (dyskusja) 18:15, 27 paź 2017 (CEST)
- raczej
- Jak to rozumiecie? Czyli mogą być:
liczebniki czy przymiotniki?
Proponuję w trzech różnych słownikach (USJP, WSJP i SGJP) sprawdzić, jak jest część mowy wyrazu pierwszy. U nas jest to oczywiście liczebnik porządkowy. Czy jednak jest to takie oczywiste? Otóż w każdym z tych uznanych i współczesnych źródeł „pierwszy”, „drugi”, „trzeci” są to przymiotniki. W USJP określono część mowy jeszcze dokładniej jako «przymiotnik odliczebnikowy». Przytoczę komentarz autorów „Wielkiego słownika języka polskiego” opracowanego przez Instytut Języka Polskiego PAN: w gramatyce tradycyjnej, do dziś wykładanej w szkołach, wyrazy takie jak trzeci, piąty, ósmy nazywano liczebnikami porządkowymi. Uznanie ich za przymiotniki wynika z przyjęcia w naszym słowniku, w ślad za naukowymi opracowaniami językoznawczymi, klasyfikacji opierającej się na cechach składniowych i fleksyjnych wyrazów. Wyrazy te odmieniają się przez przypadek, liczbę i rodzaj, czyli tak samo jak np. dobry, zły, mądry i dlatego przypisuje im się aktualnie status przymiotnika [5]. Problem ewentualnej zmiany nazewnictwa nie ogranicza się tylko do liczebników porządkowych (dawnych?), ale także liczebników wielorakich, mnożnych i wielokrotnych - wszystkie te wyrazy należałoby traktować jako przymiotniki.
Co zatem z tym robimy. Zmieniamy? Wypadałoby zamieścić jakieś objaśnienia w uwagach. Spróbuję zrobić jakąś próbną edycję dotyczącą tych kwestii. Skala zmian byłaby dość duża, bo objęłaby zapewne nie tylko język polski. Proszę o uwagi. Pozdrawiam. Sankoff64 (dyskusja) 16:54, 27 paź 2017 (CEST)
- Milczenie naszej społeczności, uważam za milczący akcept dla tych propozycji. Sankoff64 (dyskusja) 12:09, 28 paź 2017 (CEST)
- @Sankoff64: Może połączyć obie informacje w nagłówku? Tak jak łączymy skrótowiec, i rzeczownik, np. skrótowiec, rzeczownik, rodzaj żeński. Ja bym proponował taką opcję. Pozdrawiam, PiotrekDDYSKUSJA 12:28, 28 paź 2017 (CEST)
- @PiotrekD: Byłoby to łączeniem dwóch konwencji i dwóch sprzecznych pojęć. Trzeba się umówić: albo kontynuujemy tradycję nazewniczą, którą przerabialiśmy w szkołach, albo stosujemy nowszą terminologię, już ugruntowaną, bo stosowaną w większości nowych publikacji. Poza tym trochę te nagłówki byłyby przeładowane. Wyglądałoby to np. tak: przymiotnik odliczebnikowy, dawniej liczebnik porządkowy. Byłby kłopot z działaniem botów, bo np. czwarty byłby dodawany w pokrewnych dwa razy: raz jako przymiotnik, raz jako liczebnik, a przecież to ten sam wyraz. Sankoff64 (dyskusja) 12:42, 28 paź 2017 (CEST)
- Oj, czy nie opuściłeś czegoś w cytacie? Z tego wynikaloby, ze prawidlowym pytaniem do zdania Chory przyszedl do lekarza. byloby Jaki przyszedl do lekarza?, bo te (dotychczas rzeczowniki odprzymiotnikowe, a od teraz przymiotniki?) tez spelniaja powyzsze kryteria :) Milego weekendu!--EdytaT (dyskusja) 12:35, 28 paź 2017 (CEST)
- Chciałbym dodać, że stosowanie wtedy pojęcia liczebnik główny stanie się zbędne (skoro wszystkie inne liczebniki są przymiotnikami) - wystarczy liczebnik. Zadam jeszcze pytanie: skoro liczebnik główny odmienia się przez przypadek, to może jest to rzeczownik, należący do grupy wyjątków, bo mający tylko jedną liczbę (jeden - lp, pozostałe - lm)? Zniknie też problem, czy słowa takie jak "zero", "tysiąc", "milion", to liczebniki, czy rzeczowniki - będą to rzeczowniki odmieniające się przez liczbę. Tyle z punktu widzenia laika. Zetzecik (dyskusja) 14:22, 28 paź 2017 (CEST)
- No nie, jest jeszcze liczebnik zbiorowy (czworo) i ułamkowy (pół), może też inne. KaMan (dyskusja) 14:27, 28 paź 2017 (CEST)
- Kilka lat temu Olaf uzyskał odpowiedź z poradni językowej w kwestii klasyfikacji wyrazu „zerowy” – rezultatem było zakwalifikowanie „zero” i pozostałych z ww. listy jako rzeczowniki: Dyskusja:zerowy. Pozdrawiam, Peter Bowman (dyskusja) 23:12, 29 paź 2017 (CET)
@Sankoff64: Jakiś czas temu wprowadziłeś nowy system, dodając w uwagach informację w stylu „W dawniejszej terminologii wyraz był uważany za liczebnik porządkowy, za traktowaniem go jako przymiotnika przemawia m.in. fakt, że odmienia się przez przypadki, liczby i rodzaje”. Myślę, że zamiast słowa „dawniejszej” lepiej byłoby użyć słowa „klasycznej”, biorąc pod uwagę fakt, że ten system ciągle jest obecny (jako jedyny zresztą) w polskim szkolnictwie innym niż szkolnictwo wyższe, a u nas wiążący się z tym słowem kwalifikator daw., z którym czytelnik mógłby owo słowo skojarzyć, ma dość konkretne znaczenie i wskazuje pewną odległość czasową jednak. Co o tym sądzisz (i inni dyskutanci)? Pozdrawiam, PiotrekDDYSKUSJA 21:52, 28 gru 2017 (CET)
- @PiotrekD: Nie mam nic przeciwko temu. Sankoff64 (dyskusja) 07:51, 29 gru 2017 (CET)
czasowniki dokonane / niedokonane oraz pary aspektowe
z Tablicy Ogłoszeń (28 października)
Uwaga: reorganizacja czasowników posiadających aspekt dokonany i niedokonany. Prośba o chwilowe wstrzymanie się od edycji tego typu par aspektowych, dopóki bot automatycznie nie dostosuje wyglądu haseł szablonu obowiązującego. Krokus (dyskusja) 14:09, 28 paź 2017 (CEST)
- a czy zarys tej reorganizacji został przedstawiony w barze i uzyskał akceptację społeczności? Czy chodzi o czasowniki dwuaspektowe obecnie już w barze dyskutowane? KaMan (dyskusja) 14:14, 28 paź 2017 (CEST)
- W ubiegłym roku odbyła się dyskusja WS:Bar/Archiwum 18#Problemy z przekierowaniami (twardymi i miękkimi). Zmiany są konieczne, by umożliwić edytorom rozbudowę tego typu haseł - chodzi przede wszystkim o dobór adekwatnych przykładów (np. przy pomocy: opracowanego już narzędzia [6]) oraz tłumaczeń. Dotychczasowa struktura uniemożliwiała to. Wszelkie zmiany odnośnie niuansów lub wyglądu można poddać dyskusji i w łatwy sposób zmienić we wszystkich tego typu hasłach. Na razie hasła wyglądają różnie i należy je ujednolicić. Pozdrawiam Krokus (dyskusja) 14:43, 28 paź 2017 (CEST)
- wstawienie hurtem szablonu do weryfikacji niczemu nie pomoże KaMan (dyskusja) 14:46, 28 paź 2017 (CEST)
- Trwają prace, to nie jest ostateczny efekt pracy bota. Stąd prośba o wstrzymanie się od edycji. Ludmiła Pilecka ⇒ dyskusja 14:56, 28 paź 2017 (CEST)
- tylko pytanie czy rzeczywiście trzeba botować, jak nie będzie chętnych do poprawiania to tylko się choinka z haseł zrobi, nie lepiej zrobić listę takich haseł dla chętnych? jestem przeciwny masowej zmianie, wolałbym efekt dyskusji na konferencji poznać w barze i dopiero po akceptacji wszystkich (choćby milczącej) podejmować edycje. KaMan (dyskusja) 15:17, 28 paź 2017 (CEST)
- Chciałem nadmienić, że zaledwie kilka tygodni temu zwróciłem uwagę @Krokus z powodu okazanego podejścia do nieustalonych jeszcze zasad, zachęcając ją do wznowienia dyskusji: Specjalna:Diff/6059271, Specjalna:Diff/6058054/6059008. Nie kojarzę, by w ostatnich miesiącach kiedykolwiek poruszono tę kwestię, teraz jednak osiągnięcie konsensusu traktuje się jak fakt dokonany (?). Chętnie poznałbym kulisy podjęcia tych decyzji ze strony organizatorów oraz planowany dalszy przebieg (do ustalenia?). Pozdrawiam, Peter Bowman (dyskusja) 02:05, 30 paź 2017 (CET)
- tylko pytanie czy rzeczywiście trzeba botować, jak nie będzie chętnych do poprawiania to tylko się choinka z haseł zrobi, nie lepiej zrobić listę takich haseł dla chętnych? jestem przeciwny masowej zmianie, wolałbym efekt dyskusji na konferencji poznać w barze i dopiero po akceptacji wszystkich (choćby milczącej) podejmować edycje. KaMan (dyskusja) 15:17, 28 paź 2017 (CEST)
- Trwają prace, to nie jest ostateczny efekt pracy bota. Stąd prośba o wstrzymanie się od edycji. Ludmiła Pilecka ⇒ dyskusja 14:56, 28 paź 2017 (CEST)
- wstawienie hurtem szablonu do weryfikacji niczemu nie pomoże KaMan (dyskusja) 14:46, 28 paź 2017 (CEST)
- W ubiegłym roku odbyła się dyskusja WS:Bar/Archiwum 18#Problemy z przekierowaniami (twardymi i miękkimi). Zmiany są konieczne, by umożliwić edytorom rozbudowę tego typu haseł - chodzi przede wszystkim o dobór adekwatnych przykładów (np. przy pomocy: opracowanego już narzędzia [6]) oraz tłumaczeń. Dotychczasowa struktura uniemożliwiała to. Wszelkie zmiany odnośnie niuansów lub wyglądu można poddać dyskusji i w łatwy sposób zmienić we wszystkich tego typu hasłach. Na razie hasła wyglądają różnie i należy je ujednolicić. Pozdrawiam Krokus (dyskusja) 14:43, 28 paź 2017 (CEST)
- w haśle przywitać bot ominął znaczenie (2.1) KaMan (dyskusja) 16:06, 28 paź 2017 (CEST)
- Wiemy, pracujemy nad tym :). Nostrix (dyskusja) 16:07, 28 paź 2017 (CEST)
- skoro te edycje są nadzorowane przez edytorów z uprawnieniami redaktora, to edycje bota mogłyby być przejrzane. W tej chwili przyrasta kolejka do przejrzenia. KaMan (dyskusja) 16:34, 28 paź 2017 (CEST)
- Wiemy, pracujemy nad tym :). Nostrix (dyskusja) 16:07, 28 paź 2017 (CEST)
Ostatni wpis w dyskusji sprzed półtora roku zawiera następujące stwierdzenie: „zaproponuj zatem jakieś reguły, dotyczące tego, co powinno przestać być miękkim przekierowaniem ([…]), następnie trzeba to będzie porównać z obecnymi zasadami (ogólnymi i dotyczącymi nazewnictwa stron), a w końcu przeprowadzić głosowanie.” — Ale administratorzy w Wikisłowniku mogą robić, co się im żywnie podoba, nie mają zamiaru się na nic ani na nikogo oglądać. I jest jak u Barei: nie mamy pańskiego płaszcza i co pan nam zrobi?. Nic, absolutnie nic… Maitake (dyskusja) 19:28, 28 paź 2017 (CEST)
- To, co widać było w OZ, to dopiero pierwszy etap kilkuetapowego procesu. PiotrekDDYSKUSJA 22:49, 28 paź 2017 (CEST)
Chciałem tylko zwrócić uwagę, że przy czasownikach zwrotnych powinno to wyglądać tak:
''czasownik zwrotny niedokonany '''doprasowywać się''''' ({{dk}} [[doprasować się]])
Problem w tym, że po zmianach w szablonie {{niedokonany od}} gdzie mam wstawić pogrubiony tekst doprasowywać się w haśle doprasowywać? // user:Azureus (dyskusja) 19:41, 28 paź 2017 (CEST)
- Czy któryś z oponentów ma zastrzeżenia co do zasadniczej ideii aby wszystkie czasowniki miały pełnoprawną definicję? Marek Mazurkiewicz (dyskusja) 14:34, 30 paź 2017 (CET)
- Ja nie, ale tak samo uważam że wszystkie czasowniki powinny mieć wymowę i odmianę, ale nie przyszłoby mi do głowy botować / bombardować hasła prośbami o ich wstawienie. Listy braków dobrze działają przy obecnej liczbie aktywnych edytorów. KaMan (dyskusja) 15:18, 30 paź 2017 (CET)
Pytanie do osób stojących za kulisami tego przedsięwzięcia - macie w planach wycofać te edycje, czy ma wisieć taki półprodukt? // user:Azureus (dyskusja) 00:15, 31 paź 2017 (CET)
- O Azereusie, te "spiski, knowania [oraz inne... hiperonimy, hiponimy, meronimy, holonimy - mam nadzieję że w twoim wypadku stosowane w zależności od tego, czy chcesz zawęzić, poszerzyć, ewentualnie rozmyć znaczenie słów] miały miejsce na dostępnym dla wszystkich już tworzących Wikisłownik zlocie... i o wybacz efendi, że dla mnie osobiste uczestnictwo w zlocie nie wiązało się tylko ze zwykłym chce mi się lub nie [7] (wpis: 20:12, 30 gru 2016), ale z ogromną kumulacją obowiązków po zlocie. Pozdrawiam Krokus (dyskusja) 22:34, 31 paź 2017 (CET)
- A tak już zupełnie na marginesie: to po zauważeniu przez rzekomych spiskowców, niegodziwców, szarlatanów itp. :) faktu, iż zmiany nie miały flagi bota (ludzie są - w moim mniemaniu na szczęście omylni - a tych rzekomo bez skazy i zarazy pozostawię bez komentarza...), mieliśmy i nadal mamy związane ręce przez co najmniej siedem dni [od niezwłocznego, po stwierdzeniu jego braku, zgłoszenia wniosku o przyznanie flagi bota], wyłącznie dlatego, iż nasze intencje absolutnie nie były pokrętne! I niech żyje generalnie liberum veto, skutki stosowania którego na gruncie polskim w sumie już ćwiczyliśmy..[3 razy emotka: :)], ale w końcu tworzymy - mam nadzieję - coś unikatowego i tarcia na płaszczyźnie uzusu / konwencji / praktyki są niezniknione ... Pozdrawiam Krokus (dyskusja) 23:14, 31 paź 2017 (CET)
- W porządku, nie będziemy powoływali komisji śledczej;) Pytanie tylko - co teraz? Ma tak zostać na "co najmniej siedem dni"? Ni przypiął, ni przyłatał. Może lepiej to wycofać, dopracujcie sobie to na spokojnie, przedstawcie pod osąd w Barze i wtedy zrobicie to jeszcze raz, może z innym botem (bo jeśli dobrze liczę, to Masti nie dostanie flagi w tej chwili). // user:Azureus (dyskusja) 23:40, 31 paź 2017 (CET)
- A tak już zupełnie na marginesie: to po zauważeniu przez rzekomych spiskowców, niegodziwców, szarlatanów itp. :) faktu, iż zmiany nie miały flagi bota (ludzie są - w moim mniemaniu na szczęście omylni - a tych rzekomo bez skazy i zarazy pozostawię bez komentarza...), mieliśmy i nadal mamy związane ręce przez co najmniej siedem dni [od niezwłocznego, po stwierdzeniu jego braku, zgłoszenia wniosku o przyznanie flagi bota], wyłącznie dlatego, iż nasze intencje absolutnie nie były pokrętne! I niech żyje generalnie liberum veto, skutki stosowania którego na gruncie polskim w sumie już ćwiczyliśmy..[3 razy emotka: :)], ale w końcu tworzymy - mam nadzieję - coś unikatowego i tarcia na płaszczyźnie uzusu / konwencji / praktyki są niezniknione ... Pozdrawiam Krokus (dyskusja) 23:14, 31 paź 2017 (CET)
- Rozumiem, że 7 dni (obecnie już mniejszy), to straszny / nierozsądny termin! :) Azereusie, przecież doskonale wiesz, że jak chcesz uderzyć pasa, to kij zawsze się znajdzie, a by zlinczować kogoś wystarczy zwykły paproch z tego przysłowiowego kija..., bo przecież od dawna rzesze ludzi przyciągała możliwość rozpętania trzeciej wojny domowej, zrobienia z igły widły oraz prawdopodobieństwo, że może: będzie zadyma / będzie się działo / będzie zabawa i inne tego typu atrakcje :) Pozdrawiam Krokus (dyskusja) 00:51, 1 lis 2017 (CET)
- Nie chcę demonizować, ale myślę, że wbrew pozorom ten projekt odwiedza całkiem sporo czytelników i mogą poczuć się trochę zmieszani widząc coś takiego. // user:Azureus (dyskusja) 00:57, 1 lis 2017 (CET)
- O Azereusie, te "spiski, knowania [oraz inne... hiperonimy, hiponimy, meronimy, holonimy - mam nadzieję że w twoim wypadku stosowane w zależności od tego, czy chcesz zawęzić, poszerzyć, ewentualnie rozmyć znaczenie słów] miały miejsce na dostępnym dla wszystkich już tworzących Wikisłownik zlocie... i o wybacz efendi, że dla mnie osobiste uczestnictwo w zlocie nie wiązało się tylko ze zwykłym chce mi się lub nie [7] (wpis: 20:12, 30 gru 2016), ale z ogromną kumulacją obowiązków po zlocie. Pozdrawiam Krokus (dyskusja) 22:34, 31 paź 2017 (CET)
Drodzy oponenci @Peter Bowman @Maitake @Azureus @KaMan @Zu! Jeżeli chodzi o zadanie tego konkretnego bota, to polega ono na:
- I etap
- po pierwsze: wyłapaniu czasowników dokonanych i niedokonanych z quasi-definicją
- po drugie: ujednoliceniu sekcji zawierającej definicję na tyle, by móc przy pomocy prostych zmian w szablonie dokonywać zmian, a nie jak teraz być zmuszonym robić to przy pomocy bota. (i żeby zaraz mi tu nie krzyczano o spisku i podstępnej chęci przeforsowania potajemnie uknutego jedynie słusznego wyglądu tego szablonu, to od razu podkreślam: wygląd szablonów dla czas dok. i niedok. jest rozwojowy i wszelkie pomysły, co do jego wyglądu są mile widziane!). Na tym etapie jest ważne, by była możliwość nieskomplikowanego, niepracochłonnego oraz szybkiego wprowadzenia lepszych pomysłów w życie. Taki jest cel ujednolicenia. Obecnie nasze definicje dla czasowników wyglądają następująco: a) z definicją (kilka wariantów) patrz np.: zapuszczać (czasownik niedokonany)/ robić (czasownik przechodni niedokonany (dk. zrobić)), b) z niby-definicją patrz np.: zapuścić (czasownik przechodni)--> nasza propozycja wstawienie szablonu czasownik przechodni aspekt niedokonany od: [[]]; patrz np obrabować.
- II etap (i tu bardzo prosiłabym o wsparcie i burzę mózgów, bo jest kilka możliwości oraz wątpliwości, jak będzie lepiej)
- przy pomocy bota utworzenie definicji dla haseł, które do tej pory de facto jej nie miały, na podstawie hasła z pary aspektowej. Wiadomo, że takie hasła będą wymagały ręcznej obróbki. Powstaje pytanie, co zrobić z niedopracowanymi hasłami, czy zostawić je w przestrzeni głównej z szablonem dopracować (mi ta idea nie bardzo leży), czy tak, jak kiedyś - moim zdaniem bardzo pomysłowo i tej idei jestem zwolenniczką - zrobił @Olaf z hasłami niemieckimi utworzonymi przy pomocy bota, wyrzucić te czasowniki z przestrzeni głównej na podstronę i dopiero po zatwierdzeniu przez edytora, sukcesywnie przenosić je do przestrzeni głównej.
To tak pokrótce o rzekomym spisku. PS @Azureusie, nie wiemy ile takich pseudodefinicji mamy, bo bot nie ukończył pracy, a do tej pory żadna ich lista - o ile mi wiadomo - nie istniała. A jeżeli chętny jesteś ręcznie edytować te 200 stron, które wskazują, że jest przynajmniej aż tyle haseł bez definicji, to trzymam za słowo, bo projekt jest na najlepszej drodze do zakończenia się fiaskiem:) Pozdrawiam Krokus (dyskusja) 11:09, 1 lis 2017 (CET)
- Nie wiem jak wypowiedzi innych, ale mam wrażenie, że moja została źle zrozumiana. Nie miałem na myśli żadnego spisku, tylko rozedrganą realizację. PBbot edytuje mnóstwo stron w przestrzeni glównej z różnymi poprawkami (mniejszymi, większymi), jednak nikt do Petera pretensji nie ma, że nie napisał o tym w Barze. // user:Azureus (dyskusja) 11:37, 1 lis 2017 (CET)
- @Azureusie, proszę przejrzyj plan, jak coś jest niejasne to postaram się doprecyzować i zastanów się, czy rzeczywiście warto wstrzymywać pracę i pozostawić w zawieszeniu sprawę czasowników, de facto bez definicji, których istnienie w przestrzeni głównej jest niezgodne z podstawową regułą odnośnie tworzenia nowych haseł, a mianowicie, że hasło musi posiadać przynajmniej definicję, bo rozumiem, że dla wszystkich tworzących Wikisłownik jest jasne i oczywiste, że nazwanie aspektu czasownika oraz podanie pary aspektowej, nie jest jego definicją. Na dobrą sprawę hasła te powinny być skasowane, ale szkoda pracy edytorów, którzy pododawali już np,: frazeologizmy, czasem podali poprawną odmianę (zamiast np.: niepoprawnych przekierowań do odmiany czas. z pary aspektowej, która jest zupełnie inna), słowem w niektórych czasownikach pouzupełniali to, co się dało, bez posiadania definicji. Bez prawdziwej definicji nie sposób przecież dobrać chociażby odpowiedni przykład, czy też dodać tłumaczenia, dla języków rozróżniających aspekty - moim zdaniem są to fakty oczywiste i nie wymagają głosowania. Jeżeli jednak oburzona społeczność potrzebuje głosowania typu: Czy sformułowanie: czasownik dokonany jest definicją, to można takowe urządzić, jeżeli chcemy się pobawić i z głosowań urządzić farsę. To, że realizacja jest rozedrgana spowodowane jest wymogiem czekania 7 dni na przyznanie flagi bota, który już jest napisany i jest w stanie zrealizować etap I. Potem utworzyć listę czasowników bez definicji i przenieść je na podstronę. W tym momencie będzie można już samemu ręcznie dopisywać definicję, jeżeli jest takowa wola, lub poczekać na wygenerowanie definicji przez bota. W międzyczasie mogą trwać dyskusje np. na temat wyglądu nagłówka / szablonu, jeżeli ktoś ma w tym zakresie jakiekolwiek propozycje to zapraszam! Przy ujednoliconym wyglądzie możemy dyskutować do upadłego, bo jak tylko zapadnie ostateczna na dany moment decyzja, to wprowadzenie jej w życie będzie błyskawiczne. Pozdrawiam Krokus (dyskusja) 12:26, 1 lis 2017 (CET)
- Właśnie ten plan jest rozedrgany. To właśnie zarzucam Wam głosując przeciwko fladze bota - bierzecie pod uwagę tylko jeden typ haseł (ten, który akurat chcecie zmienić) i nikt nie pomyślał na przykład o tym (zwłaszcza operator bez znajomości projektu), że chociażby szablon {{dokonany od}} jest stosowany nie tylko w polskim. O takie niuanse mi chodzi. // user:Azureus (dyskusja) 12:39, 1 lis 2017 (CET)
- @Azureusie, proszę przejrzyj plan, jak coś jest niejasne to postaram się doprecyzować i zastanów się, czy rzeczywiście warto wstrzymywać pracę i pozostawić w zawieszeniu sprawę czasowników, de facto bez definicji, których istnienie w przestrzeni głównej jest niezgodne z podstawową regułą odnośnie tworzenia nowych haseł, a mianowicie, że hasło musi posiadać przynajmniej definicję, bo rozumiem, że dla wszystkich tworzących Wikisłownik jest jasne i oczywiste, że nazwanie aspektu czasownika oraz podanie pary aspektowej, nie jest jego definicją. Na dobrą sprawę hasła te powinny być skasowane, ale szkoda pracy edytorów, którzy pododawali już np,: frazeologizmy, czasem podali poprawną odmianę (zamiast np.: niepoprawnych przekierowań do odmiany czas. z pary aspektowej, która jest zupełnie inna), słowem w niektórych czasownikach pouzupełniali to, co się dało, bez posiadania definicji. Bez prawdziwej definicji nie sposób przecież dobrać chociażby odpowiedni przykład, czy też dodać tłumaczenia, dla języków rozróżniających aspekty - moim zdaniem są to fakty oczywiste i nie wymagają głosowania. Jeżeli jednak oburzona społeczność potrzebuje głosowania typu: Czy sformułowanie: czasownik dokonany jest definicją, to można takowe urządzić, jeżeli chcemy się pobawić i z głosowań urządzić farsę. To, że realizacja jest rozedrgana spowodowane jest wymogiem czekania 7 dni na przyznanie flagi bota, który już jest napisany i jest w stanie zrealizować etap I. Potem utworzyć listę czasowników bez definicji i przenieść je na podstronę. W tym momencie będzie można już samemu ręcznie dopisywać definicję, jeżeli jest takowa wola, lub poczekać na wygenerowanie definicji przez bota. W międzyczasie mogą trwać dyskusje np. na temat wyglądu nagłówka / szablonu, jeżeli ktoś ma w tym zakresie jakiekolwiek propozycje to zapraszam! Przy ujednoliconym wyglądzie możemy dyskutować do upadłego, bo jak tylko zapadnie ostateczna na dany moment decyzja, to wprowadzenie jej w życie będzie błyskawiczne. Pozdrawiam Krokus (dyskusja) 12:26, 1 lis 2017 (CET)
- Moje uwagi:
- „(...) by móc przy pomocy prostych zmian w szablonie dokonywać zmian, a nie jak teraz być zmuszonym robić to przy pomocy bota” oraz „(...) ważne, by była możliwość nieskomplikowanego, niepracochłonnego oraz szybkiego wprowadzenia lepszych pomysłów w życie” – masz na myśli zapewne wstawienie szablonu {{Definicja do sprawdzenia}} w miejscu przyszłej definicji. Jednak bot Mastiego edytuje przede wszystkim nagłówki znaczeń (fragment obok czasownik (nie)przechodni, Specjalna:Diff/6068559). Tu nie ma mowy o prostym dokonywaniu zmian, w razie zmiany zdania konieczne będzie ponowne przebotowanie wszystkiego.
- Co z wyjątkami, czy ktoś to przemyślał: Specjalna:Diff/6068429/6068742?
- Dlaczego nie utworzono nowych szablonów zamiast ingerowania w obecny wygląd {{dokonany od}} i {{niedokonany od}}, zmieniając strukturę HTML wygenerowanego tekstu (porównaj dowolne edytowane hasło MastiBota przed i po).
- Cały etap II jest na razie wielką niewiadomą: czy wziął ktoś pod uwagę, że takie zadanie może być niewykonalne dla automatu? Kto to wdroży, w jaki sposób, kiedy? Owszem, można skorzystać z rozwiązania półautomatycznego, jak zwykłem nazywać udział bota w przerzucaniu zmian naniesionych ręcznie (np. na osobnej podstronie lub w edytorze tekstowym) do przestrzeni głównej, lecz...
- „jeżeli chętny jesteś ręcznie edytować te 200 stron” – ...może się skończyć na tym, że edytorzy i tak będą musieli ręcznie wprowadzać i zatwierdzać setki definicji. Powracając więc do poprzedniego punktu, prosiłbym o konkrety. Spostrzeżenia Azureusa w Barze o półprodukcie wydają się na razie trafne.
- Wspomniałaś w innym miejscu o automacie Alkamida do wstawiania przykładów. Czy uwzględniono ewentualne konflikty nowej struktury pola znaczeń z obecnie działającymi botami?
- „(...) czasowników, de facto bez definicji, których istnienie w przestrzeni głównej jest niezgodne z podstawową regułą odnośnie tworzenia nowych haseł” – osobista opinia oraz błędna interpretacja zasad spisanych w WS:NAZ. „moim zdaniem są to fakty oczywiste i nie wymagają głosowania” – dlaczego Twoje zdanie liczy się więcej niż 80 KB dyskusji w WS:Bar/Aspekt czasownika (i późniejszych wątków)?
- „(...) tak, jak kiedyś (...) zrobił @Olaf z hasłami niemieckimi utworzonymi przy pomocy bota, wyrzucić te czasowniki z przestrzeni głównej na podstronę i dopiero po zatwierdzeniu przez edytora, sukcesywnie przenosić je do przestrzeni głównej” – Olaf tworzył gotowe szkice na osobnej podstronie, niczego nie wyrzucał z przestrzeni głównej.
- „(...) nie wiemy ile takich pseudodefinicji mamy, bo bot nie ukończył pracy” – takie statystyki sporządza się przed botowaniem, żeby wiedzieć, na czym się stoi.
- Peter Bowman (dyskusja) 13:10, 1 lis 2017 (CET)
- @Azureusie, nie wiem w czym tkwi problem, i w czym zmienia to sytuację, przecież w innych językach aspektowych, każdy czasownik też musi posiadać definicję, by móc dodawać chociażby adekwatne przykłady, a bot też będzie miał za zadanie ich ujednolicenie (lista języków aspektowych została przez osoby biorące udział w zlocie odnaleziona). Poza tym trzeba zobaczyć ile dokładnie haseł bez definicji jest w poszczególnych językach, na razie gołym okiem widać, że opłaca się pisać bota dla języka polskiego, który będzie generować definicje na podstawie czasownika, który już ją posiada. Jeżeli w jakimś z języków będą ze dwa hasła, to szybciej będzie zrobić to ręcznie:). Z linkujących wynika, że do 1500 haseł korzysta z samego szablonu dokonany od [[8]] i na oko przeważają linki do haseł polskich; z szablonu dokonany od[9] korzysta do 150 stron, również z przewagą haseł polskich. Na razie nie wiadomo ile dokładnie takich haseł bez definicji jest (bot na razie nawet nie przeleciał przez wszystkie polskie czasowniki, przecież nie wszystkie linki prowadzą do haseł). Wpierw trzeba uporać się z czasownikami w języku polskim. Krokus (dyskusja) 13:58, 1 lis 2017 (CET)
- OK, z mojej strony koniec. Mamy protokół rozbieżności - Ty (i większość glosujących "za") uważacie, że jest ok, ja uważam, że jest źle. Pozdrawiam, // user:Azureus (dyskusja) 14:03, 1 lis 2017 (CET)
- @Azureusie OK, uważasz że jest źle, to powiedz jak to naprawić! Do tej pory nie zauważyłam żadnej propozycji konstruktywnej. Wytykać błędy jest łatwo, gorzej przedstawić propozycję ich naprawy. Krokus (dyskusja) 14:16, 1 lis 2017 (CET)
- Wycofać. Potem bujajmy się w Barze - jak to mamy w zwyczaju - przez miesiąc, dwa, zrewidujemy Wasz plan, zobaczymy co wyjdzie. Nie będę się udzielał, bo nie znam się na języku, ale są tu ludzie, którzy mają jakieś pojęcie i na pewno coś doradzą. // user:Azureus (dyskusja) 14:19, 1 lis 2017 (CET)
- @Azureusie, nie wiem w czym tkwi problem, i w czym zmienia to sytuację, przecież w innych językach aspektowych, każdy czasownik też musi posiadać definicję, by móc dodawać chociażby adekwatne przykłady, a bot też będzie miał za zadanie ich ujednolicenie (lista języków aspektowych została przez osoby biorące udział w zlocie odnaleziona). Poza tym trzeba zobaczyć ile dokładnie haseł bez definicji jest w poszczególnych językach, na razie gołym okiem widać, że opłaca się pisać bota dla języka polskiego, który będzie generować definicje na podstawie czasownika, który już ją posiada. Jeżeli w jakimś z języków będą ze dwa hasła, to szybciej będzie zrobić to ręcznie:). Z linkujących wynika, że do 1500 haseł korzysta z samego szablonu dokonany od [[8]] i na oko przeważają linki do haseł polskich; z szablonu dokonany od[9] korzysta do 150 stron, również z przewagą haseł polskich. Na razie nie wiadomo ile dokładnie takich haseł bez definicji jest (bot na razie nawet nie przeleciał przez wszystkie polskie czasowniki, przecież nie wszystkie linki prowadzą do haseł). Wpierw trzeba uporać się z czasownikami w języku polskim. Krokus (dyskusja) 13:58, 1 lis 2017 (CET)
- @Peter Bowman
- Ad.8 Tak, @Olaf mógł tworzyć gotowe szkice na osobnej podstronie, bo tych haseł, z tego co pamiętam, jeszcze nie było w przestrzeni głównej, a nasze już są! Co proponujesz w takim razie? Zdublować hasła i tworzyć szkice na osobnej stronie, a potem co? Podmieniać? A jak w między czasie ktoś coś uzupełni, to niby jak to uwzględnić w szkicach? Napisać kolejnego bota, który będzie to kontrolować? W sumie pewnie się też da, tylko kto go napisze? Krokus (dyskusja) 14:41, 1 lis 2017 (CET)
- @Krokus: dlatego nalegam, by takie ustalenia padły przed rozpoczęciem prac. Zauważ, że przerzucenie do podstrony też nic nie da, jeżeli ktoś akurat w międzyczasie utworzy ponownie stronę opisującą dany czasownik. Owszem, takie rzeczy trzeba kontrolować, i masz ku temu przykład w projekcie WS:Dodawanie przykładów Alkamida (szczegółów implementacji teraz nie pamiętam, ale bot tu edytuje samo pole przykładów, nie ruszając reszty) albo niedokończoną jeszcze weryfikację typografii przypisów mojego autorstwa (1. automat wprowadza zmianę według schematu, zapisując ją w osobnej bazie danych; 2. użytkownik przegląda, poprawia w razie potrzeby i zatwierdza; 3. bot przerzuca do WS, bacząc na konflikty). KaMan opisał podobny proces w poniższym komentarzu (15:00, 1 lis 2017 (CET)). Peter Bowman (dyskusja) 23:10, 1 lis 2017 (CET)
- Ad.8 Tak, @Olaf mógł tworzyć gotowe szkice na osobnej podstronie, bo tych haseł, z tego co pamiętam, jeszcze nie było w przestrzeni głównej, a nasze już są! Co proponujesz w takim razie? Zdublować hasła i tworzyć szkice na osobnej stronie, a potem co? Podmieniać? A jak w między czasie ktoś coś uzupełni, to niby jak to uwzględnić w szkicach? Napisać kolejnego bota, który będzie to kontrolować? W sumie pewnie się też da, tylko kto go napisze? Krokus (dyskusja) 14:41, 1 lis 2017 (CET)
- A ja nadal nie rozumiem czemu potrzebny jest etap I. Przecież można od razu przejść do automatu importującego definicje z drugiego aspektu do poprawy na podstronie, poprawić ręcznie, oznaczyć zakończenie poprawy i wstawić botem gotowy tekst do hasła. Wszystkie te elementy i tak trzeba będzie zrobić (choć pytania Petera o to kto i kiedy są zasadne) więc po co robić precedens z szablonem WSTAW ZNACZENIE! Poza tym, Krokusie, wypadałoby do dyskusji zaprosić użytkownika odpowiedzialnego za większość ostatnich polskich haseł z list braków w tym wiele czasowników. KaMan (dyskusja) 15:00, 1 lis 2017 (CET)
- @KaMannie, dyskusja jest otwarta i nikt nikomu nie broni wziąć w niej udziału!!! Jeżeli posiadasz wiedzę, że użytkownik ten potrzebuje specjalnego zaproszenia, to czemu tego nie zrobiłeś lub też o nim wspominając nie zrobiłeś tego przez ping? Krokus (dyskusja) 15:31, 1 lis 2017 (CET)
- @KaMannie, bez I etapu (jak też przy zastosowaniu Twojej propozycji) z haseł bez definicji zniknie informacja o dokonaności lub niedokonaności oraz odsyłacz do czasownika tworzącego parę aspektową, temu ma właśnie zapobiec pierwszy etap, by niczego, co już zostało zrobione nie stracić. Nie wiem nawet, czy technicznie byłaby możliwe za jednym botowaniem jednoczesne przeniesienie informacji a w inne miejsce, a w miejsce informacji a wstawienie informacji b. Jakoś mi się nie wydaje, by za jednym przebiegiem było to możliwe, ale ja informatykiem nie jestem. Logiczne są dwie operacje wpierw przeniesienie informacji, którą chcemy zachować, potem w puste miejsce wstawienie definicji, czyli dwa przebiegi bota. Krokus (dyskusja) 16:26, 1 lis 2017 (CET)
- Ad.9 Szacunkową ilość zmian nie więcej niż 1650 podałam, nic nie stoi na przeszkodzie by jeszcze dziś ktoś napisał bota, który dokładnie to sprawdzi, najlepiej z podziałem na języki:). Nic nie stoi na przeszkodzie, tylko jak zwykle pewnie będzie chętnych brak, a i tak to nie zmienia faktu, że trzeba ujednolicić i stworzyć definicję dla przynajmniej tak na oko min. 1300 haseł. Wiem, że to nie jest dokładny rachunek, ale nie wiem w czym dokładna statystyka miałaby niby być pomocna na pierwszym etapie, chociaż widzę jej zastosowanie na drugim: może pomóc w ocenie, czy warto dla innych języków pisać już teraz bota generującego definicję. Krokus (dyskusja) 15:22, 1 lis 2017 (CET)
- @Krokus: vide pkt 5. Gdyby nie brak uprawnień MastiBota, stanęlibyśmy przed faktem, że kilkaset haseł nagle czeka na obróbkę bez wytyczonego planu (pkt 4.). Ponadto chodzi mi jeszcze o porządek: automatycznego botowania nie wykonuje się w ciemno bez nadzoru (WS:BOT#Zalecenia, pkt 5.). Peter Bowman (dyskusja) 23:21, 1 lis 2017 (CET)
Rozmówców proszę o rozróżnienie tematu głosowania nad uprawnieniami i tematu czasowników. Jest wątek w Barze Wikisłownik:Bar#aspektowe. // user:Azureus (dyskusja) 14:46, 1 lis 2017 (CET)
- Tak à propos dzisiejszego święta, ja postawię i zapalę świeczkę na próbie uporządkowania aż, a zarazem tylko maximum 1650 haseł - bo tu chociażby linkowanie do szablonu było pomocne. I @Azureus w sumie ma rację najlepiej jest - jak to leciało?: Wycofać. Potem bujajmy się w Barze - jak to mamy w zwyczaju - przez miesiąc, dwa, zrewidujemy Wasz plan [bo, przecież dostajemy wynagrodzenie ;) - che, che, a nie jesteśmy woluntariuszami - a szanowna społeczność [tu chyba bardziej: rada nadzorcza :) raczy ocenić, lub nie, gotowy projekt, ale sama nie wysili się na nic konstruktywnego, bo w sumie nie należny to do jej obowiązków:) --> skutek: krytyka będzie opierać się na pretensjach / urażonych ambicjach, a nie argumentach rzeczowych - czyli propozycjach, jak to konkretnie zrobić lepiej!] zobaczymy co wyjdzie. Problem w tym, że się bujamy prawie 10 lat, a struktura oparta na wolontariacie rozrasta się (chodzi przede wszystkim o ilość zmiennych, które trzeba uwzględnić podczas pisania bota)... [rozumiem, że to mały pikuś, bo mamy aż nadmiar chętnych do pisania botów :)] Ale hola.. to dopiero wierzchołek góry lodowej, bo to tak naprawdę mały problem..:):):)! Niech oponenci powiedzą (opracują plan do krytyki i wieszania psów, bo idealnych planów przecież nie ma), i powiedzą, jak ugryźć tego typu słowa de facto bez definicji jak: [[10]] i o zonk!:) nie ma tu linkujących:). To tak na zachętę :) Pozdrawiam i życzę owocnego bujania się w barze, ja z przyjemnością zajrzę tam, jak pojawi się jakikolwiek plan (za kilka miesięcy, rok, lata...) i powytykam niedoskonałości :), w sumie i tak największą frajdę sprawia mi po prostu tworzenie pojedynczych haseł:) Krokus (dyskusja) 20:28, 1 lis 2017 (CET)
ciąg dalszy
Edycje bota zostały wycofane, podobnie jak zmiany w szablonach {{dokonany od}} oraz {{niedokonany od}} i te na stronie zasad WS:Nazewnictwo. Szablon {{Definicja do sprawdzenia}} wciąż ma transkluzje (link), lecz nie chcę ingerować w działanie AlkamidBota. Peter Bowman (dyskusja) 22:14, 5 lis 2017 (CET)
- Wróciliśmy więc do punktu wyjścia. Wypada rzecz szybko doprowadzić do finału. Zaproponować nowe rozwiązania, przegłosować i wprowadzić do naszych zasad nazewnictwa i zasad tworzenia haseł. Znowu obowiązuje dawna formuła, że w przypadku czystych par aspektowych w językach słowiańskich tworzymy jedno pełne hasło i drugie, będące tylko przekierowaniem. Problem w tym, że metoda ta nigdy nie działała dobrze. Wątpię np. czy ktoś przed utworzeniem danego hasła sprawdzał w Korpusie PWN, słowniku frekwencyjnym, innych źródłach leksykograficznych itd. która forma jest częstsza. Mam wrażenie, że tworzył hasło dla formy niedokonanej i nie zawracał sobie głowę sprawdzaniem frekwencyjności. O problemach z pomieszaniem aspektów, z synonimami, antonimami, z dodawaniem przykładów już pisano wielokrotnie.
- Rozwiązania są dwa. Pierwsze, to całkowicie skasować rozdział dotyczący czystych par aspektowych. Hasła dotyczące tych czasowników tworzone byłyby na zasadach ogólnych. Drugie rozwiązanie polegałoby na nowym zapisaniu zasad (nie podejmuję się jednak ubierać tego w słowa) z uwzględnieniem dwóch reguł: zasady jednoaspektowości i zasady „lustrzanego odbicia”. Zasada jednoaspektowości polegałaby na tym, że w haśle dotyczącym czasownika w danym aspekcie przykłady, synonimy, antonimy i pozostałe -imy, frazeologizmy, tłumaczenia na języki słowiańskie byłyby wprowadzane tylko w tym aspekcie, którego dotyczy hasło. Zasada „lustrzanego odbicia” polegałaby na zastosowaniu jednolitego szablonu dla czasowników każdego aspektu (tak np. jak w hasłach odchodzić i odejść). Hasło z danej czystej pary aspektowej powinno więc swój lustrzany odpowiednik w drugim aspekcie, żadna z form nie byłaby faworyzowana, żadna nie byłaby „gorsza”. Oczywiście pozostaną pewne różnice, wynikające choćby z tego, że niektóre znaczenia występują czasami tylko w jednym aspekcie. Jest jeszcze pytanie o sens istnienia szablonu dotyczącego tłumaczeń na języki, które nie rozróżniają aspektów, ale to byłby już drobiazg. Rzecz trzeba doprowadzić do końca tak, aby nie pozostał niesmak z powodu ostatniego sporu. Pozdrawiam. Sankoff64 (dyskusja) 09:05, 6 lis 2017 (CET)
- Nadal uważam że obecnie jest niewygodnie. Hasła powinny być pełne dla obu aspektów. Marek Mazurkiewicz (dyskusja) 22:37, 6 lis 2017 (CET)
- Hmm.. Widzę, że bujanie się w barze weszło w "stazę":) Gdzie to bezbłędne :) rozwiązanie? Gdzie są te nowe pomysły? Lepsze propozycje? Mini wysiłek?.. Cokolwiek?.. Jak nikt nie ma pomysłu nowego, wspaniałego, no i oczywiście;) nieomylnego:) - to niech ulepszy chociaż ten co był - w sumie tego oczekiwałam, na to liczyłam - po ludzku liczyłam na współpracę?! W sumie projekt zakłada dzielenie się wiedzą, a nie roszczeniowe nastawienie:) Pozdrawiam Krokus (dyskusja) 20:14, 10 lis 2017 (CET)
- Ta ironia ma pomóc? Póki co brak zmian jest lepszy niż to co Wy wyczarowaliście... // user:Azureus (dyskusja) 20:29, 10 lis 2017 (CET)
- Hmm.. Widzę, że bujanie się w barze weszło w "stazę":) Gdzie to bezbłędne :) rozwiązanie? Gdzie są te nowe pomysły? Lepsze propozycje? Mini wysiłek?.. Cokolwiek?.. Jak nikt nie ma pomysłu nowego, wspaniałego, no i oczywiście;) nieomylnego:) - to niech ulepszy chociaż ten co był - w sumie tego oczekiwałam, na to liczyłam - po ludzku liczyłam na współpracę?! W sumie projekt zakłada dzielenie się wiedzą, a nie roszczeniowe nastawienie:) Pozdrawiam Krokus (dyskusja) 20:14, 10 lis 2017 (CET)
- Pewnie.. - ja wciąż wierzę, że poza liberum veto, ktoś będzie chciał zrobić coś:) ... Krokus (dyskusja) 22:35, 10 lis 2017 (CET)
- Ja również wierzę, że poza ironizowaniem można do serca przyjąć głosy dyskutantów i jeszcze raz zrobić to co było źle zaprojektowane. Nie było żadnego liberum veto, były wyraźnie przedstawione problemy (od Petera w punktach) i jeśli tylko jest wola, to można ponownie podejść do problemu omawiając kolejne kroki w barze. Od samego początku podnoszona była nieokreśloność planu, szczególnie drugiej fazy, ale pierwsza też była projektowana ad hoc, co przy takiej dużej liczbie modyfikowanych haseł i przy takiej roli czasowników w języku nie powinno mieć miejsca. Nie mniej zacząć trzeba by od uzgodnienia zmiany na stronie nazewnictwa (zdaje się że to zostało wycofane) bo od tego zależą wszystkie zmiany. Jak tylko będzie nowy plan to strona z zadaniami dla botów już jest i można kontynuować. Ważne jest tylko by mieć dobry i zaakceptowany przez społeczność plan. KaMan (dyskusja) 14:56, 11 lis 2017 (CET)
- Pewnie.. - ja wciąż wierzę, że poza liberum veto, ktoś będzie chciał zrobić coś:) ... Krokus (dyskusja) 22:35, 10 lis 2017 (CET)
- @Azureus miał rację:) Bujamy się... - ja dodam z przekąsem - ponad miesiąc - bez najmniejszej pracy szarych komórek nad uporządkowaniem czasowników:). Wiem, że plan może nie był bez skazy i zarazy, ale do tej pory spora część czasowników (zapewne ta wartościowa, czyli posiadająca minimum jedną definicję w jednym z aspektów, zostałby przynajmniej przekonwertowana na jednolity wygląd. Może czasowniki bez definicji w żadnym z aspektów zostałyby w zawieszeniu i koś musiałby napisać definicję przynajmniej w jednym aspekcie... ale wielka szkoda / krzywda by się stała, jeżeliby czasowników bez definicji nie było w słowniku, skoro i tak nie wiadomo co one oznaczają - - proszę wybaczyć mi sarkazm:) Wiem jedno: ujednolicenie usprawniłoby ewentualne masowe poprawki estetyczne, a przede wszystkim merytoryczne (i chociaż do tej pory w tej kwestii nie padły żadne kontente rozwiązania lub chociażby propozycje, poza nie, źle, nie tak, liberum weto, to mam nadzieję, że każdy z redagujących ma świadomość faktu, że język jest zjawiskiem żywym, i że jak nie skostniałe byłyby nasze poglądy, to język będzie się zmieniał i dostosowywał:) i to do potrzeb użytkowników języka. Ktokolwiek wie / przemyślał jak usprawnić to, co było ponoć było nie tak? Krokus (dyskusja) 17:25, 14 gru 2017 (CET)
wyrazy supletywne
Utworzyłem próbną wersję indeksu dla wyrazów supletywnych: Wikipedysta:Azureus/Indeks:Polski - Wyrazy supletywne. Jeśli taki indeks zdobyłby uznanie redaktorów, to zapraszam do tworzenia podobnych indeksów dla pozostałych języków. Czujcie się swobodnie wprowadzając poprawki do powyższej wersji. // user:Azureus (dyskusja) 23:42, 28 paź 2017 (CEST)
- Wydaje mi się że nie mamy w hasłach miejsca na podanie w prost takiej informacji (kategoria?) Może warto rozważyć podawanie? Marek Mazurkiewicz (dyskusja) 21:32, 29 paź 2017 (CET)
- @Marek Mazurkiewicz: niektóre hasła już mają odpowiedni dopisek w nagłówku znaczeń, zob. „ludzie”. Peter Bowman (dyskusja) 23:17, 29 paź 2017 (CET)
- @Peter Bowman czy nie lepszy byłby szablon generujący kategorię? Marek Mazurkiewicz (dyskusja) 18:54, 1 lis 2017 (CET)
- @Marek Mazurkiewicz: opcje to kategoria (automatycznie wstawiana przez szablon) albo lista wygenerowana w postaci indeksu/aneksu. Pierwsze podejście postępuje „od dołu”: najpierw tworzymy strony kategorii, dostosowujemy szablony, a potem edytorzy edytują albo tworzą odpowiednie hasła. Drugie zaś zaczyna się „od góry”: można najpierw utworzyć listę, a potem załatwiać czerwone linki (nieregularne formy fleksyjne za WS:NAZ). Na razie drugie podejście wydaje mi się wygodniejsze, automatyzacja szablonów może nastąpić później (na chwilę obecną trudno przewidzieć ostateczny kształt i działanie mechanizmu, czy będą wyjątki itd.). Pozdrawiam, Peter Bowman (dyskusja) 20:30, 1 lis 2017 (CET)
- @Peter Bowman czy nie lepszy byłby szablon generujący kategorię? Marek Mazurkiewicz (dyskusja) 18:54, 1 lis 2017 (CET)
- @Marek Mazurkiewicz: niektóre hasła już mają odpowiedni dopisek w nagłówku znaczeń, zob. „ludzie”. Peter Bowman (dyskusja) 23:17, 29 paź 2017 (CET)
Słownikowe ciekawostki
Co sądzicie o utworzeniu strony meta zawierającej listę słówek "ciekawostkowych", to znaczy takich, które są a) nietypowe, mają nietypowe znaczenia, pisownię i inne takie, b) nie znajdzie się ich w papierowych czy innych elektronicznych słownikach, np. susz konferencyjny, c) są słowami z języków obcych, które mają zaskakujące znaczenia. Coś na wzór wikipediowych Wikiciekawostek. Strona miałaby charakter promocyjny. Sam mógłbym zacząć ją tworzyć, ale trudno mi z głowy od razu wysypać całą listę takich słówek, więc potrzebna by była pomoc. Nostrix (dyskusja) 10:05, 31 paź 2017 (CET)
- Mi przychodzi do głowy tylko to że nazwa kwark pochodzi od twarogu. KaMan (dyskusja) 10:18, 31 paź 2017 (CET)
- Coś takiego już mamy. Na stronie głównej po kliknięciu frazy: „Tworzymy niezwykły słownik” otwiera się strona zawierająca odsyłacze do konkretnych stron Wikisłownika. Zmiany tej strony ostatnio sprowadzają się do aktualizowania danych liczbowych przez bot Alkamida. Oczywiście nie wyklucza to ani tego, że można byłoby tę stronę rozbudować, ani też stworzenia oddzielnej strony ze zmieniającymi się co pewien czas ciekawostkami. Któryś z administratorów musiałbym to regularnie aktualizować, bo ciekawostka przestaje być ciekawa, jeśli „wisi” na stronie dłuższy czas. Na początku tak ad hoc zgłaszam frazeologizm zapędzić w kozi róg, w którym dodałem właśnie ciekawą - jak sądzę - etymologię. Pozdrawiam. Sankoff64 (dyskusja) 10:59, 31 paź 2017 (CET)
- Bardzo ciekawy pomysł. Zgłaszam etymologię słowa konszabelant, znaczenie (1.2) w haśle wrzesień, mnogość znaczeń słowa przenosić, różne warianty wymowy słowa gęś, etymologię zwrotu babie lato, angielskie honorificabilitudinitatibus, japońskie 青 (tradycyjny japoński nie odróżnia niebieskiego i zielonego). Kilka lat temu funkcjonowała inicjatywa Wikisłownik:Słowo tygodnia, można też spróbować przejrzeć tamte słowa, może będzie coś ciekawego. Olaf (dyskusja) 12:01, 31 paź 2017 (CET)
- Przeklejam mój komentarz z wątku #Facebook (permalink), podrzuciłem wtedy garść pomysłów:
- Przychodzi mi na myśl odratowanie porzuconych projektów WS:Słowo tygodnia i WS:Temat miesiąca, dawniej reklamowanych na naszej stronie głównej. Inne ciekawostki: uwagi o błędnym użyciu słów (Specjalna:Linkujące/Szablon:źle), wpisy w poradniach i blogach językowych odnoszące się do naszych haseł oraz konfrontacja ich niekiedy odmiennych zdań ({{Obcy język polski}}, {{PoradniaPWN}}, {{PoradniaUJ}}, {{PoradniaUŚ}} itd.), reaktywacja WS:Czego nie zna wujek Google, okazyjne cytaty na podstawie WS:Dodawanie przykładów z linkiem do omawianego hasła, nowe indeksy tematyczne i portale, powielanie wpisów z WS:Wikisłownik w mediach (też do odratowania). Innym źródłem na dobieranie ciekawych (?) haseł mogłyby być codzienne statystyki oglądalności (Wikipedysta:AlkamidBot/statystyka/wizyty lub nowe narzędzie [11]). Pozdrawiam, Peter Bowman (dyskusja) 12:44, 5 lip 2016 (CEST)
- Pozdrawiam, Peter Bowman (dyskusja) 13:50, 31 paź 2017 (CET)
- Trochę nie na temat Peter ;). Chodziło mi o stronkę meta na Wikisłowniku, która mogłaby potem ewentualnie służyć do celów promocyjnych, ale głównym celem byłaby jednak rozrywka dla społeczności i dzielenie się ciekawymi informacjami o języku/językach. Nie musiałaby być linkowana na stronie głównej, raczej gdzieś z np. Wikisłownik:Dlaczego Wikisłownik. Przykłady podane przez Olafa to jest właśnie to, co miałem na myśli :). Nostrix (dyskusja) 15:17, 31 paź 2017 (CET)
- Wikisłownik:Wikiciekawostki - zachęcam do edytowania ;). Nostrix (dyskusja) 14:02, 3 lis 2017 (CET)
bezosobnik, odsłownik
Czy to prawda że formę zakończoną na -no/-to można po prostu nazwać jednym słowem "bezosobnik", zamiast "forma bezosobowa czasu przeszłego"; zaś "rzeczownik odczasownikowy" można zastąpić słowem "odsłownik"? Obie definicje występują na Wikipedii. Oczywiście traktuję tu Wikipedię jako wskazówkę, bo zapewne te same nazwy wystąpią też w źródłach zewnętrznych. Superjurek (dyskusja) 19:51, 31 paź 2017 (CET)
- Pierwsze widzę. SJP PWN nie zawiera tych słów. Chrzęszczyboczek (dyskusja) 20:11, 31 paź 2017 (CET)
- @Chrzęszczyboczek Śmiem zaprzeczyć, że SJP PWN nie zawiera takich słów, a oto dowód. Superjurek (dyskusja) 23:09, 31 paź 2017 (CET)
- A jakie to hasło w Słowniku Języka Polskiego PWN? Chrzęszczyboczek (dyskusja) 00:14, 1 lis 2017 (CET)
- @Superjurek: To nie jest hasło w internetowym SJP PWN (takie nie istnieje), tylko wypowiedź z ichniej poradni internetowej. Pozdrawiam, PiotrekDDYSKUSJA 21:52, 1 lis 2017 (CET)
- @Chrzęszczyboczek Śmiem zaprzeczyć, że SJP PWN nie zawiera takich słów, a oto dowód. Superjurek (dyskusja) 23:09, 31 paź 2017 (CET)
USJP nie podaje definicji słów bezosobnik i odsłownik. Pojęciami tymi posługuje się SGJP. Zetzecik (dyskusja) 20:40, 1 lis 2017 (CET)
- Czy wobec tego istnieje możliwość wprowadzenia tych słów do szablonów odmiany czasowników polskich? Superjurek (dyskusja) 13:43, 4 lis 2017 (CET)
- Mam mieszane uczucia. Z pewnością terminy te są krótsze, ale i tak najdłuższe nazwy w tym infoboksie mają imiesłowy. Obecne warianty są natomiast bardziej zrozumiałe dla czytelników niezorientowanych w specjalistycznej terminologii gramatycznej (tak specjalistycznej, że nie ma jej w zwykłych słownikach). Dlatego jestem przeciw. Pozdrawiam, PiotrekDDYSKUSJA 13:54, 4 lis 2017 (CET)
- WSJP także używa pojęcia bezosobnik, natomiast zamiast odsłownika używa się tam terminu gerundium. Sankoff64 (dyskusja) 13:02, 2 lis 2017 (CET)
tłumaczenia - związki wyrazowe
Nie kojarzę, żeby była podobna dyskusja.
Jak linkować tłumaczenia wielowyrazowe haseł jednowyrazowych tak, żeby nowe strony utworzone z tych tłumaczeń nie były uznane za zwykłe kolokacje? Na przykład hasło bombonierka? Jeśli ktoś utworzy hasło "box of chocolates" to będzie źle? // user:Azureus (dyskusja) 13:11, 4 lis 2017 (CET)
- Linkowałbym osobno, ewentualnie przekierowując do głównego elementu frazy:
[[box|box of chocolates]]Peter Bowman (dyskusja) 14:24, 4 lis 2017 (CET)
odbieranie uprawnień redaktora
Czy komuś poza mną przechodził ten temat przez myśl? Macie jakieś przemyślenia w tej kwestyji? // user:Azureus (dyskusja) 19:08, 12 lis 2017 (CET)
- @Azureus: Nie wiem, o czym konkretnie teraz myślisz, jednak wydaje mi się, że jeśli redaktor popełnia wielokrotnie te same istotne błędy i nie reaguje na uwagi doń skierowane bądź wręcz reaguje na nie agresją oraz nie zamierza się poprawiać, sprawa więc tego wymaga, to administratorzy powinni móc mu zabrać uprawnienia, aby dokonywane przezeń edycje były oznaczane jako wymagające sprawdzenia (bo już wcześniej tego sprawdzenia wymagały de facto). To tak ogólnie mówiąc. Może będę w stanie więcej napisać, jeśli określisz dokładniej, o co chodzi. Pozdrawiam, PiotrekDDYSKUSJA 19:21, 12 lis 2017 (CET)
- Byłoby mi łatwiej, gdybym trafił na kogoś, kto ma podobne do moich przemyślenia na temat niektórych edytorów... // user:Azureus (dyskusja) 19:24, 12 lis 2017 (CET)
- Trudno mi odpowiedzieć na taką wiadomość, szczerze mówiąc, tym bardziej nie wiem, o czym konkretnie myślisz. Których to edytorów? (Próbowałem wysłać Ci w tej sprawie mejl, ale nie masz podanego adresu). PiotrekDDYSKUSJA 19:32, 12 lis 2017 (CET)
- Byłoby mi łatwiej, gdybym trafił na kogoś, kto ma podobne do moich przemyślenia na temat niektórych edytorów... // user:Azureus (dyskusja) 19:24, 12 lis 2017 (CET)
Uprawnienia redaktora ma teraz 91 kont. Czy ktoś z aktywnych dziś edytorów kojarzy nick "Coreana" albo "Vesihiisi"? Bo ja nie. To są jakieś zmienione nazwy użytkowników albo przejęte konta? Wiele nicków, których nie było widać od 2-3 lat. Jak bardzo przez ten czas zmienił się sposób edytowania? Może warto by to ocenić i trochę tę listę prześwietlić? // user:Azureus (dyskusja) 01:20, 14 lis 2017 (CET)
Potencjalne formy supletywne lub deklinacja niektórych zaimków
Witam, chciałbym poruszyć jeszcze raz jeden temat, który nie daje mi spokoju.
Czy przy założeniu, że donikąd kiedyś było frazą do nikąd można by uznać wyraz nikąd za D. lp słowa nigdzie? Łatwo wyprowadzić następujący schemat:
- M. lp (kto? co?) Warszawa → do D. lp (kto? czego?) Warszawy
- M. lp (kto? co?) gdzie → do D. lp (kto? czego?) kąd
- M. lp (kto? co?) gdzieś → do D. lp (kto? czego?) kądś
- M. lp (kto? co?) wszędzie → do D. lp (kto? czego?) wsząd
- M. lp (kto? co?) nigdzie → do D. lp (kto? czego?) nikąd
Kolejne 3 pytania, to:
- Czy wobec tego wszystkie te słowa da się odmienić przez wszystkie przypadki?
- Czy nie jest to przypadkiem nie dopełniacz, a raczej allatyw (do kogo? do czego?) lub ablatyw (z kogo? z czego?)?
- Czy znane są jakieś źródła poruszające ten temat?
Superjurek (dyskusja) 22:58, 2 gru 2017 (CET)
- @Superjurek: Eh. Po pierwsze, jakem już pisał, bar to nie forum dyskusyjne.
- Po drugie – zaimki pełniące funkcję przysłówków nie odmieniają się przez przypadki.
- Po trzecie – zaimki takie mają w językach słowiańskich budowę modułową, w tym przypadku do-ni-k-ąd (do- – konkretny kierunek, -ni- – zaprzeczenie, -k- – zaimek pytajny (dziś zaimki z tą cząstką są używane też jako relacyjne), -ąd/-ęd, skrócone z -ędy zachowanego w kędy – ogólnie kierunek (czasowy lub przestrzenny; piszę z pamięci i z lekkim zajrzeniem do dwu słowników etymologicznych, mogę się mylić)). Porównaj sobie s-k-ąd, s-t-ąd, do-t-ąd albo też cały komplet t-aki, j-aki, dawne si-aki czy staropolskie k-aki (zachowane w rosyjskim – какой). Zgaduję, że o to pytasz.
- Po czwarte – więcej o tym możesz przeczytać w słownikach etymologicznych, opracowaniach gramatyki historycznej i innych źródłach o historii języka.
- Po piąte – ablatywu nie było już w późniejszym języku prasłowiańskim, allatywu natomiast w ogóle w języku praindoeuropejskim, o ile wiem. PiotrekDDYSKUSJA 00:39, 3 gru 2017 (CET)
- @PiotrekD Gorąco dziękuję za wyczerpującą odpowiedź! Pozdrawiam Superjurek (dyskusja) 14:35, 3 gru 2017 (CET)
Zbieżność form Dopełniacza lp i lm
Czy wiadomo może, skąd bierze się zbieżność D. lp i D. lm? Zauważyłem bowiem, że w wielu sytuacjach następuje tendencja do używania identycznej formy dla obu tych przypadków. Dajmy na to:
- (tej) hodowli i (tych) hodowli zamiast (tych) hodowl (a warto zwrócić uwagę, że forma ta utrzymała się w przymiotniku hodowl-any)
- (tej) alei i (tych) alei zamiast (tych) alej (a warto zwrócić uwagę, że forma ta utrzymała się w przymiotniku alej-owy)
- (tej) cukierni i (tych) cukierni zamiast (tych) cukierń
- (tej) kontroli i (tych) kontroli zamiast (tych) kontrol (a warto zwrócić uwagę, że forma ta utrzymała się w przymiotniku kontrol-ny)
- (tej) bakterii i (tych) bakterii zamiast (tych) bakteryj (a warto zwrócić uwagę, że forma ta utrzymała się w przymiotniku bakteryj-ny)
- (tej) konstytucji i (tych) konstytucji zamiast (tych) konstytucyj (a warto zwrócić uwagę, że forma ta utrzymała się w przymiotniku konstytucyj-ny)
- (tej) dziupli i (tych) dziupli zamiast (tych) dziupl (a warto zwrócić uwagę, że forma ta utrzymała się w przymiotniku dziupl-owy) lub od biedy (tych) dziupel
Jestem wielce zdziwiony tym stanem rzeczy, skoro tym samym użytkownicy polszczyzny wybierają większą redundantność form:
- hodowli
- alei
- cukierni
- kontroli
- bakterii
- konstytucji
- dziupli;
jednocześnie decydując się na pozbawienie ich jednoznaczności (informacja o liczbie wynika z konteksktu całego wyrażenia i to też nie zawsze... np. w nazwie warszawskiego Placu Konstytucji nie wiadomo czy chodzi o Plac (tej) Konstytucji, czy o Plac (tych) Konstytucji Superjurek (dyskusja) 23:27, 2 gru 2017 (CET)
- @Superjurek: Eee… Wiesz, że nasz bar to nie forum dyskusyjne o języku? A samo używanie form z końcówką „-i” częściej niż tych z pustą wynika z tego, że w opisywanych przypadkach są prostsze w wymówieniu. PiotrekDDYSKUSJA 00:13, 3 gru 2017 (CET)
- PS: redundantny
- @PiotrekD Racz najmocniej wybaczyć moje fopa... Gdzie na przyszłość mogę takie pytania zadawać bez ryzyka złamania niepisanych reguł? Superjurek (dyskusja) 00:23, 3 gru 2017 (CET)
Rozbijanie haseł 1-wyrazowych na pojedyncze morfemy
Drodzy Wikipedyści Wikisłownika, wpadłem na kompromisowe rozwiązanie, wymagające jednak akceptacji nas wszystkich. Proponuję, aby w nagłówkach rozbijać morfemy poprzez przedzielenie ich punktorami. Konwencję taką widziałem w co po niektórych słownikach i rozwiązanie takie wydaje się zwiększać informacyjność każdego hasła 1-wyrazowego (w hasłach wielowyrazowych już i tak funkcjonuje linkowanie każdego wyrazu do haseł o tych wyrazach). W takim przypadku dajmy na to w haśle przekierowanie mielibyśmy w nagłówku 1-rzędu przekierowanie, a w nagłówku 2-rzędu prze•kier•owanie i wtedy można byłoby dorobić hasła dotyczące morfemów w języku polskim. Proszę Was o opinie. Pozdrawiam Superjurek (dyskusja) 21:09, 23 gru 2017 (CET)
- Nie uwzględniamy znaków dodatkowych w tytułach sekcji (chodzi mi tu o np. zaznaczenie akcentu w hasłach rosyjskich, makrony w łacinie itd.), takie przypadki trafiają do naprawy w Wikipedysta:PBbot/nagłówki. Punktory w takim miejscy byłyby szczególnie widoczne, poza tym nie widzę powodu, dla którego informacja stricte powiązana z etymologią miałaby zostać umieszczona w tak widocznym miejscu – od tego jest odpowiednie pole. Przypomina to ponadto sytuację morfemów esperanto, gdzie ta sama informacja, do której się odnosisz, umieszczona jest w przeznaczonym do tego polu.
- BTW czy masz włączone powiadomienia? Niedawno rewertowałem Specjalna:Diff/6100863. Trochę zastanawia wspominanie o rozwiązaniu kompromisowym, gdy alternatywą są masowe zmiany typu Specjalna:Diff/6100863, bez uprzedniej propozycji. Wesołych świąt, Peter Bowman (dyskusja) 21:29, 23 gru 2017 (CET)
Sprzeciw. Przestałyby działać linki do sekcji językowych z innych haseł. KaMan (dyskusja) 09:09, 24 gru 2017 (CET)
- Te generowane przez {{etym/link}} w postaci
hasło#hasło (język X)– owszem, jednak te wprowadzane ręcznie oraz przez skrypty jakohasło#kodpowiny działać. Peter Bowman (dyskusja) 13:21, 24 gru 2017 (CET)- Być może moje sformułowanie w postaci kompromisowego rozwiązania zabrzmiało kontrowersyjnie (arogancko), za co z góry przepraszam. Rozwiązanie zaproponowane przeze mnie jest podpatrzone z co poniektórych słowników tradycyjnych. Podział na morfemy jeśli można, to zamieszczałbym równie dobrze w sekcji etymologia, nie mniej chciałem zwrócić uwagę na temat morfemów i przyrostków jako istotny aspekt, można by wtedy bardziej analitycznie podejść do wprowadzanych przez nas haseł, a to niewątpliwie przyczyni się do głębszego rozwinięcia naszego Wikisłownika. Superjurek (dyskusja) 22:35, 26 gru 2017 (CET)
- W sekcji etymologii jest to już od dawna robione z użyciem szablonu etymn więc nie trzeba niczego zmieniać. KaMan (dyskusja) 08:08, 27 gru 2017 (CET)
- Być może moje sformułowanie w postaci kompromisowego rozwiązania zabrzmiało kontrowersyjnie (arogancko), za co z góry przepraszam. Rozwiązanie zaproponowane przeze mnie jest podpatrzone z co poniektórych słowników tradycyjnych. Podział na morfemy jeśli można, to zamieszczałbym równie dobrze w sekcji etymologia, nie mniej chciałem zwrócić uwagę na temat morfemów i przyrostków jako istotny aspekt, można by wtedy bardziej analitycznie podejść do wprowadzanych przez nas haseł, a to niewątpliwie przyczyni się do głębszego rozwinięcia naszego Wikisłownika. Superjurek (dyskusja) 22:35, 26 gru 2017 (CET)
Zdrobnienia
Zauważyłem ostatnio w swoich obserwowanych wysyp zdrobnień, np. cyberataczek, łęczaczek, wyściółczaczek. Czy to, że takie zdrobnienie można utworzyć sprawia, że takie hasło powinno istnieć? Nie wydaje się, aby były używane [12], [13], [14], [15]. Zwróciło to moją uwagę przy tej edycji (dodany dopełniacz w tombak jako tombaka). Wostr (dyskusja) 21:00, 25 gru 2017 (CET)
- Ja już od dawna opowiadam się przeciw tworzeniu haseł wyłącznie na zasadzie „bo se mogę połączyć i mi wyjdzie” i za usuwaniem haseł tego typu, które dają mało wyników w Google'u i nie są notowane w słownikach. Z mojego punktu widzenia „cyberataczek” (a szczególnie forma dopełniacza „cyberataczka”) i podobne brzmią nader komicznie. PiotrekDDYSKUSJA 21:05, 25 gru 2017 (CET)
- Pamiętaj, że zdrobnienia brzmią komicznie z definicji, ponieważ służą również do deprecjonowania, przykładowo: "Propalestyńskie anonymousy szturmują jak opętane od wczesnego ranka cele rządowe w Izraelu, ale jak dotąd te cyberataczki o kant d. potłuc." --- 84.10.92.69 (dyskusja) 16:30, 26 gru 2017 (CET)
- Popieram. Jestem przeciw tworzeniu haseł dla potencjalnych zdrobnień z zerową frekwencją. Opisujemy język a nie tworzymy go. KaMan (dyskusja) 15:40, 26 gru 2017 (CET)
- Kolejny głos za nietworzeniem takich haseł. Ming (dyskusja) 15:44, 26 gru 2017 (CET)
- Formy wołacza dla przeważającej większości rzeczowników też mają zerową frekwencję. Usuwamy je? ---- 84.10.92.69 (dyskusja) 16:49, 26 gru 2017 (CET)
- Kolejny głos za nietworzeniem takich haseł. Ming (dyskusja) 15:44, 26 gru 2017 (CET)
- Jakie kryterium przyjąć jako warunek wystarczający – obecność w SGJP/SJP? Myślę o uruchomieniu automatu dla przebadania, czy dane słowo istnieje (inna sprawa: czy jest używane). Peter Bowman (dyskusja) 15:57, 26 gru 2017 (CET)
- Za SGJP/SJP + ewentualnie kwerenda w korpusie języka. KaMan (dyskusja) 16:37, 26 gru 2017 (CET)
- Przy weryfikacji ręcznej? Wedle mnie – obecność w jakimkolwiek słowniku (potencjalnie z wyjątkiem tych o nakładzie 50 egzemplarzy czy innych takich, gdyby powstały). Przy weryfikacji automatycznej, gdyby chcieć wstępnie taką zrobić? W tym wypadku Startowy darmowy zestaw pewuenowski (SJPDor + WSO + ten ichni SJP oparty na słowniku definicyjnym sygnowanym nazwiskiem Bralczyka) i SGJP powinny wystarczyć. (Internetowy WSJP wbrew nazwie jest bardzo mały, brakuje tam nawet podstawowych zaimków, sprawdzanie tam to marnowanie własnej mocy obliczeniowej). PiotrekDDYSKUSJA 19:04, 26 gru 2017 (CET)
Jest procedura do zgłaszania haseł do usunięcia. Nic nie stoi na przeszkodzie. Pochylcie się nad poszczególnymi przypadkami i przedyskutujcie konkretne zdrobnienia. -- 84.10.92.69 (dyskusja) 16:08, 26 gru 2017 (CET)
- To tutaj tak nie działa. Dobrze wiesz, że w tym tempie tworzenia tych haseł się nie da. Musielibyśmy jedynie siedzieć na jednym wkładzie rozsianym po wielu IP i nic innego nie robić tylko googlać. Nie każdy ma tyle samo czasu na Wikisłownik. Zdrowy rozsądek obowiązuje już na etapie tworzenia haseł a obowiązek uwiarygodnienia wkładu leży w pierwszej kolejności na autorze wkładu. KaMan (dyskusja) 16:26, 26 gru 2017 (CET)
- Nie martw się, zdrowego rozsądku mi nie brakuje. Googlam wątpliwe pojęcia i ważę argumenty. 84.10.92.69 (dyskusja) 16:32, 26 gru 2017 (CET)
- Ustawiłem filtr wobec zignorowania prośby o wstrzymanie się z tworzeniem tego typu haseł. Przypomnienie: WS:WER. Peter Bowman (dyskusja) 17:17, 26 gru 2017 (CET)
Dotyczy języka Bench
Zapytanie dotyczące języka Bench
Witam Serdecznie.
Od dłuższego czasu użytkownicy i jednostki administracyjne (administrarorzy) mogący coś zrobić olewają bardzo istotny problem, który pozytywnie sprzyja rozwojowi wikisłownika. Chodzi o indeks alfabetyczny dla języka Bench oraz utworzenie strony języka a także dodawanie haseł do indeksu. Ilekroć dodawany jest wpis to zaraz zostaje on usunięty nawet wtedy kiedy jeden z użytkowników znajdzie (choć mylnie) informacje z przypisu na temat języka a dokładnie dialektu języka amharskiego "Benshu", który nie ma nic wspólnego z językiem Bench mimo, że niektóre źródła podają ścisły związek z tym językiem. Podobne nazwy określają inne języki a odróżnić to można po kodzie językowym, kraju występowania, jego pochodzenia, wymowie, alfabecie oraz pisowni. Język Bench o którym mowa wykształcił się w Azji a odmiana dialektu amharskiego w Etiopii w Afryce. Można więc przyjąć i nadmienić również opublikowane zasoby językowe w internecie, iż dialekt Benshu = Bench jest wspólną częścią języka amharskiego dlatego nie podaje się oddzielnego rozgraniczenia na amharski i Bench (jako język dialektowy języka amharskiego). Natomiast Bench jest językiem oddzielnym a nie dialektem jak to miało miejsce w przeszłości. Jeśli to możliwe proszę zainteresować się tą sprawą, w przeciwnym razie zostanie usunięte konto na Wikipedii powiązane z wikisłownikiem o nazwie: "Atvhh" a tym samym fundacja Wikimedia utraci możliwość rozwoju dla języka Bench i jeśli ktoś w przyszłości dokona jego dodania prawdopodobnie za podstawę uzna język amharski co jest błędem. Oznacza to, że Wikimedia przyczyni się do szerzenia nieprawdy i zakłamań. Wiadomość do Was została wysłana na polecenie Organizacji Atvhh CAI i to od niej zależy decyzja ostateczna dlatego bardzo proszę o jakiekolwiek zajęcie stanowiska w tej sprawie i ewentualną odpowiedź.
Brak odpowiedzi zostanie uznane za zignorowanie tej wiadomości a informacja o tym fakcie zostanie wysłana administratorowi Atvhh.
- @Atvhh: Specjalna:Diff/5501282/5514839 + Specjalna:Diff/5514853 + Specjalna:Diff/6057056 + Specjalna:Diff/6057399. Peter Bowman (dyskusja) 14:48, 7 sty 2018 (CET)
Wikidane i Wikisłownik
Cześć. Właśnie wróciłem ze Zlotu Zimowego, na którym odbyła się bardzo ważna dla Wikisłownika prezentacja. Zachęcam do zapoznania się ze slajdami i nagraniem audio. Jeśli macie jakieś dodatkowe pytania do tego, co widać i słychać, to z naszej społeczności obecni byli: ja, PiotrekD i Ludmiła Pilecka. Pozdrawiam, Nostrix (dyskusja) 20:26, 14 sty 2018 (CET)
- Ok. Ktoś by mógł zredagować przekaz? Wyciąć rozmowy techniczne / przygotowawcze? Pełen zapis postawić oczywiście, ale.. przekaz, ograniczyć do meritum? Pozdrawiam Krokus (dyskusja) 21:18, 14 sty 2018 (CET)
- Nie wiem jak bardzo wnikliwego przekazu byś chciała. Nie wiem też, czy wiesz czym są Wikidane i co gromadzą (dla Wikipedii, ale też jako odrębny projekt siostrzany). Otóż pomysł Wikimedia Deutschland (która opiekuje się Wikidanymi od strony technicznej) jest taki, aby dodać do Wikidanych dane gromadzone na wszystkich Wikisłownikach. Po dodaniu słów powstałaby grupa elementów oznaczonych literą L - leksemy (elementy na wikidanych są oznaczone zdaje się Q i P). Trwają prace nad opracowywaniem struktury tej grupy danych (językowych). Wszystko, co można zobaczyć na zrzutach ekranu w prezentacji oraz na specjalnej testowej wiki to wersje beta-beta i każdy głos społeczności każdego Wikisłownika jest brany pod uwagę, więc mamy wpływ na to, jak ta struktura będzie wyglądać później w Wikidanych. Na razie wiadomo, że na Wikidanych miałyby się znaleźć leksemy, tłumaczenia tych leksemów na wszystkie języki oraz odmiany tych leksemów, o ile występuje w danym przypadku fleksja. Na pewno nie wszystkie dane z Wikisłownika da się przenieść w stosunku 1:1 do Wikidanych, bo np. etymologia jest często (u nas) opisowa, nie ma więc sensu wprowadzać jej do Wikidanych. Te dane, które się tam pojawią w przyszłości będzie można wywoływać (wyświetlać) w naszych hasłach za pomocą specjalnej składni - tak jak to ma nastąpić w infoboksach w Wikipedii w zakresie np. dat urodzenia i innych "twardych" informacji. Oczywiście pod warunkiem, że społeczność projektu wyrazi na to zgodę. Nostrix (dyskusja) 22:21, 14 sty 2018 (CET)
- Dzięki Nostrix za zreferowanie pierwszej części i podlinkowanie slajdów i nagrania. W końcu zebrałem do kupy pytania itd z części dyskusyjnej: [16]. Mam nadzieję, że będą przydatne także dla osób nieobecnych na zlocie. Chętnie odpowiem na pytania lub wyjaśnię kwestie ogólne albo szczegółowe, jeśli . W najbliższych dniach jestem w innej strefie czasowej, także proszę o zrozumienie, jeśli będę reagował z opóźnieniem. Leszek Manicki (WMDE) (dyskusja) 04:42, 22 sty 2018 (CET)
- Nie wiem jak bardzo wnikliwego przekazu byś chciała. Nie wiem też, czy wiesz czym są Wikidane i co gromadzą (dla Wikipedii, ale też jako odrębny projekt siostrzany). Otóż pomysł Wikimedia Deutschland (która opiekuje się Wikidanymi od strony technicznej) jest taki, aby dodać do Wikidanych dane gromadzone na wszystkich Wikisłownikach. Po dodaniu słów powstałaby grupa elementów oznaczonych literą L - leksemy (elementy na wikidanych są oznaczone zdaje się Q i P). Trwają prace nad opracowywaniem struktury tej grupy danych (językowych). Wszystko, co można zobaczyć na zrzutach ekranu w prezentacji oraz na specjalnej testowej wiki to wersje beta-beta i każdy głos społeczności każdego Wikisłownika jest brany pod uwagę, więc mamy wpływ na to, jak ta struktura będzie wyglądać później w Wikidanych. Na razie wiadomo, że na Wikidanych miałyby się znaleźć leksemy, tłumaczenia tych leksemów na wszystkie języki oraz odmiany tych leksemów, o ile występuje w danym przypadku fleksja. Na pewno nie wszystkie dane z Wikisłownika da się przenieść w stosunku 1:1 do Wikidanych, bo np. etymologia jest często (u nas) opisowa, nie ma więc sensu wprowadzać jej do Wikidanych. Te dane, które się tam pojawią w przyszłości będzie można wywoływać (wyświetlać) w naszych hasłach za pomocą specjalnej składni - tak jak to ma nastąpić w infoboksach w Wikipedii w zakresie np. dat urodzenia i innych "twardych" informacji. Oczywiście pod warunkiem, że społeczność projektu wyrazi na to zgodę. Nostrix (dyskusja) 22:21, 14 sty 2018 (CET)
O, pojawia się szansa na to, że ten projekt zniknie. OlafOlaf16 (dyskusja) 00:45, 15 sty 2018 (CET)
Ciekawe. To się chyba kiedyś musiało stać. Wyprowadzenie głównej treści z Wikisłownika sprawi, że stanie się on w zasadzie nakładką na treść, formatującą ją i wyświetlająca. Z perspektywy samego tylko języka polskiego to nie wniesie zbyt wiele. Błyszczeć będzie przy rozwijaniu nowych stron na bazie już wykonanej pracy, gdzie w sumie umożliwi natychmiastowe skopiowanie treści. Świetna wiadomość dla automatów, a dla ludzi, hm. Okcydent (dyskusja) 02:07, 15 sty 2018 (CET)
- Myślę, że to jednak dość odległa perspektywa. Z początku sam byłem sceptyczny i bałem się, że właśnie Wikisłownik zostanie jedynie "skórką" dla danych z Wikidanych, ale jednak nie - nie wszystkie gromadzone tutaj informacje będą "przenoszone" na Wikidane. Wszystko, co jest opisowe, a także przykłady użycia, wspomniana etymologia, uwagi językowe etc. - będzie rozwijane tutaj. Nie sądzę też, aby Wikidane były zainteresowane przysłowiami itp. Chodzi też o to, że gromadząc tak dużo "twardych" danych językowych w jednej bazie będzie można zadawać tej bazie ciekawe "pytania" za pomocą składni SPARQL (co posłuży badaniom językowym w dalekiej przyszłości). Nostrix (dyskusja) 20:44, 16 sty 2018 (CET)
- A dla mnie nie. Już teraz przy dość małym nakładzie pracy są w stanie przerzucić podstawowy zrąb terminów angielskich i dalej konwertować co większe wikisłowniki, bazując tylko na odwołaniach do angielskiego. Etymologia jest przewidziana by trzymać ją na Wikidanych, przynajmniej przez wskazanie jednej formy bazowej. Etymologia jak widzę jest dość grząskim gruntem i widziana dość różnie przez różne narody. W zasadzie to z Wikisłownika brakuje części poprawnościowej, przykładów, trochę przypisów, ilustracji. Czyli w większości czegoś co albo stanowi prezentację, albo da się łatwo dodać jako właściwości. No i nie stanowi (prawie) żadnej wartości dla algorytmów. Z tego co wnioskuję z komentarzy takie przejście na Wikidane spowoduje swoiste pomnożenie bytów. Każda trójca forma × płeć × odmiana będzie musiała stanowić osobny leksem. Poza tym nie wiem jak to wyjdzie z nieuchronnym rozstrzyganiem sporów. To jednak jest uzależnienie się od zewnętrznej bazy, z której każda aktualizacja prawdopodobnie przeniesie się natychmiast na ten wikisłownik. Okcydent (dyskusja) 23:05, 16 sty 2018 (CET)
- Dodam, że w planach jest edytowanie Wikidanych z poziomu Wikisłownika. Czyli można byłoby edytować na Wikisłowniku, bez potrzeby zmiany projektu itd. W takim rozwiązaniu można by patrzeć na Wikidane jak na magazyn, gdzie są zapisywane dane w określonej formie, a Wikisłownik byłby (możliwe, że niejedynym) projektem, który wyświetla te (wybrane) dane w określony przez siebie sposób, a także zapewnia możliwość dodawania, edytowania itp tych danych. Ta funkcjonalność jest dopiero w fazie wczesna alfa, stąd niewiele jeszcze możemy o tym powiedzieć. Co do podniesionych przez Okcydenta kwestii rozstrzygania sporów, możliwych trudności i zależności od innej bazy danych - pełne zrozumienie. Leszek Manicki (WMDE) (dyskusja) 04:42, 22 sty 2018 (CET)
Chciałem tylko pobieżnie wspomnieć o istniejącym od dawna OmegaWiki, projekcie w założeniu przypominającym Wikidane dla słowników. Więcej można przeczytać na stronie meta:OmegaWiki. Pozdrawiam, Peter Bowman (dyskusja) 02:30, 15 sty 2018 (CET)
Dla mnie najważniejsze jest abym mógł jak dotychczas edytować hasło w jednym miejscu. KaMan (dyskusja) 08:00, 22 sty 2018 (CET)
Podejrzewam, że część osób może nie śledzić dyskusji w Wikidanych, więc dla zainteresowanych wspominam, że kilka dni temu zaczęła się tam kolejna dyskusja w związku z ogłoszeniem First version of Lexicographical Data will be released in April (permalink) (całość po angielsku). Ja nie siedzę w temacie i niespecjalnie rozumiem, o co dokładnie chodzi, ale może kogoś zainteresuje. Wostr (dyskusja) 13:36, 10 mar 2018 (CET)
Wymowa form fleksyjnych
Optuję za wprowadzeniem możliwości zamieszczania wymowy dla poszczególnych form fleksyjnych dla odmiennych części mowy w języku polskim. Przy czym aby zachować dotychczasowy układ to wymowę tą można by było zamieścić albo w sekcji {{wymowa}} dublując szablony z sekcji {{odmiana}} wpisując w nich zamiast słów ich zapis fonetyczny; lub co jest trudniejsze technicznie – tą wymowę zamieszczać w sekcji {{odmiana}} przy jednoczesnym ustawieniu by wymowa wyświetlała się na życzenie użytkownika. Superjurek (dyskusja) 20:12, 17 sty 2018 (CET)
- Ile form odmienionych jest na Commons? Niewiele. O ile się orientuję, te formy liczby mnogiej, które już tam są, już zostały powstawiane do haseł w sekcji wymowy. Wedle mnie wstawienie tam natomiast wszech form nadmiernie by ją rozepchało. Wstawianie wymowy do sekcji odmiany wymagałoby zmian w szablonie. Już całkowicie pomijając kwestię stylistyki, śmiem twierdzić, że jest to dodawanie funkcjonalności, która nie zapowiada się na taką, która będzie często używana; wygląda mi to na porywanie się z motyką na słońce. Sugerowałbym jednak skupić się na dodawaniu do haseł form „głównych”. Pozdrawiam, PiotrekDDYSKUSJA 20:36, 17 sty 2018 (CET)
Wymowa form fleksyjnych jest już od dawna podawana w sekcji wymowy m.in. w hasłach niemieckich. KaMan (dyskusja) 08:09, 18 sty 2018 (CET)
Aoryst w języku polskim
Wnoszę o zgodę na dodawanie aorystu w hasłach dotyczących czasowników polskich. Bardzo chętnie bym się tym zajął. Ponieważ nie umiem redagować zaawansowanych szablonów z formatowaniem warunkowym, to pokusiłem się o użycie wikitabelki w taki sposób Special:Diff/6123103, ale mój patent się nie utrzymał zbyt długo. Uważam że Wikisłownik powinien się rozwijać w różnych kierunkach, inicjatywy oddolne temu bardzo służą, a wyjście z użycia danej formy leksykalnej nie jest przesłanką przeciwko opisywaniu takiego zagadnienia w Wikisłowniku; gdyż idąc takim tokiem musielibyśmy spisać na straty również czas zaprzeszły, tryb rozkazujący 1.os. lp oraz rodzaj nijaki 1. i 2. os. lp Superjurek (dyskusja) 20:45, 23 sty 2018 (CET)
- Dodam jeszcze, że nie musiałoby się to wiązać z koniecznością uzupełniania wszędzie aorystu. Dodatkowe parametry w szablonie {{odmiana-czasownik-polski}} mogłyby być opcjonalne i tym samym wszystkie dotychczasowe hasła dalej wyświetlałyby się prawidłowo przed ewentualnym uzupełnieniem tych 6 dodatkowych parametrów. Superjurek (dyskusja) 20:51, 23 sty 2018 (CET)
- @Superjurek: Czy ta propozycja jest żartem? PiotrekDDYSKUSJA 22:20, 23 sty 2018 (CET)
- @PiotrekD: Raczej propozycją mającą na celu rozwój WS, a Twoje pytanie brzmi trochę jakby było ad personam... Superjurek (dyskusja) 22:38, 23 sty 2018 (CET)
- [konflikt edycji] @Superjurek: Jest to normalne pytanie. Z tego, co wyczytałem, wynika, że chcesz dodawać do tabelki odmiany wybrane spośród wielu formy nieużywane przez ogół od setek lat, a więc zdecydowanie niebędące częścią obecnej normy językowej czy też obecnego systemu gramatycznego, i zestawiasz je z rzadko używanymi formami będącymi częścią tychże… Już widzę te formy w haśle „lajkować” :D. Propozycja ta brzmi nieco śmiesznie. PiotrekDDYSKUSJA 22:52, 23 sty 2018 (CET)
- Zasady tworzenia imperfektu, aorystu i optitatiwu przedstawiono tu. Superjurek (dyskusja) 22:48, 23 sty 2018 (CET)
- @PiotrekD: Czy w związku z tym nie można by przynajmniej pokusić się o utworzenie aneksu dla tychże form gramatycznych? Superjurek (dyskusja) 23:39, 23 sty 2018 (CET)
- Jako aneks - oczywiście, w hasłach - niespecjalnie. Nostrix (dyskusja) 09:35, 12 lut 2018 (CET)
- @PiotrekD: Czy w związku z tym nie można by przynajmniej pokusić się o utworzenie aneksu dla tychże form gramatycznych? Superjurek (dyskusja) 23:39, 23 sty 2018 (CET)
- @PiotrekD: Raczej propozycją mającą na celu rozwój WS, a Twoje pytanie brzmi trochę jakby było ad personam... Superjurek (dyskusja) 22:38, 23 sty 2018 (CET)
Słownik żargonu/slangu telemarketerów
Dzień dobry, kiedyś do dużego tekstu, nad którym pracowałam, posiłkowałam się słownikiem żargonu policyjnego. Był bardzo pomocny, a przy okazji mnie rozbawił. Teraz, kiedy go potrzebuję nie mogę go znaleźć w Wikisłowniku i najczęściej odszukuję go posiłkując się przeglądarką googla. Przypadkowo - taka praca - udało i się zgromadzić kilkadziesiąt haseł do słownika call center. Poszczególne określenia slangowe wraz z tłumaczeniem obowiązującym w danej korporacji nadsyłali do mnie telemarketerzy. Uznałam,że szkoda zaprzepaścić ten niewielki na razie zbiór i dobrze byłoby stworzyć słownik call center. Z czasem uzupełniany o kolejne pozycje. Przeczytałam większość wskazówek, przejrzałam "drzewko zależności" i nie wiem gdzie go zamieścić - to znaczy w jakiej kategorii. Co dziwne, nie widzę tutaj słowników Wiki, z których korzystałam tzn. żargonu policyjnego i ratowników medycznych, a sadzę,że tego typu zbiory powinny znajdować się w jednym miejscu. Proszę o pomoc i/lub wskazówki, a przy okazji serdecznie pozdrawiam Runaways JJ (dyskusja) 14:04, 2 lut 2018 (CET)
Hiperonimy i hiponimy oraz femininum.
Nie wiem czy tylko ja uważam to za problem, ale umieszczenie pod sobą hipero i hiponimów uważam za bardzo niefortunne. Te dwa wyrazy mają wspólny początek hip i wspólny koniec onimy, a ich długość też nie jest znacząco różna, przez co nie da się ich rozróżnić na pierwszy rzut oka i każe się każdorazowo zastanawiać nad wyborem odpowiedniej kategorii. Pozostałe nimy wyróżniają się graficznie - choć muszę przyznać, że nazwy mero- i holo- niekoniecznie mówią coś osobie nieobeznanej ze słownikarstwem.
Zastanawia mnie fakt utrzymywania symbolu f na oznaczenie rodzaju żeńskiego. Wszystkie pozostałe rodzaje oznaczane są po polsku: m (mos, mzw, mrz), n, mos, nmos. Podobnie liczby lm, lp. Tylko ż się wyłamuje. Wikisłownik rosyjski jak i czeski używają f w kodzie, ale wyświetlają swoje odpowiedniki litery ż. Taka zmiana chyba nie będzie trudna do przeprowadzenia. Okcydent (dyskusja) 03:26, 4 lut 2018 (CET)
- @Okcydent:
- Od ponad roku planowałem zaproponować w barze, żeby uczynić, iż po najechaniu na którykolwiek nagłówek sekcji -nimów pojawiał się dymek z wyjaśnieniem, co to jest za cudo, tak jak dzieje się, gdy najeżdża się na nagłówki typów frazy w definicjach. Dzięki za poruszenie tematu, wreszcie przypomniałem sobie, że mam o tym wspomnieć. Tak więc proponuję to, co zostało wspomniane wyżej.
- To ż zamiast ż też mnie zastanawiało. Chyba w założeniu miało być bardziej międzynarodowo, cokolwiek to konkretnie ma oznaczać. Niemniej reszta skrótów jest faktycznie po polsku, a wszystkie (jeśli dobrze pamiętam) słowniki języka polskiego, z którymim miał kontakt, używają ż, to samo dotyczy części polskich słowników dwujęzycznych. Drobna rzecz; mnie, leniwemu człowiekowi, nigdy by się nie chciało chyba proponować tego w barze, szczerze mówiąc. Ale skoro już zostało zaproponowane, to… no, popieram, co innego mogę jeszcze rzec.
- Pozdrawiam, PiotrekDDYSKUSJA 11:51, 4 lut 2018 (CET)
- Gorąco popieram zmianę f na ż. Nostrix (dyskusja) 09:34, 12 lut 2018 (CET)
- Również popieram zmianę f na ż. Pozdrawiam, --SolLuna dyskusja 01:13, 9 maj 2018 (CEST)
- Popieram zmianę w wyświetlaniu f jako ż, aby było konsekwentnie - kiedyś, tak na marginesie, ta konsekwencja była (były to oznaczenia międzynarodowe, dopóki nie wprowadzono oznaczeń typowych dla języka polskiego typu mrz). Jestem jednakże przeciwna zamianie f na ż w kodzie chociażby dlatego, że trzeba wciskać jednocześnie dwa przyciski. Ewentualnie niech oba zapisy f i ż w kodzie wyświetlają się jako ż - to dobra alternatywa: i wilk syty (wyświetlanie polskiego oznaczenia rodzaju) i owca cała (ci przyzwyczajeni od ż, ci z innych wikisłowników, ci ceniący sobie ergonomię w życiu, czy też ci, co nie chcą tracić czasu na sprawdzanie, czy wcisnęło im się na pewno ż, a nie z, jak to się często zdarza przy szybki m pisaniu). :) @PiotrekD Popieram też propozycję dymków. Pozdrawiam Krokus (dyskusja) 13:31, 10 maj 2018 (CEST)
- @Krokus: można wstawiać też szablony jednym kliknięciem, pod oknem edycji w zakładce „Szablony i znaki dodatkowe” (taki sam mechanizm powiela skrypt ToStera – formularz edycji). Ponadto aby wprowadzić znaki
{{}}i tak trzeba wcisnąć dwa klawisze naraz :). @Alkamid, @Olaf (operatorzy botów): czy ewentualna obecność {{ż}} w miejscu {{f}} gryzłaby się z którymś automatem? @Olaf: czy możliwe byłoby uwzględnienie podmiany szablonów w kodzie w trakcie nocnego sprzątania haseł (tak jak np. podmieniasz {{komp}} na {{inform}})? Peter Bowman (dyskusja) 20:33, 15 maj 2018 (CEST)
- @Krokus: można wstawiać też szablony jednym kliknięciem, pod oknem edycji w zakładce „Szablony i znaki dodatkowe” (taki sam mechanizm powiela skrypt ToStera – formularz edycji). Ponadto aby wprowadzić znaki
- Popieram zmianę w wyświetlaniu f jako ż, aby było konsekwentnie - kiedyś, tak na marginesie, ta konsekwencja była (były to oznaczenia międzynarodowe, dopóki nie wprowadzono oznaczeń typowych dla języka polskiego typu mrz). Jestem jednakże przeciwna zamianie f na ż w kodzie chociażby dlatego, że trzeba wciskać jednocześnie dwa przyciski. Ewentualnie niech oba zapisy f i ż w kodzie wyświetlają się jako ż - to dobra alternatywa: i wilk syty (wyświetlanie polskiego oznaczenia rodzaju) i owca cała (ci przyzwyczajeni od ż, ci z innych wikisłowników, ci ceniący sobie ergonomię w życiu, czy też ci, co nie chcą tracić czasu na sprawdzanie, czy wcisnęło im się na pewno ż, a nie z, jak to się często zdarza przy szybki m pisaniu). :) @PiotrekD Popieram też propozycję dymków. Pozdrawiam Krokus (dyskusja) 13:31, 10 maj 2018 (CEST)
@Okcydent, @PiotrekD, @Nostrix, @SolLuna, @Krokus: od tej chwili szablon {{f}} wyświetla skrót ż (Specjalna:Diff/6189853). Niezalogowani wciąż mogą zauważyć poprzedni zapis, strony będą się stopniowo odświeżać na serwerze. Chyba obędzie się na razie bez tworzenia nowego szablonu i przekierowań, w ten sposób nie zmieniamy naszych stron pomocy ani skryptów. Dostosowałem jedynie nasz spis skrótów: WS:SKR#F, WS:SKR#Ż. Pozdrawiam, Peter Bowman (dyskusja) 13:14, 20 maj 2018 (CEST)
- @Peter Bowman: (Rzadko się niestety ostatnio udzielam na WS, ale cóż…). Zdecydowanie uważam, że powinniśmy przenieść {{f}} pod {{ż}}, a pod {{f}} zostawić przekierowanie dla kompatybilności wstecznej i Krokus (;>), wywołania którego poprawiałby bot Olafa, jak już zdarza mu się robić w przypadku innych przekierowań. Rozdwojenie między tymi literami wydają mi się mylące, zwłaszcza dla nowych użytkowników – otwierają edytor kodu, a tam żadnego
ż, tylko jakieś niejasne{{f}}. Uważam, że kod strony powinien jak najbardziej sugerować wygląd strony po opublikowaniu. Dodatkowo znaczenie tego efa nie musi być takie oczywiste (o jego używaniu pisałem wyżej), a w edytorze kodu nie można kliknąć myszką, by dostać się na stronę, która objaśnia znaczenie skrótów. Pozdrawiam, PiotrekDDYSKUSJA 15:28, 20 maj 2018 (CEST)- Wysłałem mejl do Olafa – jeżeli da się uwzględnić taką zamianę w bocie, przeniosę szablon. Znaczenie skrótu można wydobyć, umieszczając kursor nad nim albo rozwijając wszystkie (zakładka). Peter Bowman (dyskusja) 16:42, 20 maj 2018 (CEST)
- @Peter Bowman: Można, ale nie w trybie edycji, a o tym pisałem wyżej. Trzeba obejrzeć podgląd, w który z kolei literki f nie ma. Pozdrawiam, PiotrekDDYSKUSJA 16:19, 21 maj 2018 (CEST)
- Wysłałem mejl do Olafa – jeżeli da się uwzględnić taką zamianę w bocie, przeniosę szablon. Znaczenie skrótu można wydobyć, umieszczając kursor nad nim albo rozwijając wszystkie (zakładka). Peter Bowman (dyskusja) 16:42, 20 maj 2018 (CEST)
- @Peter Bowman - dzięki wielkie :). Nostrix (dyskusja) 10:31, 21 maj 2018 (CEST)
- Ok, szablon {{f}} przeniesiony do {{ż}}. Olafbot również będzie zamieniał {{f}} na {{ż}} w swoich edycjach. Olaf (dyskusja) 01:43, 29 maj 2018 (CEST)
- Pytanie: czy jest taka możliwość, aby do WP:SK dodać zmianę {{f}} na {{ż}}? Nostrix (dyskusja) 13:36, 10 cze 2018 (CEST)
- @Nostrix: Mogę na tygodniu przejechać botem wszystkie hasła i dokonać w nich zamiany, jeśli nie ma do tego uwag. To prosta zamiana. PiotrekDDYSKUSJA 13:54, 10 cze 2018 (CEST)
- @PiotrekD AFAIK bot Olafa już to systematycznie robi partiami. Przynajmniej tak wynika z haseł, które mam w obserwowanych. KaMan (dyskusja) 10:18, 11 cze 2018 (CEST)
- @Nostrix: zrobione (Specjalna:Diff/6200093). Peter Bowman (dyskusja) 14:10, 10 cze 2018 (CEST)
- @Nostrix: Mogę na tygodniu przejechać botem wszystkie hasła i dokonać w nich zamiany, jeśli nie ma do tego uwag. To prosta zamiana. PiotrekDDYSKUSJA 13:54, 10 cze 2018 (CEST)
Font nagłówkowy źle wyświetla grekę
Vide → ἓν μόνον ἀγαθὸν εἶναι, τὴν ἐπιστήμην, καὶ ἓν μόνον κακόν, τὴν ἀμαθίαν. ZojaZoja23 (dyskusja) 14:49, 11 lut 2018 (CET)
Propozycja zmiany sposobu wstawiania pokrewnych
Tezy
- W każdym haśle z grupy wyrazów pokrewnych powielana jest ta sama treść.
- Hasła dla wyrazów pokrewnych powinny mieć ten sam zestaw słów w sekcji pokrewne (z pominięciem wyrazu będącego tematem hasła).
- Uzupełnienie pokrewnych zaczyna być coraz bardziej upierdliwe.
- Bezsensowne jest wykonywanie tej samej pracy (umysłowej i manualnej) wielokrotnie.
Propozycje
- Stworzyć nową przestrzeń nazw "Pokrewne".
- Dla każdej grupy wyrazów pokrewnych utworzyć jedno hasło w przestrzeni "Pokrewne", o takiej nazwie, jaką ma najprostszy, najbardziej podstawowy wyraz w tej grupie.
- W przypadku istnienia wyrazu mającego dwu lub więcej znaczeń o różnym pochodzeniu (patrz →
muł) tworzyłoby się oddzielne hasła w przestrzeni "Pokrewne", które różnią się numerem ("muł 1", "muł 2").
Przykład działania (jeżeli Sankoff64 i KaMan powstrzymali swój delecjonizm)
- Robię kopiuj-wklej ostatniej wersji i usuwam stronę. Eksperyment trwa już dwa miesiące, prośba (także na przyszłość) o przeprowadzanie prób we własnej przestrzeni. Peter Bowman (dyskusja) 19:53, 19 kwi 2018 (CEST)
- Zobacz przykładowe hasło w przestrzeni "Pokrewne" –
Pokrewne:materia - Zobacz jak to działa przy wstawieniu:
- rzecz. materia ż, materiał m, antymateria ż, materialność ż, niematerialność ż, materializowanie n, zmaterializowanie n, materializm m, materialista m, materialistka ż, materiałówka ż
- czas. materializować ndk., zmaterializować dk.
- przym. materialny, materiałowy, materiałowy, materialistyczny
- przysł. materialnie, niematerialnie, materiałowo, materialistycznie
- Zobacz hasła ze zmodyfikowanym wpisem w sekcji pokrewnych –
niematerialny,materia,materiał.
Kwestie techniczne do rozstrzygnięcia
- Jak wykonać ukrywanie głównego pokrewnego wyrazu w haśle o tej samej nazwie? Wykonałem
Szablon:główny-pokrewny, który prawdopodobnie zadziała, ale trzeba zrobić walidację. - Jak wyglądałoby przeniesienie treści z sekcji pokrewne do przestrzeni nazw "Pokrewne"? Czy któryś bot temu podoła?
- Jak wykonać pokrewne dla różnych języków? Są jakieś pomysły?
Howgh --- ZojaZoja23 (dyskusja) 18:54, 14 lut 2018 (CET)
Dyskusja
- Tylko komu przydadzą się rozbuchane na 200 elementów wszelakich sekcje pokrewnych, które w wyniku wprowadzenia tego pomysłu w życie pojawiłyby się w niejednym arcie, znając nadgorliwość niektórych dodawaczy pokrewnych? Tworzenie ich byłoby sztuką dla sztuki, nie dla naszych czytelników. Jestem w stanie pomyśleć nad sposobem mieszanym w stylu ru.wikt (przykład), ale już teraz mogę powiedzieć, że wprowadzenie proponowanego tu systemu jako jedynego spowoduje bałagan i nikomu się nie przyda; jestem temu przeciwny. PiotrekDDYSKUSJA 19:13, 14 lut 2018 (CET)
- Podobnie jestem przeciw. Wielokrotnie o tym pisałem. Naszym problemem jest brak etymologii w wielu hasłach, a to jest ściśle związane z pokrewnymi. Bez poprawnej i uźródłowionej etymologii będą pojawiać się kwiatki w stylu pokrewieństwa między „krzyżem” a „krzyżmem”, bo komuś wydało się, że ze względu na podobne brzmienie to wyrazy spokrewnione. Rozwiązanie z ru.wiktionary.org nie należy do najszczęśliwszych. Jestem zwolennikiem wstawiania pokrewnych ręcznie (z pewną pomocą Olafbota), starając się, aby to była zwarta grupa wyrazów o możliwie najbliższym stopniu pokrewieństwa. Cechą dobrego hasła jest przede wszystkim przejrzystość. Nadmiernie rozbudowywanie któregokolwiek pola (w tym wyrazów pokrewnych), tej przejrzystości nie służy. Pozdrawiam. Sankoff64 (dyskusja) 19:24, 14 lut 2018 (CET)
- Obaj piszecie nie na temat. Poruszam kwestię techniczną, która może ułatwić edytowanie, a Wam się "wylewa" przy okazji wszystko, co myślicie na temat sekcji wyrazów pokrewnych i błędach edytorów. No to sobie podyskutowaliśmy. ZojaZoja23 (dyskusja) 21:17, 14 lut 2018 (CET)
- Ja natomiast popieram takie zwijane listy jak są w Wikisłowniku Rosyjskim. Bardzo się to przyda w przypadku rozdzielnych znaczeń i rozbuchanych list. Podobnie potraktowane powinny zostać zobacz-teże które lądują w uwagach. Niemcy potrafili co poniektóre ubrać w ładne szablony i umieścić słowa pokrewne dziedzinowo - jak nazwy państw (przykład) w zgrabnych ramkach. Samym tłumaczeniom także przydałaby się opcja zwijania, albo podziału na regiony/rodziny językowe. Rosjanie poszli bardzo mocno w szablonowanie i potrafią traktować nawet etymologię słów łacińsko-greckich w różnych językach jednym szablonem, co jest już przesadą bo nie oddaje drogi przenikania wyrazów. Okcydent (dyskusja) 23:00, 14 lut 2018 (CET)
- Podobnie jestem przeciw. Wielokrotnie o tym pisałem. Naszym problemem jest brak etymologii w wielu hasłach, a to jest ściśle związane z pokrewnymi. Bez poprawnej i uźródłowionej etymologii będą pojawiać się kwiatki w stylu pokrewieństwa między „krzyżem” a „krzyżmem”, bo komuś wydało się, że ze względu na podobne brzmienie to wyrazy spokrewnione. Rozwiązanie z ru.wiktionary.org nie należy do najszczęśliwszych. Jestem zwolennikiem wstawiania pokrewnych ręcznie (z pewną pomocą Olafbota), starając się, aby to była zwarta grupa wyrazów o możliwie najbliższym stopniu pokrewieństwa. Cechą dobrego hasła jest przede wszystkim przejrzystość. Nadmiernie rozbudowywanie któregokolwiek pola (w tym wyrazów pokrewnych), tej przejrzystości nie służy. Pozdrawiam. Sankoff64 (dyskusja) 19:24, 14 lut 2018 (CET)
- Jak będzie brzmiał w przestrzeni "Pokrewne" najprostszy, najbardziej podstawowy wyraz dla grupy: list (liścik) - liść (listek)? Zetzecik (dyskusja) 23:11, 14 lut 2018 (CET)
- List czy liść? Możesz wybrać. -- ZojaZoja23 (dyskusja) 23:56, 14 lut 2018 (CET)
- Wydaje mi się, że jeśli chodzi o kwestię techniczną ułatwienia edytowania, to nie jest potrzebny żaden dodatkowy mechanizm i nie musisz edytować więcej niż jednego hasła na raz. Jeśli dodasz pokrewne w jednym haśle, pokrewne zostaną przez Olafbota automatycznie uzupełnione w linkowanych z tej sekcji artykułach. Czyli jeśli dodasz w haśle materia pokrewne materiał i niematerialny, to w tych hasłach automatycznie pojawi się rzecz. materia. Nie od razu, sprawdzanie tego za długo zajmowało, więc bot przetwarza to po kawałku i czasem trzeba poczekać i miesiąc aż dojdzie do danego miejsca, ale dodaje, nie musisz tego robić w każdym z tamtych haseł. Problem z osobnym artykułem jest taki, że "pokrewność" nie jest relacją przechodnią, to znaczy jeśli A jest pokrewne B a B jest pokrewne C, to niekoniecznie A jest pokrewne C, bo nie tylko o temat chodzi, np. jeśli ktoś poda królik jako pokrewny słowu króliczy, ale też król (w końcu to zdrobnienie), a król jest pokrewny królować, to czy króliczy jest pokrewny królować? Albo jeśli deskorolka jest pokrewna słowom deska i rolka, to czy deska jest pokrewna słowu rolka? Poza tym gdyby przyjąć Twoją propozycję, trzeba by każdorazowo edytować więcej – hasło i artykuł o pokrewnych, a tak wystarczy hasło. Olaf (dyskusja) 23:35, 14 lut 2018 (CET)
- A uporządkujmy i uściślijmy definicję pokrewnych. Częściowo to już tu zrobiono wyłączając z pokrewnych wyrazy złożone – "deskorolka" wypada z pokrewnych wyrazu "deska" i "rolka" tworząc własną grupę ze słowami "deskorolkarz" i "deskorolkowy". Wtedy okaże się, że pokrewne w ramach jednego języka, tworzą rozłączne zbiory. Wątpliwości mogą się pojawić, ale będzie to marginalna skala no i zadziałać musi wtedy myślenie i człowiek. Dlatego moja propozycja jest odpowiedzią na to, czego niestety botem nie zrobisz. Hasło w przestrzeni "Pokrewne" tworzyć będą ludzie. Bot mógłby zająć się podpinaniem ich pod odpowiednie hasła, chociaż jak przypuszczam, można to będzie oprogramować jeszcze prościej. - ZojaZoja23 (dyskusja) 23:56, 14 lut 2018 (CET)
- Mamy tutaj prawie 700 tysięcy haseł. Spory procent z tego zawiera pokrewne. Nie da się teraz zastąpić tego systemu takim w którym klasy są rozłączne, bo jest tego za dużo w tej chwili rozłączne nie są i nikt tego ręcznie nie przesortuje, bot też nie potrafi z tego zrobić rozłącznych klas. Czyli w praktyce ten system mógłby jedynie funkcjonować równolegle z obecnie istniejącym i ludzie by nie wiedzieli gdzie co mają wpisywać. Boję się, że spowodowałoby to tylko większe zamieszanie. Jeszcze jedna kwestia - Jeśli zrobisz tak jak planujesz, to w haśle Pokrewne:Berlin będziemy mieli mieszaninę kilku różnych języków, więc tak prosto na pewno się nie da, trzeba by tam tworzyć sekcje językowe. Olaf (dyskusja) 00:08, 15 lut 2018 (CET)
- Pomysł na gorąco – rodzinę tworzysz w ten sposób:
Pokrewne:Berlin/pla w przypadku kilku rodzin dla jednego wyrazuPokrewne:muł/pl/1orazPokrewne:muł/pl/2. ZojaZoja23 (dyskusja) 00:26, 15 lut 2018 (CET)
- Pomysł na gorąco – rodzinę tworzysz w ten sposób:
- Mamy tutaj prawie 700 tysięcy haseł. Spory procent z tego zawiera pokrewne. Nie da się teraz zastąpić tego systemu takim w którym klasy są rozłączne, bo jest tego za dużo w tej chwili rozłączne nie są i nikt tego ręcznie nie przesortuje, bot też nie potrafi z tego zrobić rozłącznych klas. Czyli w praktyce ten system mógłby jedynie funkcjonować równolegle z obecnie istniejącym i ludzie by nie wiedzieli gdzie co mają wpisywać. Boję się, że spowodowałoby to tylko większe zamieszanie. Jeszcze jedna kwestia - Jeśli zrobisz tak jak planujesz, to w haśle Pokrewne:Berlin będziemy mieli mieszaninę kilku różnych języków, więc tak prosto na pewno się nie da, trzeba by tam tworzyć sekcje językowe. Olaf (dyskusja) 00:08, 15 lut 2018 (CET)
- To prawda, ale zwykle (często) istnieją zbiory powiązane każdy z każdym. Taką deskorolkę czekałby prawdopodobnie zapis w postaci: deskorolka, deskorolkarz, deskorolkarka, deskorolkowy, deskorolkarstwo, deskorolkownia itd. + Zobacz też rodziny pokrewnych +rolka +deska. Podobnie zadziałałoby to z liściem i listem. Zapewniałoby to pewien porządek, choć nie wiem jak bardzo wydłużyłoby edycję i czy liczba takich rodzin nie rozrosłaby się lawinowo. Okcydent (dyskusja) 00:02, 15 lut 2018 (CET)
- Definicja może być prosta:
Wyrazy pokrewne to takie, które zawierają rdzeń pochodzący od jednego, tego samego słowa i różne afiksy.To OR, ale można tę definicję zweryfikować i uściślić. -- ZojaZoja23 (dyskusja) 00:17, 15 lut 2018 (CET)
- Definicja może być prosta:
- To może po prostu róbcie gdzieś takie rodziny, a bot będzie wrzucał do artykułów? Już teraz tak robi z rodzinami z angielskiego, jakie znalazłem tutaj: simple:Wiktionary:BNC_spoken_freq_01. Jeśli zrobicie taką listę dla polskiego, najlepiej w tym samym formacie, chętnie zaprogramuję, żeby automatycznie dorzucał. Olaf (dyskusja) 00:11, 15 lut 2018 (CET)
- Olaf, no właśnie tego de facto dotyczy moja propozycja – utworzenia rodzin w odrębnej przestrzeni nazw. ZojaZoja23 (dyskusja) 00:17, 15 lut 2018 (CET)
- Ale moja dotyczy czego innego - utworzenia rodzin na jednej oddzielnej stronie, np. Wikisłownik:Rodziny pokrewnych dla języka polskiego, bez linkowania z artykułów. Nie chcę tworzyć osobnej przestrzeni nazw, ani setek artykułów dublujących sekcję pokrewne. Jedynym celem istnienia strony byłoby jej codzienne czytanie przez bota i dorzucanie przez niego pokrewnych do tych artykułów, a nie bezpośrednie czytanie przez użytkowników słownika. Zrób taką stronę, najlepiej w podobnym formacie jak ta angielska, ja to oprogramuję. Olaf (dyskusja) 00:24, 15 lut 2018 (CET)
- Jedna ogromna strona dla całego języka? To będzie koszmar edycyjny – niewygodny, tworzący konflikty edycji i błędy kodu, gdy przeglądarka klienta nie zaciągnie całego kodu. -- ZojaZoja23 (dyskusja) 00:30, 15 lut 2018 (CET)
- Przeglądarka klienta nic nie będzie zaciągać ani nic linkować. W hasłach nie dodajecie żadnych szablonów. Pokrewne dodajesz na tej stronie. Strona będzie czytana tylko przez bota, który co noc skopiuje słowa z każdej rodziny do haseł z tej rodziny. Ok, jeśli niewygodnie w czytaniu, może być kilka stron, jak w tej angielskiej wersji. I to nie będzie dla całego języka, bo szczerze bym się zdumiał, gdyby komuś wystarczyło samozaparcia, żeby tam wpisać więcej niż kilkaset rodzin wyrazów. Wydaje mi się, że to realna propozycja, która z jednej strony zapewni spójność z obecnym systemem (bo w hasłach pokrewne będą dodane tylko na jeden sposób), a z drugiej strony pozwoli Wam dodawać łatwo te rodziny. Olaf (dyskusja) 00:35, 15 lut 2018 (CET)
- Może to wygodne dla bota, ale koszmarne dla człowieka. Jak mam sprawdzić na takiej stronie, czy słowo lub rodzina już istnieje? Jak korygować błędy? Jak pracować grupowo? --- ZojaZoja23 (dyskusja) 00:40, 15 lut 2018 (CET)
- Zróbcie na początek te rodziny dla najpopularniejszych słów, np. stąd, w końcu jeśli któreś hasła powinny być najlepiej opracowane, to te najpopularniejsze. Dane hasło nie musi istnieć, bot je doda do pokrewnych w przyszłości, kiedy ono powstanie. Opracujcie rodziny dla najpopularniejszych słów, a reszta będzie automatyczna.Olaf (dyskusja) 02:25, 15 lut 2018 (CET)
- Może to wygodne dla bota, ale koszmarne dla człowieka. Jak mam sprawdzić na takiej stronie, czy słowo lub rodzina już istnieje? Jak korygować błędy? Jak pracować grupowo? --- ZojaZoja23 (dyskusja) 00:40, 15 lut 2018 (CET)
- Przeglądarka klienta nic nie będzie zaciągać ani nic linkować. W hasłach nie dodajecie żadnych szablonów. Pokrewne dodajesz na tej stronie. Strona będzie czytana tylko przez bota, który co noc skopiuje słowa z każdej rodziny do haseł z tej rodziny. Ok, jeśli niewygodnie w czytaniu, może być kilka stron, jak w tej angielskiej wersji. I to nie będzie dla całego języka, bo szczerze bym się zdumiał, gdyby komuś wystarczyło samozaparcia, żeby tam wpisać więcej niż kilkaset rodzin wyrazów. Wydaje mi się, że to realna propozycja, która z jednej strony zapewni spójność z obecnym systemem (bo w hasłach pokrewne będą dodane tylko na jeden sposób), a z drugiej strony pozwoli Wam dodawać łatwo te rodziny. Olaf (dyskusja) 00:35, 15 lut 2018 (CET)
- Jedna ogromna strona dla całego języka? To będzie koszmar edycyjny – niewygodny, tworzący konflikty edycji i błędy kodu, gdy przeglądarka klienta nie zaciągnie całego kodu. -- ZojaZoja23 (dyskusja) 00:30, 15 lut 2018 (CET)
- Myślę, że można podejść na razie do tego cząstkowo. Potem, albo wola tworzących się wykruszy, albo zbierze się swoista masa krytyczna, gdzie takie zmiany będzie można wprowadzić jako normę. Ważne by stworzyć odpowiednią bazę wyrazów (Ciekawe jak przewidują to Wikidane). Nie mogę znaleźć tego przykładu, a widziałem go na francuskim wikisłowniku, w którym stworzono tabelę przedstawiającą możliwe złożenia rdzenia ze zrostkami. Takich „standardowych” przypadków mamy dużo: owce, izmy, owania, nienie, bezy, ości itp. Okcydent (dyskusja) 01:24, 15 lut 2018 (CET)
- A to jest jakiś niezależny pomysł i chyba mogę to zrobić automatem dla całej polszczyzny na WS a także przyszłych haseł. Jeśli na przykład bot zobaczy czasownik kończący się na -ać, sprawdza czy istnieje rzeczownik z tym samym tematem, kończący się na -anie i jeśli tak, to łączy te hasła w pokrewnych. To powinno być bezpieczne, bo w wypadku jakichś wyjątków, gdy nie da się tego utworzyć, nie powstanie odnośne hasło. Tylko trzeba by wyprodukować zbiory takich końcówek. Olaf (dyskusja) 02:25, 15 lut 2018 (CET)
- Ale moja dotyczy czego innego - utworzenia rodzin na jednej oddzielnej stronie, np. Wikisłownik:Rodziny pokrewnych dla języka polskiego, bez linkowania z artykułów. Nie chcę tworzyć osobnej przestrzeni nazw, ani setek artykułów dublujących sekcję pokrewne. Jedynym celem istnienia strony byłoby jej codzienne czytanie przez bota i dorzucanie przez niego pokrewnych do tych artykułów, a nie bezpośrednie czytanie przez użytkowników słownika. Zrób taką stronę, najlepiej w podobnym formacie jak ta angielska, ja to oprogramuję. Olaf (dyskusja) 00:24, 15 lut 2018 (CET)
- Olaf, no właśnie tego de facto dotyczy moja propozycja – utworzenia rodzin w odrębnej przestrzeni nazw. ZojaZoja23 (dyskusja) 00:17, 15 lut 2018 (CET)
- A uporządkujmy i uściślijmy definicję pokrewnych. Częściowo to już tu zrobiono wyłączając z pokrewnych wyrazy złożone – "deskorolka" wypada z pokrewnych wyrazu "deska" i "rolka" tworząc własną grupę ze słowami "deskorolkarz" i "deskorolkowy". Wtedy okaże się, że pokrewne w ramach jednego języka, tworzą rozłączne zbiory. Wątpliwości mogą się pojawić, ale będzie to marginalna skala no i zadziałać musi wtedy myślenie i człowiek. Dlatego moja propozycja jest odpowiedzią na to, czego niestety botem nie zrobisz. Hasło w przestrzeni "Pokrewne" tworzyć będą ludzie. Bot mógłby zająć się podpinaniem ich pod odpowiednie hasła, chociaż jak przypuszczam, można to będzie oprogramować jeszcze prościej. - ZojaZoja23 (dyskusja) 23:56, 14 lut 2018 (CET)
- W przypadku stworzenia tego lub podobnych mechanizmów powstanie automat do powielania błędów. Tak jest np. na ru.wiktionary.org. Są tam bloki wyrazów z tym samym „rdzeniem”, czy raczej tym, co rdzeniem się wydaje danemu edytorowi. Na stronie danego hasła ten blok jest domyślnie ukryty, podejrzenie zawartości wymaga od czytelnika pewnego wysiłku, czyli kliknięcia. Myślę, że nasz wysiłek powinniśmy najpierw skierować na zatomatyzowanie wstawiania etymologii na podstawie jakiegoś wiarygodnego, współczesnego źródła. Nie ma mowy o orzekaniu o pokrewieństwie wyrazów bez zajęcia się etymologią. Inaczej będziemy mieli piekło pokrewne z piekarnikiem i piecem albo krzyż - z krzyżmem. Róbcie jak uważacie, myślę, że docelowo w ogóle można zrezygnować z żywych edytorów. Pozdrawiam. Sankoff64 (dyskusja) 08:16, 15 lut 2018 (CET)
- Reagujesz chyba nieco za ostro. Nikt tu nie mówi o zastąpieniu edytowania przez automaty. A wracając do meritum: wydzielenie pokrewnych do osobnej przestrzeni pozwoli na lepszą ich kontrolę i korygowanie znalezionego błędu w jednym miejscu, a nie w dziesięciu. --- ZojaZoja23 (dyskusja) 11:46, 15 lut 2018 (CET)
- Tak, wikisłownik rosyjski po pewnymi względami jest patologiczny. Hurtowe importy z Wikipedii, niewytłumaczone hasła. Braki cytatów. Jest tego na tyle dużo, że jego sztuczność potrafi bić w oczy - projekt automatów dla automatów. Ale my też mamy sporo importów automatycznych, które wytłumaczone są jednym słowem polskim, które samo ma kilka znaczeń. Czy z tego nie można wyprowadzić zasady zakazującej tworzenia artykułów obcojęzycznych bez stworzenia artykułu polskiego?
- Z tego co przedstawiłeś, stworzenie rodzin to problem niemal równoważny stworzeniu właściwej etymologii i w szerszym ujęciu się nie wyklucza. To byłby jeden z chyba większych projektów etymologicznych. Mniej problematyczne są pewne szeregi wyrazów: przymiotnik + rzeczownik-ość (+ przysłówek) + (bez-)przymiotnik +(nie-)przymiotnik; miasto-(rzeka)-mieszkaniec-mieszkanka-przymiotnik-(podmiejski)-(miejskość)-(mieszkaniec miasta-państwa)-(mieszkanka miasta-państwa); czasownik i odczasownik; Zdaję sobie sprawę, że całkowicie bazodanowy projekt Omegawiki raczej nie zdobył zbyt wielu użytkowników, a to już pewnie któraś iteracja podejścia do problemu (a podobną rzecz pewnie będą chciały zrobić Wikidane).
- Wreszcie, jaki masz pomysł na przetworzenie etymologii? Okcydent (dyskusja) 11:31, 15 lut 2018 (CET)
- @Okcydent. Nic nie jest proste, ani oczywiste. Istnieje np. u nas od dawna uzus, żeby wyrazy zaprzeczone (z nie-) wydzielać do odrębnych rodzin wyrazowych - poszukaj w archiwum Baru i na stronach dyskusji, jest na ten temat dużo materiału. Rzeczowniki z -ościami, określające cechę mogą być wyrazami czysto potencjalnymi, nie występującymi w żadnym innym słowniku. Żeby istniał rzeczownik określający cechę, musi też istnieć przymiotnik jakościowy dotyczący tej cechy (ktoś tu kiedyś powtarzał, że „wyraz musi zasłużyć na miano przymiotnika jakościowego”) Jedną z naszych zasad jest weryfikowalność (wyraz musi być wzmiankowany w jakimś źródle słownikowym). Problem jest też z przysłówkami, duża część z nich będzie także wyrazami potencjalnymi. Słyszałeś o wyrazie „abidżańsko” lub „warciańsko”? A przyjmując proponowaną automatyczną metodę, takie twory będą się pojawiać, narażając nasz projekt na śmieszność i docinki. Pozdrawiam. Sankoff64 (dyskusja) 13:22, 15 lut 2018 (CET)
- Skoro tak rozdzierasz szaty nad weryfikowalnością, napisz nam tutaj, przeciętnie w ilu edycjach na sto, sam wstawiasz przypis do papierowego słownika, hę? ---- ZojaZoja23 (dyskusja) 19:17, 15 lut 2018 (CET)
- Pytanie to jest nie na temat. (Zwłaszcza że sam kilka wypowiedzi wyżej sam wspomniałeś, że nawet powiązana kwestia rozmiarów sekcji pokrewnych jest nie na temat). PiotrekDDYSKUSJA 19:31, 15 lut 2018 (CET)
- Skoro tak rozdzierasz szaty nad weryfikowalnością, napisz nam tutaj, przeciętnie w ilu edycjach na sto, sam wstawiasz przypis do papierowego słownika, hę? ---- ZojaZoja23 (dyskusja) 19:17, 15 lut 2018 (CET)
- @Okcydent. Nic nie jest proste, ani oczywiste. Istnieje np. u nas od dawna uzus, żeby wyrazy zaprzeczone (z nie-) wydzielać do odrębnych rodzin wyrazowych - poszukaj w archiwum Baru i na stronach dyskusji, jest na ten temat dużo materiału. Rzeczowniki z -ościami, określające cechę mogą być wyrazami czysto potencjalnymi, nie występującymi w żadnym innym słowniku. Żeby istniał rzeczownik określający cechę, musi też istnieć przymiotnik jakościowy dotyczący tej cechy (ktoś tu kiedyś powtarzał, że „wyraz musi zasłużyć na miano przymiotnika jakościowego”) Jedną z naszych zasad jest weryfikowalność (wyraz musi być wzmiankowany w jakimś źródle słownikowym). Problem jest też z przysłówkami, duża część z nich będzie także wyrazami potencjalnymi. Słyszałeś o wyrazie „abidżańsko” lub „warciańsko”? A przyjmując proponowaną automatyczną metodę, takie twory będą się pojawiać, narażając nasz projekt na śmieszność i docinki. Pozdrawiam. Sankoff64 (dyskusja) 13:22, 15 lut 2018 (CET)
- Wracając do pierwotnego pomysłu z tego wątku to jestem przeciwny rozbijaniu edycji hasła na dwie i więcej stron i komplikowaniu wikiskładni nowymi mechanizmami. To tylko zwiększałoby barierę wejścia nowym użytkownikom. Mówiąc o nowych nie mam na myśli 23 kont założonych ostatnio przez jedną osobę, co powoduje, że ciężko podchodzić serio do działań tej osoby. KaMan (dyskusja) 18:05, 15 lut 2018 (CET)
- Brawo, nie ma to jak argumentowanie w stylu "nie masz racji bo masz wszy na pępku". ZojaZoja23 (dyskusja) 19:17, 15 lut 2018 (CET)
- Podałem bardzo wyraźny argument przeciw. KaMan (dyskusja) 19:34, 15 lut 2018 (CET)
- Brawo, nie ma to jak argumentowanie w stylu "nie masz racji bo masz wszy na pępku". ZojaZoja23 (dyskusja) 19:17, 15 lut 2018 (CET)
- Odpowiem na uwagę wyżej. Z mojego punktu widzenia ten pomysł jest związany właśnie z rozpychaniem pola pokrewnych. Jeśli pominąć tę kwestię, to mówimy o skomplikowaniu edytowania haseł poprzez wyrzucenie ich części poza samo hasło, czemu jestem przeciwny. Zgadzam się pod tym względem z KaManem. PiotrekDDYSKUSJA 19:06, 15 lut 2018 (CET)
- PS: Im bardziej czytam ten wątek, tym bardziej skłaniam się ku zdaniu Sankoffa.
- Argument KaMana o niekomplikowaniu edytowania, szczególnie nowicjuszom, uważam za bardzo istotny. Nostrix (dyskusja) 21:52, 15 lut 2018 (CET)
rzeczowniki odczasownikowe
Jakiś czas temu pojawiły się masowe edycje jednego z naszych anonimowych Kolegów, dotyczące tworzenia haseł o rzeczownikach odczasownikowych. Pojawił się wniosek o równie masowe usunięcie tych haseł ze względu na brak prawdziwej definicji (o charakterze opisowym z podziałem na poszczególne znaczenia). Duża część haseł zawierała odesłania do redlinków albo stanowiła wyrazy potencjalne. W drodze głosowania ustaliliśmy, że hasła te nie zostaną usunięte, ale wdrożone zostaną zmiany w naszych zasadach. Zasady zostały zmienione. Pozostał problem z całym ogromem haseł wcześniej wprowadzonych, które do tej pory nie zostały poprawione wg znowelizowanych zasad. Wydawało mi się, że stopniowo przy zaangażowaniu większej liczby edytorów w ciągu kliku miesięcy uda się to „posprzątać”. Jednak do tej pory tylko niewielka część tych haseł została poprawiona. Moja propozycja jest taka: 1) hasła z odesłaniem do redlinków w definicji hurtowo usunąć; 2) pozostałe hasła zredagowane metodą „rzecz. odczas. od: pieprzyć” opatrzyć komentarzem, że hasło wymaga dopracowania poprzez itd. etc. Zrealizowanie tego zadania wymaga udziału kogoś, kto posiada uprawnienia do obsługi bota. Pozdrawiam. Sankoff64 (dyskusja) 13:02, 15 lut 2018 (CET)
- Popieram. PiotrekDDYSKUSJA 15:50, 15 lut 2018 (CET)
- Popieram pkt 2. Co do pkt. 1 mam mieszane uczucia. Czerwone linki to normalny tryb rozwoju wiki. W węgierskim powstaje wiele haseł z czerwonym linkiem w polskim znaczeniu i wszystko jest w porządku. Wolałbym kasowanie tylko tych na 100% potencjalnych ale nie wiem jak to sprawnie sprawdzić. KaMan (dyskusja) 18:15, 15 lut 2018 (CET)
- @KaMan: No tak, ale w niegdysiejszym głosowaniu wielką szansę miała opcja, aby skasować hurtem wszystko, zarówno z redlinkami, jak i bez nich. Wybrane zostało rozwiązanie kompromisowe, wynikające z milczącego założenia, że z czasem stopniowo wszystkie hasła zostaną dostosowane do przegłosowanych zasad. Problem z redlinkami w opisie znaczenia wyrazu sprowadza się do tego, że hasło nie zawiera jednego absolutnie niezbędnego składnika, jakim jest definicja. Nie można tłumaczyć nieznanego pojęcia przy pomocy innego nieznanego pojęcia. Dalsze pozostawanie tych haseł w masowej liczbie może błędnie sugerować nowych użytkownikom, że tak jest właśnie norma, i tak właśnie należy edytować hasła. Sankoff64 (dyskusja) 09:21, 16 lut 2018 (CET)
- …i może wywoływać wrażenie, że w Wikisłowniku nie ma niczego przydatnego, tylko takie nieprzydatne, sztucznie utworzone hasła, a tym samym zniechęcać do projektu. PiotrekDDYSKUSJA 09:49, 16 lut 2018 (CET)
- @KaMan: No tak, ale w niegdysiejszym głosowaniu wielką szansę miała opcja, aby skasować hurtem wszystko, zarówno z redlinkami, jak i bez nich. Wybrane zostało rozwiązanie kompromisowe, wynikające z milczącego założenia, że z czasem stopniowo wszystkie hasła zostaną dostosowane do przegłosowanych zasad. Problem z redlinkami w opisie znaczenia wyrazu sprowadza się do tego, że hasło nie zawiera jednego absolutnie niezbędnego składnika, jakim jest definicja. Nie można tłumaczyć nieznanego pojęcia przy pomocy innego nieznanego pojęcia. Dalsze pozostawanie tych haseł w masowej liczbie może błędnie sugerować nowych użytkownikom, że tak jest właśnie norma, i tak właśnie należy edytować hasła. Sankoff64 (dyskusja) 09:21, 16 lut 2018 (CET)
- Uważam, że masowe usuwanie stron nie jest dobrym rozwiązaniem. Dlaczego dodanie komentarza "hasło wymaga dopracowania" nie mogłoby dotyczyć także stron z redlinkowymi definicjami? Poza tym: redlinki w definicjach dotyczą nie tylko rzeczowników odczasownikowych, ale także niektórych: przysłówków, przymiotników (zwłaszcza od nazw geograficznych) oraz czasowników (definicja typu aspekt dokonany od...). Zetzecik (dyskusja) 21:56, 17 lut 2018 (CET)
- @Zetzecik: Przypomnę historię tych edycji. W czerwcu 2015 r. jeden użytkownik z kilku IP w ciągu kilku nocy wygenerował kilka tysięcy haseł. Wywołana została duża dyskusja, a pierwsza propozycja brzmiała - wszystko skasować. Sam byłem przeciwko kasowaniu nie chcąc niweczyć czyjejś pracy i naiwnie sobie wyobrażając, że po zmianie zasad nasza społeczność, w tym sam autor edycji, stosunkowo szybko poprawią te hasła. Byłem naiwny, nic takiego się nie stało, mało tego klony tych haseł, mimo wyników głosowania i ustalenia nowych zasad, nadal się pojawiały. Prawie trzy lata nie starczyły, żeby chociaż zamieścić uwagę o potrzebie naprawienia hasła? Nikt nikomu nie broni naprawiać tych haseł i usuwać „eków”. Najlepiej jednak nic nie robić, ani nie usuwać haseł w trybie ekspresowym, ani nie dokonywać ich naprawy. Sankoff64 (dyskusja) 23:08, 17 lut 2018 (CET)
-OŚCI - rzeczowniki polskie określające cechę
Zwróciliście zapewne uwagę na masowy wysyp edycji rzeczowników polskich kończących się na „-ość” a dotyczących jakiejś cechy określanej przymiotnikiem. Definicja sprowadza się do np. takiej frazy: „cecha tego, co jest arbitralne; cecha tych, którzy są arbitralni”. Niektórym nawet się spodobały te edycje. Przyjęta metoda rzeczywiście pozwala szybko wypełnić braki i stworzyć całą masę haseł w języku polskim. Istnieje jednak kilka problemów, na które chciałbym zwrócić uwagę. Pierwszy, to fakt, że w niektórych przypadkach nie zostało stworzone hasło przymiotnikowe, nasz Czytelnik odsyłany jest więc donikąd. Zagląda np. do hasła świergotliwość, charakterność itd., klika na wyraz „świergotliwy”, „charakterny”, a tu pojawia się komunikat systemowy: „Tworzenie charakterny. Strona nie istnieje”. Robimy więc naszego Czytelnika w bambuko, on szuka definicji, bo np. ma pilną pracę domową do odrobienia, a my każemy mu edytować. Drugi problem, to niebezpieczeństwo błędnego koła w parach rzeczownik-przymiotnik. Nie sprawdzałem, ale wielokrotnie może się zdarzyć, że w haśle rzeczownikowym będzie „cecha tego, co jest abecedualne”, w haśle przymiotnika „abecedualny”, będzie definicja o treści „świadczący o abecedualności”. Trzecia kwestia to podział na znaczenia. Jeżeli już autor edycji przyjął zasadę dwuczłonowej definicji to warto, aby podzielić ją na dwa znaczenia. Ułatwi to dodawanie synonimów, hiperonimów, hiponimów, inne będą kolokacje, stworzy też podstawę do sensownego dodawania tłumaczeń. To tak na początek ewentualnej dyskusji, jeżeli kogoś ten wątek zainteresuje. Pozdrawiam. Sankoff64 (dyskusja) 10:27, 16 lut 2018 (CET)
- Tylko zaznaczę, że "oszukujemy" swoich Czytelników także przy wyrazach obcojęzycznych, gdzie odsyłamy ich do nieistniejących polskich. W skrajnym przypadku wytłumaczenie nie istnieje i jest słowem mającym tylko zmieniona końcówkę w stosunku do słowa, które tłumaczy. Okcydent (dyskusja) 11:17, 16 lut 2018 (CET)
- Moja uwaga dotyczyła tylko haseł polskich. W hasłach obcojęzycznych redlink w tłumaczeniu na polski nie stanowi żadnego błędu. Sankoff64 (dyskusja) 11:42, 16 lut 2018 (CET)
- O utworzonych (pół)automatycznie hasłach o -ościach odsyłających do nieistniejących haseł o przymiotnikach mam takie zdanie jak o hasłach, o których mowa w poprzedniej sekcji – usunąć. Powody też wyżej. Pozdrawiam, PiotrekDDYSKUSJA 20:28, 16 lut 2018 (CET)
- PS: O możliwości tworzenia wspomnianych przez Sankoffa pętli też pomyślałem i też się tego obawiam; nie chciałem o tym wspominać, by nie podsuwać pomysłów.
- Uważam, że masowe usuwanie stron nie jest dobrym rozwiązaniem.
- Pozwolę sobie zacytować też @KaMana: "Czerwone linki to normalny tryb rozwoju wiki".
- Zastanawia mnie rozbijanie dwuczłonowej definicji na dwa znaczenia (dwie definicje). Czy dobrze rozumiem? Czy przymiotnik warszawski (=właściwy Warszawie, związany z Warszawą, pochodzący z Warszawy) miałby analogicznie mieć 3 definicje? Zetzecik (dyskusja) 22:22, 17 lut 2018 (CET)
- Chodziło o dwuczłonowe definicje rzeczowników odprzymiotnikowych, kiedy jeden człon definicji dotyczy cechy czegoś, co jest jakieś, drugi zaś - cechy kogoś, kto jest jakiś. W takim przypadku uważam, że należałoby definicję podzielić na dwa znaczenia. Co do przykładu z Warszawą, to tam mamy do czynienia z przymiotnikiem relacyjnym, nie podlegającym stopniowaniu i jakościowym, który się stopniuje opisowo („właściwy, charakterystyczny dla Warszawy” - np. „warszawski akcent”). Uważam też, że zanim ktoś zacznie tysiącami wprowadzać jakieś hasła przy użyciu szablonu, to nie zaszkodziłoby ten szablon poddać dyskusji. Nie proponowałem masowego usuwania rzeczowników odprzymiotnikowych - tu nigdy nie było głosowania w sprawie masowych szablonowych definicji, propozycja ta dotyczyła poprzedniego wątku dyskusji. Pozdrawiam. Sankoff64 (dyskusja) 22:49, 17 lut 2018 (CET)
Indeksy / lista wszystkich haseł specjalistycznych w danym języku
Dawno temu dodałem sobie do obserwowanych Indeks:Polski - Chemia mając nadzieję, że wszystkie polskie hasła chemiczne będę miał w jednym miejscu. Teraz patrzę, że te strony są od dawna nieaktualizowane i żaden z nich pożytek, a operator bota raczej nie będzie tego dalej aktualizował, bo opuścił (nie tylko ten) projekt. Jest może inny sposób, aby osiągnąć to samo? Automatycznych kategorii widzę, że nie ma. Wostr (dyskusja) 23:50, 27 lut 2018 (CET)
- @Wostr: strona ta jest częścią projektu Wikipedysta:Beau.bot/indeksy, kod znajduje się tutaj. Chciałem go kiedyś wznowić, przy okazji też udoskonalić, lecz zabrakło czasu (chyba omawiałem ten pomysł z @PiotrekD). Jeżeli nic się nie ruszy, proszę mi przypomnieć za 2-3 tygodnie :). Peter Bowman (dyskusja) 00:00, 12 mar 2018 (CET)
- O, świetnie ;) Będę przypominał w razie czego. Dzięki. Wostr (dyskusja) 01:53, 12 mar 2018 (CET)
- @Peter Bowman, nieśmiało przypominam ;) Wostr (dyskusja) 20:23, 21 kwi 2018 (CEST)
- Dzięki za przypomnienie, @Wostr :). Uruchomiłem kod Beau.bota na swoim koncie w serwerze WMF (wymagało to klika poprawek, które udostępniłem w swoim forku), listy zostały zaktualizowane, ustawiłem automat co sobotę w godzinach porannych (czyli jak dawniej). Planowaną przeróbkę muszę odłożyć na kiedy indziej z braku czasu, choć nie jest to priorytetowe zadanie. Przy okazji sprawdzę stan drugiego skryptu Beau.bota – okresowe wstawianie plików wymowy – może też da się prosto wskrzesić. Umieszczam z tej okazji wzmiankę na TO. Pozdrawiam, Peter Bowman (dyskusja) 22:27, 22 kwi 2018 (CEST)
- Dziękuję bardzo :) Wostr (dyskusja) 10:02, 23 kwi 2018 (CEST)
- Dzięki za przypomnienie, @Wostr :). Uruchomiłem kod Beau.bota na swoim koncie w serwerze WMF (wymagało to klika poprawek, które udostępniłem w swoim forku), listy zostały zaktualizowane, ustawiłem automat co sobotę w godzinach porannych (czyli jak dawniej). Planowaną przeróbkę muszę odłożyć na kiedy indziej z braku czasu, choć nie jest to priorytetowe zadanie. Przy okazji sprawdzę stan drugiego skryptu Beau.bota – okresowe wstawianie plików wymowy – może też da się prosto wskrzesić. Umieszczam z tej okazji wzmiankę na TO. Pozdrawiam, Peter Bowman (dyskusja) 22:27, 22 kwi 2018 (CEST)
- @Peter Bowman, nieśmiało przypominam ;) Wostr (dyskusja) 20:23, 21 kwi 2018 (CEST)
- O, świetnie ;) Będę przypominał w razie czego. Dzięki. Wostr (dyskusja) 01:53, 12 mar 2018 (CET)
Terminy obce
Czy istnieje jakaś spójna wykładnia dotycząca terminów obcych w polszczyźnie, w szczególnym przypadku takich jak manchesterski, lüneburski. Rdzeń jest niewątpliwie obcy, ale jako całość to przecież wynik czysto polskiego słowotwórstwa. @KaMan napisał mi że stosuje zasadę odmienności zapisu od polskiej wymowy i takie wyrazy klasyfikuje jako terminy. Co w takim razie powinno się stać z rodziną słowa sinus. Pozdrawiam. Okcydent (dyskusja) 20:38, 29 mar 2018 (CEST)
- Słowa manchesterski, lüneburski nie są obcymi terminami – nie występują w żadnym obcym języku. Tu sprawa jest jasna. -- ZojaZoja23 (dyskusja) 23:29, 12 kwi 2018 (CEST)
- Z drugiej strony w języku polskim z reguły nie wymawiamy "ch" jako "cz", a w naszym alfabecie nie występują niemieckie umlauty. Sankoff64 (dyskusja) 10:28, 13 kwi 2018 (CEST)
Oboczności w dopełniaczu liczby mnogiej i nie tylko
Powiązane: Specjalna:Diff/6171401, Specjalna:Diff/6171406, WS:Bar/Archiwum 18#Dopełniacz liczby mnogiej.
Zauważyłem, że nie mamy konkretnych spisanych ustaleń dotyczących podawania oboczności w tabelach odmiany, co skutkuje niespójnością. Dlatego chciałbym ustalić kilka kwestyj, o których dalej.
- Czy kwalifikatory opisujące formy odmiany należy stawiać przed formą czy po niej? Dotychczas standardem było dodawanie ich przed nią, ale Okcydent jest za dodawaniem ich po niej i tak też ostatnio robi.
- Czy formy fleksyjne umieszczamy w jednej linii, oddzielając je ukośnikiem, czy w oddzielnych liniach? Niegdyś standardem było to pierwsze, jakiś czas temu zaczęło pojawiać się to drugie.
- Czy używamy kwalifikatorów {{char}} i {{nchar}} jak {{SGJPonline}} i {{WSJPonline}}?
- Czy formy charakterystyczne dopełniacza liczby mnogiej -ij/-yj słów zakończonych na -ia/-ja ze słyszalnym j i -ii/-ji w dopełniaczu liczby pojedynczej traktować jako przestarzałe?
- Utworzenie szablonu do automatycznego odmieniania ww. słów, jako że odmiana jest całkowicie regularna. (Pozostaje kwestia liczby mnogiej, por. {{nieodm-rzeczownik-polski}}).
Moje opinie są następujące
- Uważam, że kwalifikatory do form powinny być umieszczane przed formami odmiany, tak jak było robione dotychczas. Odpowiada to sposobowi opisywania kwalifikatorami definicyj, jak i temu, że przydawki przymiotne w języku polskim zwykle występują przed słowami, do których się odnoszą.
- Nie mam opinii. Tabelka wygląda wedle mnie ładniej, gdy formy są w oddzielnych liniach, natomiast umieszczenie w takiej sytuacji przypisu na samym końcu powoduje we mnie wrażenie, że odnosi się tylko do drugiej formy, ale może to tylko u mnie. Nie wiem też w sumie, czy ma to jakiekolwiek znaczenie. Jestem neutralny.
- Jestem zdecydowanie przeciwny tym kwalifikatorom. Zajmują miejsce, od strony normatywnej nic nie wnoszą, a dla zdecydowanej większości czytelników są całkowicie niejasne, natomiast ci, którzy wiedzą, o co chodzi, i tak od razu zauważą, która forma jest którą. Sprzeciwiam się przeładowywaniu haseł kwalifikatorami, uważam, że ich nadmiar powoduje bałagan i utrudnia odbiór treści. (Swoją drogą – jak ładnie byście wytłumaczyli to rozróżnienie np. uczniom?).
- Sądzę, że należy. Nawet nie chce mi się na ten temat tutaj teraz rozpisywać, jeśli mam być szczery. Krótko wspomniałem dziś o tym tutaj.
- Popieram. Nawet głównie nie dlatego, że dzięki temu skrócimy hasła o powtarzalny element, choć to też jest faktem. Dlatego że odmiana ta byłaby spójna, a gdyby kto kiedy zechciał zmienić ustalenia w wyżej wymienionych sprawach, to wymagało by to zmienienia jednej strony, nie kilkuset. Od strony technicznej – końcówki wszystkich przypadków są takie same z wyjątkiem formy charakterystycznej dopełniacza liczby mnogiej, który może mieć w zależności od poprzedniej spółgłoski -ij albo -yj.
Cóż, zachęcam serdecznie do dyskusji i ustalenia, jak to ma wyglądać. A teraz nieeleganckie pinganko: @Okcydent, @Sankoff64, @Peter Bowman, @Krokus, @KaMan, @Zetzecik, @Richiski, @Ming. PiotrekDDYSKUSJA 21:29, 14 kwi 2018 (CEST)
- całkowicie zgadzam się ze zdaniem Piotrka we wszystkich punktach KaMan (dyskusja) 09:54, 15 kwi 2018 (CEST)
- Co do dwóch pierwszych punktów tylko. Jestem za podziałem na linie, gdyż lepiej wygląda i jest po prostu czytelniejszy (jeśli oczywiście nie przytrafi się jakiś podział fraz). Umieszczenie kwalifikatorów po prawej pozwala wyrównać wszystkie wiersze w kolumnie do lewej, Gdy umieścimy go po prawej to albo godzimy się na rozsunięcie, albo przed wszystkimi wierszami dajemy odstęp równy najdłuższemu zestawowi kwalifikatorów (czyli de facto kolejną kolumnę). Rozwiązanie prawostronne najmniej zachodu wymagało.
- Co do szablonów zaś to o ile popieram ich użycie. Sam jednak dość słabo ogarniam wikikod.
- PS: Czy dałoby się wprowadzić szablon {{r|nazwa cytatu}} z Wikipedii? Znacznie uporządkowałby cytowanie?
- Okcydent (dyskusja) 09:11, 16 kwi 2018 (CEST)
- @Okcydent: Technicznie – dałoby się, ale nawet na wspomnianej, bardziej biurokratycznej od nas, Wikipedii prowadzone są boje dotyczące użyteczności tego szablonu, czy na pewno on wprowadza porządek, czy może bałagan, czy ułatwia edytowanie haseł, czy mąci. Ja byłbym przeciwny wprowadzaniu go tutaj. Obecnie mamy jeden system, który jest, jaki jest, ale jest jeden, i to w sumie w miarę prosty (początkującemu wystarczy
<ref>przypis</ref>bezpośrednio w danym miejscu i najlepiej<references />na końcu; to drugie doda w ciągu doby bot Olafa, jeśli nie będzie); przypisu co drugie słowo nie stawiamy. Pozdrawiam, PiotrekDDYSKUSJA 16:04, 16 kwi 2018 (CEST)
- @Okcydent: Technicznie – dałoby się, ale nawet na wspomnianej, bardziej biurokratycznej od nas, Wikipedii prowadzone są boje dotyczące użyteczności tego szablonu, czy na pewno on wprowadza porządek, czy może bałagan, czy ułatwia edytowanie haseł, czy mąci. Ja byłbym przeciwny wprowadzaniu go tutaj. Obecnie mamy jeden system, który jest, jaki jest, ale jest jeden, i to w sumie w miarę prosty (początkującemu wystarczy
- Zgadzam się co do punktów 1, 3 i 4. Zgoda też co do drugiego, choć moduł sprawdzający poprawność form może wymagać przystosowania do nowego separatora (Moduł:odmiana, Moduł:odmiana-rzeczownik-polski-błędy). Piątka mnie nie przekonuje z tego powodu, że nawet regularny {{nieodm-rzeczownik-polski}} sprawiał problemy i wymagał coraz to nowych parametrów (zob. jego stronę dyskusji, proponowałem nawet scalenie go z {{odmiana-rzeczownik-polski}}). Pozdrawiam, Peter Bowman (dyskusja) 15:52, 17 kwi 2018 (CEST)
Chętnych do wypowiedzenia się nie widać. Może jakieś głosowanie? PiotrekDDYSKUSJA 21:56, 15 cze 2018 (CEST)
- @PiotrekD Ja mam tylko uwagę praktyczną, że jeśli będzie jakikolwiek import odmiany z pl.wiktionary do Wikidanych to każde odstępstwo od standardu będzie utrudnieniem, dlatego byłbym za tym by konsekwentnie kwalifikatory do form były przed, a nie po formach. Co do nowej linii to wydaje mi się to czytelniejsze niż przecinek (przecinek czasem przy związkach wyrazów może być częścią nazwy hasła). KaMan (dyskusja) 09:54, 18 cze 2018 (CEST)
- @KaMan: Dotąd obok oddzielania znakami nowej linii mieliśmy popularniejsze oddzielanie ukośnikami, oddzielania przecinkami nie widziałem, ale może już ktoś taką wersję zaczął wprowadzać do artów. Pozdrawiam, PiotrekDDYSKUSJA 12:26, 18 cze 2018 (CEST)
Tell us what you think about the automatic links for Wiktionary
Hello all,
(Sorry for writing in English. Feel free to translate this message below.)
One year ago, the Wikidata team started deploying new automatic interwiki links for Wiktionaries. Today, the links for the main namespace are automatically displayed by a Mediawiki extension, and the links for other namespaces are stored in Wikidata. You can find the documentation here (feel free to help translating it in your language).
We would like to know if you encountered problems with the system, if you would have suggestions for further improvements. This could be for example:
- Some automatic links don’t work as expected
- Some problems you encountered with entering links (for non-main namespace) in Wikidata
- Some new features you’d like to have, related to links
To give feedback, you have two options:
- Let a message on this talk page
- Let a message here. If you do so, please mention me with the {{ping}} template, so I can get a notification.
Our preferred languages are English, French and German, but you can also let a message in your own language if you feel more comfortable with it.
I’m looking forward for your feedback! Lea Lacroix (WMDE) 12:23, 24 kwi 2018 (CEST)
Pragmatyka a wykrzykniki (lub inne kryteria kategoryzacji)
Chciałbym tu poruszyć kwestię związaną z nowo utworzonymi hasłami „spływaj!”, „spływaj stąd” oraz „wyobraź sobie” (notabene pierwsze zawiera znak wykrzyknienia w tytule). Wszystkie występują w USJP. Autorzy tego słownika stosują oznaczenie fraz pot w celu kategoryzacji pierwszego hasła, u nas obecnie widnieje jako wykrzyknik. Równolegle do wątpliwości odnośnie kategorii gramatycznej tych słów i wyrażeń pojawia się pytanie co do możliwości zakwaliwikowania owych bytów jako proste formy fleksyjne odpowiednich haseł bazowych. Innymi słowy, wypada się zastanowić, czy nie zostały już odpowiednio opisane w hasłach „spływać” i „wyobrazić”.
Pozwolę sobie przekleić komentarz Richiskiego z mojej strony dyskusji (Specjalna:Diff/6178560):
- Nadal mam wątpliwości odnośnie skategoryzowania hasła spływaj! (co nie dotyczy hasła spływaj stąd). Zgodnie z definicją pojęcia fraza, to pierwsze nie mieści się w tej kategorii. Tutaj należałoby chyba mówić o aktach mowy, a nie o kategoriach, pozostawiając na boku arystotelowskie kryteria kategoryzacji. No ale to dyskusja na innym poziomie, która bardziej powinna się toczyć na terenie pragmatyki a nie gramatyki. BTW: porównajmy tak często używane - i w różnych kontekstach - hiszpańskie słowo venga. Samo umieszczenie tego wyrażenia w haśle czasownika venir zubożyłoby pole ekspresyjne (nie znaczeniowe) tego wyrażenia. Porównajmy dla przykładu takie dialogi: ¡date prisa, venga, que te están esperando! (przynaglenie); de acuerdo, venga, lo hablamos esta tarde - kończymy rozmowę telefoniczną. To tylko dwa pierwsze z rzędu przykłady. Jeżeli w WS nie umieścimy osobno hasła venga - które mimo że jest formą czasownika w lp, stosuje się też w kontekście zwracania się do wielu odbiorców - to nie wyczerpiemy kontekstów użycia tego słowa. Tyle na razie. Pozdrawiam --Richiski (dyskusja) 16:43, 30 kwi 2018 (CEST)
W wolnym tłumaczeniu (venga – forma czasownika venir, lecz czasem bliższy polskiej partykule no):
- ¡date prisa, venga, que te están esperando! – no, pośpiesz się, czekają na ciebie!
- de acuerdo, venga, lo hablamos esta tarde – dobra, porozmawiamy o tym po południu (bez odpowiednika?)
Co do obecności wykrzyknika w tytule strony, zauważyłem, że nie jest to odosobniony przypadek: quarry:query/26726. Znajdziemy też strony bez wykrzyknika, lecz w których tytuł sekcji zawiera ten znak: Wikipedysta:PBbot/nagłówki. Tu oryginalny wątek przepisany na nowo z powodu ataków osobistych. Pozdrawiam, Peter Bowman (dyskusja) 17:05, 4 maj 2018 (CEST)
Font nagłówkowy źle wyświetla grekę (1)
Vide → ἓν μόνον ἀγαθὸν εἶναι, τὴν ἐπιστήμην, καὶ ἓν μόνον κακόν, τὴν ἀμαθίαν. ZojaZoja23 (dyskusja) 22:09, 3 maj 2018 (CEST)
Lexicographical data is now available on Wikidata
Hello,
Sorry for writing in English. Feel free to translate the content of this message below.
After several years discussing about it, and one year of development and discussion with the communities, the development team of Wikimedia Germany has now released the first version of lexicographical data support on Wikidata.
Since the start of Wikidata in 2012, the multilingual knowledge base was mainly focused on concepts: Q-items are related to a thing or an idea, not to the word describing it. Starting now, Wikidata stores a new type of data: words, phrases and sentences, in many languages, described in many languages. This information will be stored in new types of entities, called Lexemes, Forms and Senses.
The goal of lexicographical data on Wikidata is to provide a structured and machine-readable way to describe words and phrases in multiple languages, stored in a same place, reusable under CC-0. In the near future, this data will be available for Wiktionaries and other projects to reuse, as much as you want to.
For now, we’re at the first steps of this project: the new data structure has been released on Wikidata, and we’re looking for people to try it, and give us feedback on what is working or not. Participating to this project is the opportunity for you to have a voice in it, to make sure that your needs and requests are taken in account very early in the process, and to start populating Wikidata with words in your language!
Here’s how you can try lexicographical data on Wikidata:
- First of all, if you’re not familiar with the data model, I encourage you to have a look at the documentation page. If you’re not familiar with Wikidata at all, I suggest this page as a start point.
- You can also look at the Lexemes that already exists (search features will be improved in the future).
- When you feel ready to create a word, go on d:Special:NewLexeme.
- If some properties that you need are missing, you can suggest them on this page (if you’re not sure how to do it, just let a message on the talk page and someone will help you).
- The main discussion page is d:Wikidata:Lexicographical data. Here, you can ask for help, suggest ways to organize the data, but also leave feedback: if you encounter any bug or issue, let us know. We’re looking especially to know what are the most important features for you to be worked on next.
In any case, feel free to contact me if you have a question or problem, I’ll be very happy to help.
Zastanawiam się, czy nie jest zasadnym rozdzielenie tego szablonu na dwa różne: mamy zarówno rzeczowniki, jak i przysłówki odprzymiotnikowe. W przypadku przysłówków klasyfikacja jest też istotna, albowiem „nie” z przysłówkami odprzymiotnikowymi piszemy łącznie, w pozostałych przypadkach rozłącznie.
Przy okazji chciałbym się zapytać o zakres stosowania istniejących szablonów {{odprzym}} i {{odrzecz}}. Czy należy je stosować przed definicjami np. w haśle robienie „(1.1) odczas. definicja” lub w haśle mobilnie „(1.1) odprzym. definicja”, czy wystarcza zapis w etymologii z zastosowaniem {{odczasownikowy od}} lub z omawianym w pytaniu pierwszym {{odprzymiotnikowy od}}? A jeśli nie stawiamy przed definicjami, to jakie jest ich przeznaczenie? Pozdrawiam serdecznie, Karol Szapsza (dyskusja) 18:47, 9 cze 2018 (CEST)
- Według zasad nie należy tego pisać w znaczeniach. Należy w nich podawać definicje. To może być w etymologii. Banana22100 (dyskusja) 22:22, 9 sie 2018 (CEST)
Przygoda z Wikidanymi
O ile dobrze się zorientowałem z historii edycji, na razie tylko Peter Bowman i ja (spośród wikisłownikowców) spróbowaliśmy edycji słownikowych w Wikidata (niekompletna lista dostępna jest tu: https://tools.wmflabs.org/ordia/language/pl). Zachęcam innych choćby po to by zobaczyć jak jeszcze długa droga przed Wikidanymi, zanim osiągną elastyczność Wikisłownika. Edycja na razie jest toporna, mozolne opisywanie wszystkich form uciążliwe. Z nowości podpowiem, że na mój wniosek utworzone zostały tam dwie własności, dla zapisu slawistycznego wymowy https://www.wikidata.org/wiki/Property:P5276 oraz do uźródławiania leksemów pozycjami w słowniku PWN https://www.wikidata.org/wiki/Property:P5274. Obie właśności do obejrzenia w haśle śmieć https://www.wikidata.org/wiki/Lexeme:L810 . Po pierwszych edycjach mam dwa pytania. Po pierwsze do @Olaf - w wikidanych wymowa przypisana jest do form słów, czy możliwe żeby bot Olafa generował wymowę dla wszystkich form na potrzeby Wikidanych? Po drugie w ogłoszeniu o wprowadzeniu leksemów do Wikidanych pojawił się fragment "We strongly encourage you to discuss with the communities before considering any import from the Wiktionaries. Wiktionary editors have been putting a lot of efforts during years to build definitions, and we should be respectful of this work, and discuss with them to find common solutions to work on lexicographical data and enjoy the use of it together." Co można przetłumaczyć jako "Nalegamy abyście przedyskutowali ze społecznościami przed rozważeniem jakiegokolwiek importu z Wikisłowników. Edytorzy Wikisłowników przez lata włożyli dużo wysiłku w budowanie definicji, i powinniśmy podejść z respektem do tej pracy, i przedyskutować z nimi aby znaleźć wspólne rozwiązanie przy pracy z danymi leksykograficznymi i cieszyć się ich użyciem wspólnie." Stąd moje drugie pytanie, czy ktoś ma coś przeciwko importowi danych z Wikisłownika do Wikidanych. AFAIK wszystkie importy dokonywane są z poszanowaniem licencji a projekt źródłowy oznaczany jest jako źródło przy wszelkich importach (tak to było do tej pory z Wikipedią, czy Wikispecies). Wydaje mi się że licencja nie daje nam władzy aby zabronić importu jeśli będzie on wykonywany zgodnie z licencją ale być może są jakieś inne przyczyny dla których ten import nie powinien nastąpić. Może potrzebne jest jakieś głosowanie? KaMan (dyskusja) 11:13, 11 cze 2018 (CEST)
- Można chyba inaczej zinterpretować ten drugi punkt: my sobie dyskutujemy wewnętrznie o właściwym kształcie polskich wyrazów i definicji w Wikidanych, a w międzyczasie jakiś bot przeniesie tam na przykład cały język polski z enwiktionary. Czyli może tu chodzić raczej o współpracę między Wikisłownikami, jak się nie gryźć podczas importowania informacji z tych samych haseł itd. W kwestii licencji powinien wystarczyć link do hasła w opisie edycji. Peter Bowman (dyskusja) 12:06, 11 cze 2018 (CEST)
- Faktycznie Olafbot mógłby wygenerować polską wymowę dla wszystkich form i wyeksportować ją do Wikidanych, o ile odmiana jest w Wikisłowniku. Główny problem to to, że nie mam tam uprawnień bota, więc taka masówka raczej by nie przeszła. A na wikidata:Wikidata:Requests for permissions/Bot są nawet nierozpatrzone jakieś zgłoszenia z początku 2017 roku. Nie mam też dużo czasu na programowanie ostatnio, więc tym bardziej to potrwa. No nic, spróbuję coś zakodować w miarę wolnego czasu i się tam pewnie zgłoszę po flagę bota. Jeśli chodzi o drugie pytanie – Problem przy importach i eksportach botem jest też taki, że zwykle słowa mają więcej niż jedno znaczenie. Dla większości wymowę, etymologię i odmianę można wtedy i tak przenosić między wersjami językowymi, ale już znaczeń i przykładów nie. Bawiłem się w ten sposób przy imporcie z en-wikt, dało się automatyczny import zrobić tylko dla tych słów, które miały jedno wybitnie dominujące znaczenie - lista takich słów po angielsku zidentyfikowanych przeze mnie jest tutaj. Więc pomijając wymowę, etymologię, odmianę i ewentualnie tę garstkę jednoznacznych, trzeba by eksport do Wikidata chyba robić ręcznie lub półautomatycznie. Olaf (dyskusja) 00:02, 12 cze 2018 (CEST)
- @Olaf wydaje mi się, patrząc czasem na OZ na Wikidata, że tam co drugi edytor jest botem. Edycje opisane jako #petscan lub #quickstatements są wykonywane w tempie kilkudziesięciu na minutę i jest to powszechne bez flagi bota. Np. tu: https://www.wikidata.org/w/index.php?title=Special:Contributions/Vojt%C4%9Bch_Dost%C3%A1l&offset=20180604140246&target=Vojt%C4%9Bch+Dost%C3%A1l tak więc myślę że pojęcie bota się trochę zmieniło w Wikidanych. KaMan (dyskusja) 13:25, 12 cze 2018 (CEST)
Do oznaczania form przestarzałych stworzyłem własność forma przestarzała (przykład użycia w komentacja), do oznaczania form potencjalnych stworzyłem własność forma potencjalna (przykład użycia w śmieć). Otworzyłem też głosowanie nad dodaniem identyfikatora do {{SGJPonline}} - https://www.wikidata.org/wiki/Wikidata:Property_proposal/SGJP_Online_ID - można w dyskusji wstawiać {{s}} jeśli wspieracie dodanie takiej własności w wikidata dla leksemów. Czy macie propozycje innych mechanizmów z naszego Wikisłownika do przeniesienia do Wikidata? Wydaje mi się że przydałyby się jeszcze identyfikatory do słownika ortograficznego i Doroszewskiego PWN. KaMan (dyskusja) 12:21, 13 cze 2018 (CEST)
Dodałem też forma deprecjatywna i forma niedeprecjatywna. Przykład użycia w Kot. Aktualna lista polskich leksemów na tej stronie. KaMan (dyskusja) 12:49, 14 cze 2018 (CEST)
Powstają już pierwsze narzędzia na bazie tej nowej leksykalnej funkcjonalności:
- https://lucaswerkmeister.github.io/wikidata-lexeme-graph-builder/?subjects=L3072&predicate=P5191 tak wygląda graficznie zobrazowana etymologia z naszego hasła Zuzanna (nieco bardziej rozbudowany przykład: https://lucaswerkmeister.github.io/wikidata-lexeme-graph-builder/?subjects=L4738&predicate=P5191 )
- pierwszy formularz do uproszczonego tworzenia leksemów https://tools.wmflabs.org/lexeme-forms/ jeśli uda się do niego dodać polski rzeczownik to będzie to podobne do tego co mamy w gadżecie wstawiania odmiany w pl.wiktionary. Dodanie przymiotników i czasowników zajmie więcej czasu.
KaMan (dyskusja) 10:03, 18 cze 2018 (CEST)
Narzędzie Wikidata Lexeme Forms obsługuje już podstawową formę polskiej odmiany rzeczownikowej. Można tworzyć rzeczowniki wraz z odmianą z pominięciem uciążliwego interfejsu Wikidanych. Przygotowanie nowych szablonów jest w tej aplikacji bardzo proste i sprowadza się do wyedytowania szablonu na wiki: takiego jak ten więc z pewnością wkrótce pojawią się następne. Jednocześnie zachęcam do dodawania głosów poparcia w dyskusji tej propozycji poprzez wstawienie {{s}} z podpisem. Będzie wtedy można uźródławiać pozycje w Wikidanych odmianami z sgjp.pl. KaMan (dyskusja) 09:58, 22 cze 2018 (CEST)
- Nie jestem w temacie Wikidanych, proszę tylko o niekomplikowanie edycji Wikisłownika, ale widzę, że ktoś wspomniał o etymologii. Otóż stanowczo sprzeciwiam się automatycznemu importowaniu etymologii z angielskiego WS. Jest to źródło niewiarygodne w tej kwestii (ba, ja twierdzę, że en.wikt to w ogóle bardzo słabe źródło w jakiejkolwiek kwestii). Bardzo często jest ona wymyślana przez jej użytkowników, domorosłych etymologów sprzed monitora, którzy nie potrafią swoich tez uźródłowić ni dokładniej uzasadnić nawet, gdy są proste. Pierwszy lepszy przykład. (Tutaj akurat ten edytor ma rację, potwierdzają to źródła, ale w ilu miejscach racji nie miał? Z tą akurat sprawą wiąże się mój błąd z wikisłownikowej młodości: kiedyś wierzyłem w en.wikt). Pozdrawiam, PiotrekDDYSKUSJA 22:16, 22 cze 2018 (CEST)
- Popieram nieimportowanie z angielskiego Wikisłownika :). Ogólnie jestem przeciwny automatycznym importom z tego projektu; dużo się namęczyłem i zajęło mi to mnóstwo czasu, aby zweryfikować zaimportowane słowa w j. katalońskim, a warto to było zrobić, bo wyłapałem ze 20 poważnych błędów merytorycznych (niestety nie spisałem ich sobie i teraz trudno mi podać konkretne przykłady). Mam nadzieję, że tak ogólnie nie będziemy już nic więcej importować automatycznie z angielskiego Wikisłownika :). Nostrix (dyskusja) 08:58, 26 cze 2018 (CEST)
- Dziękuję za głosy. Przekażę zastrzeżenia co do en.wikt. Rozumiem, że zastrzeżeń co do importu z pl.wikt nie ma (komplikowanie edycji Wikisłownika nie będzie jeśli Wikisłownik sobie tego sam nie zażyczy). KaMan (dyskusja) 10:01, 26 cze 2018 (CEST)
- Popieram nieimportowanie z angielskiego Wikisłownika :). Ogólnie jestem przeciwny automatycznym importom z tego projektu; dużo się namęczyłem i zajęło mi to mnóstwo czasu, aby zweryfikować zaimportowane słowa w j. katalońskim, a warto to było zrobić, bo wyłapałem ze 20 poważnych błędów merytorycznych (niestety nie spisałem ich sobie i teraz trudno mi podać konkretne przykłady). Mam nadzieję, że tak ogólnie nie będziemy już nic więcej importować automatycznie z angielskiego Wikisłownika :). Nostrix (dyskusja) 08:58, 26 cze 2018 (CEST)
Z nowości:
- narzędzie Wikidata Lexeme Forms zyskało drugi szablon do polskich rzeczowników, tym razem do tych z formami deprecjatywnymi w mianowniku i wołaczu liczby mnogiej
- narzędzie Wikidata Lexeme Graph Builder zyskało możliwość wyświetlania większej liczby właściwości jednocześnie (z rozróżnieniem kolorem) dzięki czemu na jednym grafie można łączyć właściwość etymologiczną z właściwością "złożony z" i uzyskać np. takie coś: https://lucaswerkmeister.github.io/wikidata-lexeme-graph-builder/?subjects=L5573&predicates=P5191%2CP5238
- na Wikidanych jest już 250 polskich haseł, m.in. te z czoła naszej listy frekwencyjnej
KaMan (dyskusja) 11:29, 9 lip 2018 (CEST)
- narzędzie Wikidata Lexeme Forms zyskało trzeci szablon do polskich rzeczowników, tym razem do tych z potencjalną liczbą mnogą
- pojawiła się właściwość https://www.wikidata.org/wiki/Property:P5455 do łączenia polskich haseł z odpowiednimi pozycjami w sgjp.pl. Przykład we wróblu: https://www.wikidata.org/wiki/Lexeme:L6845
- rozpoczęło się głosowanie nad utworzeniem właściwości dla słownika Doroszewskiego: https://www.wikidata.org/wiki/Wikidata:Property_proposal/Doroszewski_Online_ID
KaMan (dyskusja) 11:06, 16 lip 2018 (CEST) Kolejna porcja nowości:
- polskie hasło gepard posłużyło wczoraj jako wzorcowe w czasie prezentacji danych leksykograficznych na Wikimanii 2018
- dostępna jest już właściwość do łączenia ze słownikiem Doroszewskiego: https://www.wikidata.org/wiki/Property:P5497 Przykład użycia w kocie: https://www.wikidata.org/wiki/Lexeme:L369
- rozpoczęło się głosowanie nad utworzeniem właściwości dla słownika Kopalińskiego: https://www.wikidata.org/wiki/Wikidata:Property_proposal/Kopali%C5%84ski_Online_ID
- narzędzie Wikidata Lexeme Forms uzyskało nową funkcjonalność, można teraz tworzyć kilka form dla tych samych cech gramatycznych, wystarczy kolejne formy odzielić znakiem "/". Czyli wpisanie "odkurzaczy/odkurzaczów" spowoduje automatyczne utworzenie dwóch form z tymi samymi cechami.
KaMan (dyskusja) 09:32, 23 lip 2018 (CEST)
- liczba leksemów w Wikidanych osiągnęła 10.000 (w 264 językach)
- liczba leksemów polskich osiągnęła 500 (nasz język jest obecnie na 5. pozycji https://www.wikidata.org/wiki/Wikidata:Lexicographical_data/Statistics)
- dostępna jest już właściwość dla słownika Kopalińskiego https://www.wikidata.org/wiki/Property:P5533 przykład użycia w niklu https://www.wikidata.org/wiki/Lexeme:L7864
- rozpoczęło się głosowanie nad utworzeniem właściwości dla Wielkiego słownika ortograficznego PWN online https://www.wikidata.org/wiki/Wikidata:Property_proposal/WSO_Online_ID
KaMan (dyskusja) 18:29, 4 sie 2018 (CEST)
- Z ciekawości zajrzałem do Wikidanych i przez przypadek dodałem hasło "odkur". Generalnie miało być "odkurzacz", ale utworzenie "odkura" było dla mnie pierwszą wskazówką o tym jak trudnego podjąłem się wyzwa. Faktycznie dodanie pierwszego hasła jest trudne, ale do ogarnięcia. Jedyne co mnie uderza to to, że mam przepisywać tam rzeczy, które spokojnie może przepisywać bot, czyli link do SGJP, SJP PWN, Doroszewskiego, formy odmiany... Wprowadzanie tych danych przez człowieka według mnie jest po prostu bez sensu. Nie dość, że ludzie przez lata wprowadzali to w Wikisłowniku, to teraz jeszcze mieliby wprowadzać to samo w Wikidanych. No bo przykładów czy kolokacji nie dodamy (na tym etapie rozwoju Wikidanych). Zaczekam aż to się rozwinie. Teraz, uważam, robota jest machinalna i odmóżdżająca. // user:Azureus (dyskusja) 18:19, 10 sie 2018 (CEST)
- [edit] Chciałbym jeszcze dodać, że w pewnym stopniu podziwiam KaMana, któremu chce się tam pisać. Widać, że ewidentnie w to wierzy, choć na tym etapie ja akurat tego nie podzielam. Wikipedia ma wady, Wikisłownik również i Wikidane nie będą wyjątkiem. To będzie "coś", jednak obawiam się, że przez małe "c". // user:Azureus (dyskusja) 18:28, 10 sie 2018 (CEST)
- @Azureus całkowicie się z Tobą zgadzam, wprowadzanie haseł jest uciążliwe, linki do SGJP, SJP, Doroszewskiego mógłby dodawać bot, odmiana mogłaby być zaimportowana z Wikisłownika. Pamiętajmy jednak, że to projekt, który pierwsze hasło utworzył 3 miesiące temu. Przypomnijmy sobie jak ubogi w narzędzia i wsparcie botów był Wikisłownik kiedy miał 3 miesiące. Żeby mieć jako takie rozeznanie jak usprawnić interfejs, jak wesprzeć botami, jakie narzędzia do automatycznego wstawiania form stworzyć, trzeba najpierw trochę tych haseł wstawić ręcznie. Trzeba też mieć ludzi, którzy stworzą narzędzia. Ja np. obecnie portuję nasz mechanizm {{odmiana-przymiotnik-polski}} do modułu Lua, który będzie tworzyć przymiotniki ze wszystkimi formami, ale na razie autorów narzędzi jest mało. Pamiętajmy też że Wikidane to przede wszystkim jest baza danych, której zadaniem jest serwowanie danych innym projektom i narzędziom (w tym Wikisłownikowi, jeśli będzie zainteresowanie), a jej siła to fakt, że można tworzyć bazodanowe zapytania i w ten sposób badać język (przykłady: https://www.wikidata.org/wiki/Wikidata:Lexicographical_data/Ideas_of_queries#Language-independent ). Zgadzam się z Tobą również że obecnie edycja jest "machinalna i odmóżdżająca" bo do dyspozycji są tylko podstawowe właściwości i formy. Lada moment jednak udostępnione zostaną wielojęzyczne definicje znaczeń (można je już testować na serwerze testowym https://wikidata.beta.wmflabs.org/wiki/Lexeme:L1 ) i wtedy zacznie się zabawa z kreatywną edycją. Wraz ze znaczeniami powstaną właściwości do synonimów, antonimów, tłumaczeń itp. itd. Wtedy już edycja nie będzie taka machinalna. KaMan (dyskusja) 11:09, 11 sie 2018 (CEST)
- Podtrzymam swoje sceptyczne nastawienie. Sorry, taki już ze mnie człowiek małej wiary. Może i 3 miesiące, tylko że to wygląda jak tworzenie zupełnie nowego projektu od podszewki. Wikisłownik był tworzony od podszewki, Wikidane już nie powinny być od tej podszewki tworzone tylko powinny się opierać na wcześniejszych doświadczeniach. Wikisłownik ich nie miał. // user:Azureus (dyskusja) 14:01, 11 sie 2018 (CEST)
- Tu jednak nie mogę się zgodzić. Wikidane w niewielkim stopniu korzystają z doświadczeń Wikisłowników w zakresie interfejsu, ze względu na to, że żaden Wikisłownik nie jest bazą danych w takim rozumieniu jak Wikidane. Żaden Wikisłownik nie jest też od podstaw wielojęzykowy. Wikidane serwują dane we wszystkich językach jednocześnie. Mimo kilku lat istnienia Wikidanych, Wikipedie nadal przystosowują się do istnienia Wikidanych. Podobnie będzie z Wikisłownikami. Proces rozłożony jest na długi okres, być może w ogóle Wikisłowniki nie będą chciały używać danych z Wikidanych. W każdym razie 3 miesiące to bardzo krótki okres. KaMan (dyskusja) 16:51, 11 sie 2018 (CEST)
- Podtrzymam swoje sceptyczne nastawienie. Sorry, taki już ze mnie człowiek małej wiary. Może i 3 miesiące, tylko że to wygląda jak tworzenie zupełnie nowego projektu od podszewki. Wikisłownik był tworzony od podszewki, Wikidane już nie powinny być od tej podszewki tworzone tylko powinny się opierać na wcześniejszych doświadczeniach. Wikisłownik ich nie miał. // user:Azureus (dyskusja) 14:01, 11 sie 2018 (CEST)
- @Azureus całkowicie się z Tobą zgadzam, wprowadzanie haseł jest uciążliwe, linki do SGJP, SJP, Doroszewskiego mógłby dodawać bot, odmiana mogłaby być zaimportowana z Wikisłownika. Pamiętajmy jednak, że to projekt, który pierwsze hasło utworzył 3 miesiące temu. Przypomnijmy sobie jak ubogi w narzędzia i wsparcie botów był Wikisłownik kiedy miał 3 miesiące. Żeby mieć jako takie rozeznanie jak usprawnić interfejs, jak wesprzeć botami, jakie narzędzia do automatycznego wstawiania form stworzyć, trzeba najpierw trochę tych haseł wstawić ręcznie. Trzeba też mieć ludzi, którzy stworzą narzędzia. Ja np. obecnie portuję nasz mechanizm {{odmiana-przymiotnik-polski}} do modułu Lua, który będzie tworzyć przymiotniki ze wszystkimi formami, ale na razie autorów narzędzi jest mało. Pamiętajmy też że Wikidane to przede wszystkim jest baza danych, której zadaniem jest serwowanie danych innym projektom i narzędziom (w tym Wikisłownikowi, jeśli będzie zainteresowanie), a jej siła to fakt, że można tworzyć bazodanowe zapytania i w ten sposób badać język (przykłady: https://www.wikidata.org/wiki/Wikidata:Lexicographical_data/Ideas_of_queries#Language-independent ). Zgadzam się z Tobą również że obecnie edycja jest "machinalna i odmóżdżająca" bo do dyspozycji są tylko podstawowe właściwości i formy. Lada moment jednak udostępnione zostaną wielojęzyczne definicje znaczeń (można je już testować na serwerze testowym https://wikidata.beta.wmflabs.org/wiki/Lexeme:L1 ) i wtedy zacznie się zabawa z kreatywną edycją. Wraz ze znaczeniami powstaną właściwości do synonimów, antonimów, tłumaczeń itp. itd. Wtedy już edycja nie będzie taka machinalna. KaMan (dyskusja) 11:09, 11 sie 2018 (CEST)
- Odnośnie linków do słowników: dane leksykograficzne to nie moja działka, więc niezbyt dobrze się orientuję, ale w Wikidanych dość szeroko wykorzystywane jest narzędzie mix'n'match (meta:Mix'n'match/Manual). Po zaimportowaniu zestawu danych (np. dla identyfikator w IUPAC GoldBook (P4732)), narzędzie próbuje dopasować poszczególne strony do elementów w WD i tworzy listę [17], dzięki której można łatwo potwierdzić dopasowanie/odrzucić/utworzyć nowy element z danym identyfikatorem itd. Nie wiem, czy to obejmuje leksemy i czy na obecnym etapie może to być Wam przydatne (czy dopiero później, gdy już będzie do czego dodawać te linki) – ale w razie czego można się odezwać do autora narzędzia (Magnus Manske) i dopytać. Wostr (dyskusja) 16:23, 14 sie 2018 (CEST)
- dostępna jest już właściwość dla Wielkiego słownika ortograficznego PWN online: https://www.wikidata.org/wiki/Property:P5627 przykłady użycia w linkujących
- rozpoczęło się głosowanie nad utworzeniem właściwości dla wsjp.pl https://www.wikidata.org/wiki/Wikidata:Property_proposal/WSJP_ID zachęcam do głosowania
- kontynuowane są prace nad wprowadzeniem znaczeń (ang. senses); obecnie zapowiadana data to październik; szczegóły prowadzonych prac można znaleźć tutaj: https://www.wikidata.org/wiki/Wikidata:Status_updates/2018_08_20#Development a wersję roboczą znaczeń można testować na serwerze beta: https://wikidata.beta.wmflabs.org/wiki/Lexeme:L1
- liczba języków wspieranych przez narzędzie Wikidata Lexeme Forms wzrosła do 12, pełna lista tutaj: https://www.wikidata.org/wiki/User:Lucas_Werkmeister/Wikidata_Lexeme_Forms#Language_support
KaMan (dyskusja) 10:09, 21 sie 2018 (CEST)
- właściwość dla wsjp.pl jest już dostępna: https://www.wikidata.org/wiki/Property:P5720 przykłady użycia w linkujących
- rozpoczęło się głosowanie nad utworzeniem właściwości dla Dobrego Słownika https://www.wikidata.org/wiki/Wikidata:Property_proposal/Dobry_s%C5%82ownik_ID zachęcam do głosowania
- rozpoczęło się też głosowanie nad właściwością do tworzenia przykładów użycia: https://www.wikidata.org/wiki/Wikidata:Property_proposal/usage_example
- na ukończeniu są prace nad dodaniem znaczeń do leksemów; funkcjonalność można testować na serwerze roboczym np. tu: https://wikidata.beta.wmflabs.org/wiki/Lexeme:L60
- na stronie https://www.wikidata.org/wiki/Wikidata:Lexicographical_data/Statistics dostępna jest statystyka wprowadzonych leksemów
- strona wyszukiwania w Wikidanych umożliwia przeszukiwanie leksemów według form i podaje wynik w bardzo przystępnej formie, wystarczy poprzedzić słowo prefiksem "L:" np. wyszykiwanie "L:prazeodymu" zwraca elegancki opis "liczba pojedyncza, dopełniacz dla: prazeodym (L17762): język polski rzeczownik": https://www.wikidata.org/w/index.php?search=&search=L%3Aprazeodymu&title=Special:Search&go=Przejdź
KaMan (dyskusja) 14:13, 5 wrz 2018 (CEST)
- właściwość dla Dobrego słownika jest już dostępna: d:Property:P5793 przykłady użycia w linkujących
- rozpoczęło się głosowanie nad utworzeniem właściwości dla dwóch historycznych słowników XVI i XVII wieku d:Wikidata:Property_proposal/SJPXVII_ID i d:Wikidata:Property_proposal/SPXVI_ID - zachęcam do głosowania
- można śledzić zmiany odnośnie wyłącznie polskich haseł na tej stronie
- pojawiło się narzędzie newentity.js, które w połączeniu z modułem Lexeme-pl umożliwia w jednym kroku tworzyć kilkadziesiąt form odmiany polskich leksemów - przykładowy efekt w tym leksemie
- ogłoszony został termin wdrożenia najbardziej oczekiwanej funkcjonalności - definicji; będzie to 18 października
- język polski osiągnął liczbę 1000 leksemów
- pojawiły się pierwsze hasła gwary poznańskiej
- możliwe jest dodawanie przykładów użycia dzięki nowej właściwości d:Property:P5831
KaMan (dyskusja) 10:16, 16 wrz 2018 (CEST)
Czy wpisy leksykograficzne danego leksemu są w jakiś sposób powiązane z hasłami w Wikisłowniku? Tzn. czy leksemy w WD są tam podlinkowane do odpowiadających im haseł WS? I czy możliwe jest stworzenie jakiegoś pluginu który nad hasłem w WS pokazywałby link do odpowiadającego wpisu w WD? Karol Szapsza (dyskusja) 17:13, 19 wrz 2018 (CEST)
- @Karol Szapsza Jeszcze nie ma takich funkcjonalności ale są w planie tego typu rzeczy, patrz https://www.wikidata.org/wiki/Wikidata:Lexicographical_data/Documentation#What_will_be_added_in_the_future KaMan (dyskusja) 17:33, 19 wrz 2018 (CEST)
- Od dzisiejszego dnia możliwe jest tworzenie zapytań uwzględniających leksemy. To zapytanie po uruchomieniu pokaże najdłuższe wyrazy w języku polskim. To zapytanie pokaże najczęściej używane rodzaje gramatyczne. To zapytanie pokaże graf leksemów powiązanych etymologicznie z praindoeuropejskim rdzeniem *wódr̥.
- Już od czwartku udostępnione zostanie dodawanie definicji do leksemów.
KaMan (dyskusja) 10:56, 16 paź 2018 (CEST)
- Język polski w Wikidanych osiągnął liczbę 1000 przykładów użycia. Wszystkie przykłady można przejrzeć uruchamiając to zapytanie.
KaMan (dyskusja) 09:16, 23 lis 2018 (CET)
Global preferences are available
Dostępne są już globalne preferencje. Można je ustawiać na stronie Globalne Preferencje. Instrukcje znajdują się na mediawiki.org. Możesz zostawić opinię. -- Keegan (WMF) (talk)
21:19, 10 lip 2018 (CEST)
Nowa grupa użytkowników edytujących JS/CSS
Przeklejam komunikat z Wikipedii, który z jakiegoś powodu (błąd readonly) nie został umieszczony przez bota MW tutaj:
Witajcie!
Aby zwiększyć bezpieczeństwo czytelników i redaktorów, zmieniono sposób obsługi uprawnień do edycji stron CSS/JS. (Są to takie strony jak MediaWiki:Common.css i MediaWiki:Vector.js, które zawierają kod wykonywany w przeglądarce odwiedzającego stronę użytkownika.)
Została utworzona nowa grupa użytkowników, interface-admin.
Za cztery tygodnie począwszy od dziś, tylko członkowie tej grupy będą mogli edytować strony z CSS i JS (czyli wszystkie strony o nazwach kończących się na .css lub .js, zarówno w przestrzeni nazw MediaWiki: jak i na podstronach innych użytkowników).
Aby dowiedzieć się więcej o motywach jakimi kierowano się wprowadzając tę zmianę, przeczytaj ten artykuł.
Prosimy o dodawanie do tej grupy użytkowników, którzy potrzebują mieć możliwość edycji CSS/JS (robi się to tak jak przyznawanie uprawnień administratora przez biurokratę lub stewarda). Jest to niebezpieczne uprawnienie; użytkownik o złych zamiarach lub włamywacz na konto użytkownika z uprawnieniami może wykorzystać je do znacznie gorszych nadużyć niż może administrator. Prosimy o przyznawanie ich tylko użytkownikom, którzy ich potrzebują i są darzeni zaufaniem przez społeczność, a także postępują zgodnie z dobrymi praktykami ochrony konta (hasła) i komputera (używanie silnych haseł, nie wykorzystywanie tych samych haseł w wielu miejscach, korzystanie z autoryzacji dwuetapowej, nieinstalowanie oprogramowania nieznanego pochodzenia, korzystanie z programu antywirusowego).
Dziękujemy!
Tgr (talk) 15:08, 30 lip 2018 (CEST) (poprzez globalne rozsyłanie wiadomości)
Dyskusja w Wikipedii: w:pl:Wikipedia:Kawiarenka/Ogólne#Administratorzy utracą możliwość edytowania JS i CSS. W związku z powyższym chciałbym złożyć wniosek o przyznanie grupy uprawnień o roboczej nazwie interface administrator, aby zachować dotychczasową możliwość edytowania skryptów JS. Pełna lista owych uprawnień: zob. Specjalna:Grupy użytkowników. Mój osobisty wkład w przestrzeni MediaWiki: i innych: klik. Pozdrawiam, Peter Bowman (dyskusja) 18:46, 30 lip 2018 (CEST)
- Uważam, że aby nie tworzyć nadmiarowych bytów i zbędnej biurokracji, każdy administrator powinien mieć dostęp do tej grupy uprawnień, jeśli tylko wyrazi taką chęć przed biurokratą. PiotrekDDYSKUSJA 23:51, 30 lip 2018 (CEST)
- Raczej nie o biurokrację chodzi, lecz o ochronę przed nadużyciem (meta:Creation of separate user group for editing sitewide CSS/JS). Moim głównym zastrzeżeniem przed uchyleniem możliwości odebrania uprawnień administratora z powodu nieaktywności (WS:Bar/Archiwum 18#WAŻNE: Kontrola aktywności administratorów) było właśnie ryzyko przejęcia konta. Przeciwnicy używali tejże burokracji (oraz bodajże niezrozumiałej ingerencji stewardów, w mocnych słowach) jako główny argument. Jakkolwiek by nie było, teraz osoby nieposiadające obecnie uprawnień administratora mogą wystąpić o przyłączenie ich do nowej grupy. Uważam, że zarówno taka osoba, jak i administrator (teraz lub w przyszłości) powinni wykazać potrzebę dostępu do tych narzędzi. Peter Bowman (dyskusja) 15:19, 31 lip 2018 (CEST)
- Myślę, że chodzi o większą biurokratyzację i w konsekwencji zamknięcie lub utrudnienie dostępu... (a do diaska miało to być wolne medium czy nie?) Ile konkretnie było włamań ogólnie w wikimedia-projektach? - są statystyki? / dane? (czy tak a priori ograniczyć!, a fajniejsze słowo → restryktować dostęp?) - ile na wikisłownikach? Jak to wygląda procentowo? Zagrożenia i teorie spiskowe można snuć prawie zawsze / a zawsze podjudzać... by ograniczać prawa..! Moje realne pytanie: na ile jest niebezpieczny problem / jak ważki jest? Jak możemy się bronić, nie ograniczając przy tym praw osób, które pracowały na ten Wikisłownik? Krokus (dyskusja) 21:25, 31 lip 2018 (CEST)
- @Krokus: czy przeczytałaś podlinkowaną stronę na Meta? Jeżeli ma być zamknięty dostęp dla osób niemających pojęcia o programowaniu (był taki przypadek, że admin przekleił wikikod w skrypcie JS, który ktoś mu podsunął, i zepsuł wszystkim dynamiczne wyświetlanie stron) albo dla kont, które od lat się nie logują (zdarzały się wycieki haseł), to ja nie rozumiem, czym się tu objawia biurokratyzacja i „ograniczanie praw”. Uprawnienia zatrzymają osoby, które faktycznie ich potrzebują, więc ryzyko nadużycia maleje, a narzędzie zostaje użyte wtedy, gdy zachodzi potrzeba. Decyzję o tym, kto otrzyma takie uprawnienia, podejmuje społeczność lokalna. Poszukaj słowa „incident” w phab:T190015 – taka inicjatywa powstała, ponieważ podobne rzeczy już się zdarzały, tyle że nie u nas. Czy rozsądne jest zamiecenie potencjalnego problemu pod dywan, aż coś się faktycznie stanie? Prosiłbym, aby nie sugerować istnienia teorii spiskowych przed zapoznaniem się z sytuacją – przykro mi, ale właśnie takie komentarze (wracając przy okazji do Twojej wypowiedź o wiernym psie z archiwalnego wątku) uznałbym za podjudzanie, odwracające uwagę od istoty problemu.
- Jak możemy się bronić: wyznaczając, kto z nas będzie miał dostęp. Zgłaszam się, ponieważ tym się zajmuję i potrzebne mi jest do pracy w WS, ale możesz zaproponować inną lub inne osoby, niekoniecznie z grona adminów. Jeżeli nikt tych uprawnień nie otrzyma, każda zmiana dotycząca JS/CSS (tj. skrypty i gadżety) będzie musiała przechodzić przez stewardów z Meta, więc w pewnym sensie sami sie zbiurokratyzujemy. Pozdrawiam, Peter Bowman (dyskusja) 23:11, 31 lip 2018 (CEST)
- Skoro to nie prowokacja, to gdzie linki i twój login poprzedniku Petera Bowmana??????????????? O nieznajomy:) Suponujesz, że jeden admin - i niby w jakim okreso-czasie? - nadużył upewnień...i to niby ma skutkować = restrykcjami dla wszystkich?!!!! Miej litość:)! Statystyki proszę/dane / wykresy!!!!! Bez danych/ statystyk -mówię nie!! I czytałam te gnioty na tej stronie bez statystyk:) Dla mnie to kolejne resekcje, by ograniczyć dostęp, odkąd Wikimedia stały się dobrem, bo niby argumentem ma być że 75% of admins have never edited CSS/JS i co z tego - że nie nadużywają (na szczęście) - i to ma to się równać zabraniu uprawnień? Gdzie te rzekome nadużycia? Krokus (dyskusja) 02:21, 1 sie 2018 (CEST)
- Dokładnie co chcesz osiągnąć, Krokusie? Wykazujesz brak zrozumienia i odchodzisz od właściwego tematu – te rzekome „gnioty” i „resekcje” mają znaczenie czy ze statystykami, czy bez nich. Twoje insynuacje nie mają wpływu na to, że za kilka tygodni nikt w tym projekcie nie będzie mógł edytować JS. Wspomniawszy już o statystykach, Twój wkład w tym aspekcie jest żaden – nie chwalę, nie piętnuję, po prostu nie Twoja działka, jednak wspomniałaś wcześniej o „prawach osób, które pracowały na ten Wikisłownik”, a piszesz później o „restrykcjach” dla „wszystkich”: czy starasz się wywalczyć dostęp do nieużywanych uprawnień kosztem edytorów, dla których jest to element pracy w WS? Agumentem wcale nie jest statystyka kto edytował, a kto nie, lecz – jak pisałem – zabezpieczenie przed ewentualnym nadużyciem. Dla ułatwienia (?) wyobraź sobie, że każdy użytkownik ma możliwość kasowania stron. Skala jest inna dla Wikipedii, gdzie mają dziesiątki adminów (oraz tryb odbierania uprawnień wskutek nieaktywności), ale w gruncie rzeczy problem ten sam. Peter Bowman (dyskusja) 03:31, 1 sie 2018 (CEST)
- @Peter Bowman tak zupełnie na marginesie - absolutnie nie mam nic przeciwko temu, byś otrzymał (a właściwie zachował) ww. uprawnienia - jak i wszyscy z naszego projektu, którzy technicznie go wspierają, ponieważ nie przypominam sobie, by ktokolwiek z nich coś złośliwie zepsuł w projekcie, a błędy zdarzały się (np. że jakiś skrypt nie od razu działał jak powinien) i będą się zdarzać, bo człowiek jest istotą omylną. Poza tym, nie są to żadne teorie spiskowe. Faktem jest, że struktura Wikimediów coraz bardziej się biurokratyzuje, na Wikipedii otrzymanie jakichkolwiek uprawnień (wątek ten był wielokrotnie poruszany w rozmowach na żywo) graniczy niemal z cudem, bo osoby posiadające już uprawnienia (a w tym prawo głosu) nie chcą dopuszczać nowych osób, tym samym tworząc hermetyczne środowisko. Ja zwracam tylko uwagę na zjawisko i tendencję, która mi się nie podoba i uważam za niebezpieczną. Pozdrawiam Krokus (dyskusja) 09:54, 2 sie 2018 (CEST)
- @Krokus: Odeszłaś od tematu i w sumie to już nie wiadomo, o co Ci chodzi, pisz staranniej… :/ I proszę, opanowuj swe emocje. PiotrekDDYSKUSJA 15:21, 1 sie 2018 (CEST)
- Dokładnie co chcesz osiągnąć, Krokusie? Wykazujesz brak zrozumienia i odchodzisz od właściwego tematu – te rzekome „gnioty” i „resekcje” mają znaczenie czy ze statystykami, czy bez nich. Twoje insynuacje nie mają wpływu na to, że za kilka tygodni nikt w tym projekcie nie będzie mógł edytować JS. Wspomniawszy już o statystykach, Twój wkład w tym aspekcie jest żaden – nie chwalę, nie piętnuję, po prostu nie Twoja działka, jednak wspomniałaś wcześniej o „prawach osób, które pracowały na ten Wikisłownik”, a piszesz później o „restrykcjach” dla „wszystkich”: czy starasz się wywalczyć dostęp do nieużywanych uprawnień kosztem edytorów, dla których jest to element pracy w WS? Agumentem wcale nie jest statystyka kto edytował, a kto nie, lecz – jak pisałem – zabezpieczenie przed ewentualnym nadużyciem. Dla ułatwienia (?) wyobraź sobie, że każdy użytkownik ma możliwość kasowania stron. Skala jest inna dla Wikipedii, gdzie mają dziesiątki adminów (oraz tryb odbierania uprawnień wskutek nieaktywności), ale w gruncie rzeczy problem ten sam. Peter Bowman (dyskusja) 03:31, 1 sie 2018 (CEST)
- Skoro to nie prowokacja, to gdzie linki i twój login poprzedniku Petera Bowmana??????????????? O nieznajomy:) Suponujesz, że jeden admin - i niby w jakim okreso-czasie? - nadużył upewnień...i to niby ma skutkować = restrykcjami dla wszystkich?!!!! Miej litość:)! Statystyki proszę/dane / wykresy!!!!! Bez danych/ statystyk -mówię nie!! I czytałam te gnioty na tej stronie bez statystyk:) Dla mnie to kolejne resekcje, by ograniczyć dostęp, odkąd Wikimedia stały się dobrem, bo niby argumentem ma być że 75% of admins have never edited CSS/JS i co z tego - że nie nadużywają (na szczęście) - i to ma to się równać zabraniu uprawnień? Gdzie te rzekome nadużycia? Krokus (dyskusja) 02:21, 1 sie 2018 (CEST)
- @Peter Bowman Ależ ja wiem, że chodzi o ochronę przed nadużyciem, tylko uważam, że w mniejszych projektach, od których zalicza się nasz, zalety tej zmiany (ta ochrona) są przyćmiewane przez jej wady (rozrost biurokracji, konieczność poświęcania czasu na dyskusje nad przyznawaniem tych uprawnień). Dlatego też jestem za przyjęciem prostej zasady: każdy admin, który otrzymał uprawnienia poprzez głosowanie, ma prawo poprosić biurokratę o nadanie uprawnień admina technicznego, a ów biurokrata ma mu je nadać. Zakładam, że nasi administratorzy nie planują swych uprawnień nadużywać. (Co do nieaktywnych – nie od dziś uważam, że słusznie byłoby im odbierać prawa, choćby dla uniknięcia wspomnianej przez Ciebie możliwości włamania na konto, ale to temat na inną dyskusję). PiotrekDDYSKUSJA 15:21, 1 sie 2018 (CEST)
- Zgadzam się w większości, @PiotrekD, jednak wolałbym, aby nie był to proces automatyczny (wniosek równa się nadaniu uprawnień), lecz biurokrata stosował odpowiednie kryterium – wedle uznania, ale przynajmniej w oparciu o motywacje opisane i podlinkowane wyżej. Mogłoby to przypominać WS:Wersje przejrzane/Przyznawanie uprawnień, zresztą podobny tryb proponują w Wikipedii (choć wciąż bez ustaleń co do procedury dla nie-adminów). Powinienem wywołać @Tsca i spytać, czy taki tryb wydaje mu się odpowiedni, gdyż zakłada minimalną aktywność i reakcję na wnioski (podążając znów za przykładem Wikipedii, takowe raczej powinny być składane w projekcie, a nie np. drogą mejlową). Sęk w tym, że w razie jego nieobecności nie da się, jak w przypadku głosowań PUA, wystąpić do stewardów po tygodniu i poprosić o wyegzekwowanie decyzji społeczności. Nadmienię jeszcze dla uzupełnienia, że nowych uprawnień, ze względu na ich wagę oraz na wzór uprawnień admina, nie można odebrać lokalnie (tj. przez lokalnego biurokratę). Peter Bowman (dyskusja) 20:49, 1 sie 2018 (CEST)
- Aby nie komplikować sprawy, proponuję skorzystać z istniejącej już strony Wikisłownik:Przyznawanie uprawnień i dodać sekcję „Administrator techniczny” (tak obecnie funkcja ta się nazywa). Wniosek powinien być uzasadniony, społeczność powinna mieć – podobnie jak przy innych uprawnieniach – 7 dób na ew. komentarze. Decyzję podejmuje biurokrata na podst. uzasadnienia, komentarzy i ew. analizy dotychczasowej działalności kandydata, w tym na projektach pokrewnych. tsca (dyskusja) 21:48, 1 sie 2018 (CEST)
- @PiotrekD, @Krokus, @Tsca, umieściłem nową wersję WS:PUA w brudnopisie: Wikipedysta:Peter Bowman/Wikisłownik:Przyznawanie uprawnień (porównanie). Powieliłem standardowe zasady 30 dni + 100 edycji dla zachowania spójności, w każdym razie komentarze można również zostawiać w sekcji „Dyskusja”. A nazwa grupy to ostatecznie „administrator interfejsu”. Czy taka wersja jest w porządku, trzeba coś zmienić? Za tydzień wprowadziłbym zmiany na WS:PUA i utworzył lokalną wersję strony w:Wikipedia:Administratorzy interfejsu. Pozdrawiam, Peter Bowman (dyskusja) 23:38, 14 sie 2018 (CEST)
- @Peter Bowman: Dziękuję za przygotowanie tej propozycji, ja jestem za. Pozdrawiam, tsca (dyskusja) 22:59, 15 sie 2018 (CEST)
- @Peter Bowman: Z mojego punktu widzenia głosowanie, które nie jest wiążące, jest całkowicie zbędne. Wydaje mi się, że wystarczyłaby strona z wnioskami jak ta dotycząca przyznawania uprawnień redaktora. Też każdy mógłby skomentować, też biurokrata by decydował ostatecznie, ale mniej formalne (i mniej strasznie wyglądające).
- W ogóle nie podoba mi się uznawanie tej nowej grupy jako… em… czegoś nowego, co wymaga stron pomocy, stron z zasadami, formalności i takich tam. To może być dobre na Wikipedii. Ja widziałbym u nas tę grupę po prostu jako specjalną flagę techniczną, którą mają administratorzy, nic istotnego, nie jako oddzielną grupę społeczną. (Tak, wbrew temu, co twierdzą niektórzy wikipedyści, grupa administratorów tak naprawdę jest również grupą społeczną). PiotrekDDYSKUSJA 23:46, 14 sie 2018 (CEST)
- @PiotrekD: według tej propozycji nie tworzymy osobnej strony dla wniosków w sprawie nowej grupy. Zakładając, że taką utworzymy, to pod jaką nazwą? We WS:PUA można głosować nie tylko na administratora, czyli de facto jest to WS:PU. Może wplatać gdzieś w tych trzech punktach regulaminu (albo napisać go od nowa), że nie ma tu formalnie żadnego głosowania? Jak byś to ujął? Ponadto czy dobrze rozumiem, że wg Ciebie tę flagę powinni jedynie posiadać administratorzy? W kwestii stron pomocy chodzi tylko o to, żeby użytkownicy mogli się dowiedzieć, na czym to polega, nie napotykając czerwonych linków tu i ówdzie (np. w Specjalna:Grupy użytkowników). Chętnie zostawiłbym miękkie przekierowanie do strony w Wikipedii, tyle że po części byłaby to nieprawda (u nas np. nie ma na razie mowy o weryfikacji tychże uprawnień).
- Nie chcąc wnikać ponownie w off-topic, polemizowałbym jednak co do grupy społecznej – u nas nie ma zamkniętych list dyskusyjnych, nie ma też kilkudziesięciu aktywnych administratorów. Chętnie postrzegałbym tę (jak i każdą) grupę jako użytkownicy mający po prostu dostęp do konkretnych, dodatkowych narzędzi. Jeżeli ktoś chce się doszukać specjalnego „statusu”, to pewnie zacznie mówić o rozwarstwieniu społeczności. Tak tylko wyrażam swój niepokój, prawdopodobnie źle Cię zrozumiałem :). Peter Bowman (dyskusja) 00:41, 15 sie 2018 (CEST)
- O wyborze miejsca dyskusji wypowiem się
jutropo śnie (już po północy), jeśli nie zapomnę, ale teraz odpowiem na jedno pytanie: „Ponadto czy dobrze rozumiem, że wg Ciebie tę flagę powinni jedynie posiadać administratorzy?”. Tak, dobrze rozumiesz. Uprawnienia te dają znacznie większe możliwości niż uprawnienia administratorskie, ba, odpowiednim kodem JS można dokonać dowolnej operacji wymagającej uprawnień z konta administratora jako on (!), o ile ma włączoną obsługę JS. Jeśli na administratora wymagane jest poparcie społeczności w postaci 80% (wg mnie trochę za dużo chyba, ale nie o tym mowa) głosów za w głosowaniu, to tym bardziej powinny tego wymagać szersze uprawnienia. Dlatego właśnie aby nie tworzyć nadmiaru formalności, proponuję dla adminów system, który proponuję, a nieadmini niech zgłoszą się na PUA. PiotrekDDYSKUSJA 00:50, 15 sie 2018 (CEST)- @PiotrekD, moje przemyślenia do powyższego:
- Już pisałeś, ale powtórzę tylko dla całokształtu porównania, że ostateczne słowo i tak zabiera biurokrata.
- Większe lub mniejsze poparcie społeczności nie jest wykładnikiem znajomości JS/CSS kandydata ani nie ustrzeże przed możliwością przejęcia konta.
- Wychodząc na przeciw komentarzom Krokusa, ale również dodam tutaj z uwagi na wspomniany wymóg 80%, wierzę, że nikt „na górze” nie wymyślił nowej grupy z prostej obawy przed tym, że dowolny admin nagle zacznie rozrabiać. Przeczy to ideom wiki (w:WP:STEKI), powoduje niesmak (przekonanie, że ktoś chce nam zrobić na złość, zakładając najgorsze), utrudnia prowadzenie dyskusji (odwracanie uwagi od głównego tematu, podejrzenie spisku i inne teorie).
- Hipotetyczna sytuacja: aby uzyskać pożądane uprawnienia, przechodzę PUA. Głosowanie zakończono pomyślnie, lecz biurokrata nie zgadza się, abym edytował interfejs/skrypty. W praktyce zastrzeżenia pojawiłyby się już na etapie głosowania na admina, jednak chcę tu pokazać, że proponowane przepisy mogłyby prowadzić do takich zawiłości – spowodowanych przez sprzężenie dwóch rodzajów uprawnień.
- Uprawnienia administratora to dodatkowe obowiązki/uprawnienia, którymi kandydat może wcale nie być zainteresowany. Wprawdzie to nie Wikipedia, o której się pisze, że proces głosowania jest istną „ścieżką zdrowia” dla chętnych posiadania zaawansowanych uprawnień, lecz taki „ciężar” mógłby ich i tak odstręczać.
- W nawiązaniu do poprzedniego punktu, ideą utworzenia nowej grupy jest odłączenie uprawnień „technicznych” od pozostałych w puli administratorskiej z racji tego, że większość adminów z nich nie korzysta, a niosą ze sobą pewne ryzyko (przedstawiłeś ku temu przykład). Unikajmy dążenia do tego samego rezultatu z drugiego kierunku: użytkownik techniczny posiadający uprawnienia do masowego usuwania/blokowania, który jednak w ogóle z nich nie będzie korzystał.
- Nie ustaliliśmy wymaganego progu (np. minimalna liczba edycji lub staż) dla kandydatów, zresztą proponowany przez tsca zapis dopuszcza ocenę kandydata na podstawie wkładu w projektach siostrzanych. Użytkownik stricte techniczny działa przeważnie w innym obszarze projektu, przy czym jego znajomość języków oprogramowania i narzędzi nie powinno podlegać tym samym kryteriom, jakie narzuca się administratorom. Przypomina mi się casus Beau (nie było mnie tu wtedy, proszę to więc potraktować jako przypuszczenie) jako użytkownika technicznego, który chce wprowadzić rozwiązania działające już w innych projektach. Zgodnie z zasadami, musi znać ZTH, wypracować 600 edycji i odczekać minimum dwa miesiące, aby móc zgłosić się na admina.
- Jako komentarz do powyższego, biurokrata może nadać uprawnienia tymczasowo. Moim zdaniem daje to większą elastyczność w połączeniu z nową grupą: może się pojawić chętny technomag (np. z innego projektu), nadajemy mu uprawnienia na czas wprowadzania poprawek czy nowych rozwiązań w skryptach, potem można przedłużyć lub nadać ponownie po wygaśnięciu (i złożeniu kolejnego wniosku).
- Pozdrawiam, Peter Bowman (dyskusja) 15:15, 16 sie 2018 (CEST)
- @Peter Bowman: Uh, zapomniałem się wczoraj wypowiedzieć o miejscu dyskusji, mój błąd. Szczerze mówiąc, nie chce mi się nad tym już teraz więcej myśleć (w ogóle cała dyskusja zmierza w kierunku tych wikipedyjnych niestety), więc po prostu skłonię się ku propozycjom innych. Co do napisach przez Ciebie punktów – masz rację (może poza punktem trzecim, wydaje mi się, że „tym na górze” o to właśnie chodziło), ale ja ciągle mam obawy, które uważam za słuszne. Niemniej, aby nie bić już więcej piany, skłaniam się ku Twemu rozwiązaniu – z wiarą, że @tsca wie, co robi ;). Pozdrawiam, PiotrekDDYSKUSJA 15:34, 16 sie 2018 (CEST)
- @PiotrekD, moje przemyślenia do powyższego:
- O wyborze miejsca dyskusji wypowiem się
- @PiotrekD, @Krokus, @Tsca, umieściłem nową wersję WS:PUA w brudnopisie: Wikipedysta:Peter Bowman/Wikisłownik:Przyznawanie uprawnień (porównanie). Powieliłem standardowe zasady 30 dni + 100 edycji dla zachowania spójności, w każdym razie komentarze można również zostawiać w sekcji „Dyskusja”. A nazwa grupy to ostatecznie „administrator interfejsu”. Czy taka wersja jest w porządku, trzeba coś zmienić? Za tydzień wprowadziłbym zmiany na WS:PUA i utworzył lokalną wersję strony w:Wikipedia:Administratorzy interfejsu. Pozdrawiam, Peter Bowman (dyskusja) 23:38, 14 sie 2018 (CEST)
- Aby nie komplikować sprawy, proponuję skorzystać z istniejącej już strony Wikisłownik:Przyznawanie uprawnień i dodać sekcję „Administrator techniczny” (tak obecnie funkcja ta się nazywa). Wniosek powinien być uzasadniony, społeczność powinna mieć – podobnie jak przy innych uprawnieniach – 7 dób na ew. komentarze. Decyzję podejmuje biurokrata na podst. uzasadnienia, komentarzy i ew. analizy dotychczasowej działalności kandydata, w tym na projektach pokrewnych. tsca (dyskusja) 21:48, 1 sie 2018 (CEST)
- Zgadzam się w większości, @PiotrekD, jednak wolałbym, aby nie był to proces automatyczny (wniosek równa się nadaniu uprawnień), lecz biurokrata stosował odpowiednie kryterium – wedle uznania, ale przynajmniej w oparciu o motywacje opisane i podlinkowane wyżej. Mogłoby to przypominać WS:Wersje przejrzane/Przyznawanie uprawnień, zresztą podobny tryb proponują w Wikipedii (choć wciąż bez ustaleń co do procedury dla nie-adminów). Powinienem wywołać @Tsca i spytać, czy taki tryb wydaje mu się odpowiedni, gdyż zakłada minimalną aktywność i reakcję na wnioski (podążając znów za przykładem Wikipedii, takowe raczej powinny być składane w projekcie, a nie np. drogą mejlową). Sęk w tym, że w razie jego nieobecności nie da się, jak w przypadku głosowań PUA, wystąpić do stewardów po tygodniu i poprosić o wyegzekwowanie decyzji społeczności. Nadmienię jeszcze dla uzupełnienia, że nowych uprawnień, ze względu na ich wagę oraz na wzór uprawnień admina, nie można odebrać lokalnie (tj. przez lokalnego biurokratę). Peter Bowman (dyskusja) 20:49, 1 sie 2018 (CEST)
- Myślę, że chodzi o większą biurokratyzację i w konsekwencji zamknięcie lub utrudnienie dostępu... (a do diaska miało to być wolne medium czy nie?) Ile konkretnie było włamań ogólnie w wikimedia-projektach? - są statystyki? / dane? (czy tak a priori ograniczyć!, a fajniejsze słowo → restryktować dostęp?) - ile na wikisłownikach? Jak to wygląda procentowo? Zagrożenia i teorie spiskowe można snuć prawie zawsze / a zawsze podjudzać... by ograniczać prawa..! Moje realne pytanie: na ile jest niebezpieczny problem / jak ważki jest? Jak możemy się bronić, nie ograniczając przy tym praw osób, które pracowały na ten Wikisłownik? Krokus (dyskusja) 21:25, 31 lip 2018 (CEST)
- Raczej nie o biurokrację chodzi, lecz o ochronę przed nadużyciem (meta:Creation of separate user group for editing sitewide CSS/JS). Moim głównym zastrzeżeniem przed uchyleniem możliwości odebrania uprawnień administratora z powodu nieaktywności (WS:Bar/Archiwum 18#WAŻNE: Kontrola aktywności administratorów) było właśnie ryzyko przejęcia konta. Przeciwnicy używali tejże burokracji (oraz bodajże niezrozumiałej ingerencji stewardów, w mocnych słowach) jako główny argument. Jakkolwiek by nie było, teraz osoby nieposiadające obecnie uprawnień administratora mogą wystąpić o przyłączenie ich do nowej grupy. Uważam, że zarówno taka osoba, jak i administrator (teraz lub w przyszłości) powinni wykazać potrzebę dostępu do tych narzędzi. Peter Bowman (dyskusja) 15:19, 31 lip 2018 (CEST)
- Według ostatnich komentarzy w Meta oraz gerrit:450450 istnieje zamiar umożliwienia biurokratom odebrania nowych uprawnień. Powinno to było nastąpić zaraz po utworzeniu grupy administratorów technicznych, lecz na chwilę obecną nie ma takiej opcji. Peter Bowman (dyskusja) 12:38, 19 sie 2018 (CEST)
- Potwierdzam, że biurokraci mogą już odbierać uprawnienia administratora interfejsu. Peter Bowman (dyskusja) 00:27, 22 sie 2018 (CEST)
Wprowadziłem zmiany w WS:PUA (Specjalna:Diff/6246569), utworzyłem też Wikisłownik:Administratorzy interfejsu. Peter Bowman (dyskusja) 00:54, 22 sie 2018 (CEST)
- Uzupełniłem jeszcze listę obowiązków biurokratów: Specjalna:Diff/6246615. No i zgłosiłem swoją kandydaturę: Wikisłownik:Przyznawanie uprawnień/Peter Bowman/2. Dziękuję uprzejmie za udział w powyższej dyskusji. Pozdrawiam, Peter Bowman (dyskusja) 01:29, 22 sie 2018 (CEST)
TemplateStyles
Utworzenie nowej grupy zbiegło się w czasie z wprowadzeniem rozszerzenia TemplateStyles. W skrócie: chodzi o możliwość wiązania stylów CSS z konkretnym szablonem (lub stroną) bez konieczności edytowania MediaWiki:Common.css lub podobnych, stawiając nacisk na odróżnienie interfejsu (np. komunikaty na stronie, wszystko co jest poza zawartością haseł) od właściwej treści strony (w której wywołujemy szablony, aby generowały tekst w określony sposób, często korzystając z odpowiednich stylów). Ostatnio wyodrębniałem z Common.css i gadżetów to, co się da do osobnych stron: [18]. Przykład dla {{potencjalnie}}: zmiany w szablonie, arkusz stylów. Tego typu strony zawierają odpowiednio skontrolowany CSS (oprogramowanie nie pozwala używać niektórych reguł ze względów bezpieczeństwa), działają również na wersji mobilnej, a możliwość edycji nie ogranicza się już tylko do administratorów. Więcej na mw:Help:TemplateStyles. Pozdrawiam, Peter Bowman (dyskusja) 14:21, 18 sie 2018 (CEST)
Wiktionary Cognate Dashboard

Sorry for writing this message in English. Feel free to help translate it below.
Hello all,
A few months ago, we asked you for feedback about Cognate, the system allowing interwikilinks between Wiktionaries (on main namespace). Several community members gave some suggestions, one of them was to provide statistics about these interwikilinks.
The Wikidata team is pleased to present you the Wiktionary Cognate Dashboard, a website presenting a lot of interesting information about how Wiktionaries are connected to each others. You can find there, for example:
- the most interlinked Wiktionary entries not having a page on your Wiktionary
- the number of interlinks between each possible pair of Wiktionaries
- visualizations of the relationships between different Wiktionaries
To learn more about the tool, you can have a look at the documentation (please help us translating it in your language!). The interface of the tool itself can also be translated in other languages by using this page.
If you find a bug, please let a comment on this Phabricator task or ping me onwiki. Thanks a lot, Lea Lacroix (WMDE) 15:08, 14 sie 2018 (CEST)
Wiadomości o reformie prawa autorskiego
Jak być może już wiecie, w Unii Europejskiej trwa obecnie proces reformowania prawa autorskiego, który wpłynie na Wikipedię i inne projekty związane z wolną wiedzą. W lipcu Parlament Europejski omawiał propozycję, która byłaby szkodliwa dla swobody ekspresji i współpracy online. W czerwcu i lipcu wiele lokalnych organizacji i społeczności Wikimedia podjęło działania, mające wyrażać ich sprzeciw i które przyczyniły się do odrzucenia tej wersji propozycji.
Po przerwie wakacyjnej, 12 września, w Parlamencie Europejskim odbędzie się głosowanie nad nowymi poprawkami do propozycji Komisji Europejskiej. Europarlamentarzyści mogą zgłaszać własne propozycje poprawek do 5 września. Europejskie organizacje ruchu Wikimedia, członkowie grupy Free Knowledge Advocacy Group EU oraz pracownicy Wikimedia Foundation wspólnie pracują nad tym, by w dyskusji zaproponowano poprawki gwarantujące ochronę i rozwój wolnych treści, w tym nowe spojrzenie na artykuł 13, czy ochronę domeny publicznej, wolności panoramy i treści tworzonych przez użytkowników.
W nadchodzących tygodniach dla świata Wikimediów ważne będzie promowanie naszej wizji ochrony prawnoautorskiej, która wspierać będzie współdzielenie w Internecie sumy ludzkiej wiedzy. Jeśli Wasza społeczność chce włączyć się w kolejne działania związane z dyskursem prawnoautorskim, docenimy podjęcie współpracy z nami, by nasz głos brzmiał tak samo w wielu krajach (eupolicy@wikimedia.be lub policy@wikimedia.org). Chcemy promować sensowne zasady prawa autorskiego, ułatwiające dostęp do informacji i wiedzy, nie zaś jedynie doprowadzić do zatrzymania niefortunnych proponowanych rozwiązań.
Pomóc możecie tłumacząc i rozpowszechniając materiały informacyjne w Waszym języku, rozsyłając notki prasowe do krajowych mediów, kontaktując się z europarlamentarzystami z Waszego regionu i przekazując im sugestie sensownych poprawek dyrektywy prawnoautorskiej lub biorąc udział w wydarzeniach organizowanych w Brukseli i Strasburgu.
Niedługo udostępnimy informacje o działaniach społecznych, które planujemy przeprowadzić 6 i 11 września. Podzielimy się też ważnymi informacjami o dyskutowanych i proponowanych poprawkach do dyrektywy prawnoautorskiej.--Dimi z (dyskusja) 11:49, 21 sie 2018 (CEST)
- A co konkretnie może się zmienić? Banana22100 (dyskusja) 00:28, 26 sie 2018 (CEST)
- Bo to, co według mnie warto by zrobić, to legalizacja fair use. Banana22100 (dyskusja) 17:16, 26 sie 2018 (CEST)
Editing of sitewide CSS/JS is only possible for interface administrators from now
(Pomóż przetłumaczyć na Twój język)
Hi all,
as announced previously, permission handling for CSS/JS pages has changed: only members of the interface-admin (Administratorzy interfejsu) group, and a few highly privileged global groups such as stewards, can edit CSS/JS pages that they do not own (that is, any page ending with .css or .js that is either in the MediaWiki: namespace or is another user's user subpage). This is done to improve the security of readers and editors of Wikimedia projects. More information is available at Creation of separate user group for editing sitewide CSS/JS. If you encounter any unexpected problems, please contact me or file a bug.
Thanks!
Tgr (talk) 14:40, 27 sie 2018 (CEST) (via global message delivery)
- Dopisałem botem nowe języki zalegające na Wikipedysta:AlkamidBot/nowe języki, lecz należy jeszcze uzupełnić MediaWiki:Gadget-langdata.js. W tej chwili nikt w projekcie nie ma dostępu do tej listy. Języki do dodania znajdują się tutaj (z wyjątkiem wschodniokadazańskiego). Pozdrawiam, Peter Bowman (dyskusja) 14:18, 28 sie 2018 (CEST)
Głoski [i̯] i [ĩ̯]
Zauważyłem, że na tej stronie symbole i̯ i ĩ̯ (w przeciwieństwie do u̯ i ũ̯) składają się z trzech elementów:
- i lub ĩ
- HAIR SPACE (U+200A)
- COMBINING INVERTED BREVE BELOW (U+032F)
Po co ta spacja w środku? Nie dość, że jest funkcjonalnie nieuzasadniona, to przez nią w każdym artykule, który ma podaną wymowę w AS (jak i na wspomnianej stronie), brewis znajduje się nie dokładnie pod literą, ale przesunięty w prawo (zob. np. jajko). Piotr89 (dyskusja) 17:12, 29 sie 2018 (CEST)
- Ja w „jajko” widzę brewis idealnie wyśrodkowany, zaś w Twoich powyższych przykładach jest lekko przesunięty w lewo. Może @Olaf będzie pamiętał, jakie okoliczności przemówiły ku takiemu rozwiązaniu. Peter Bowman (dyskusja) 17:45, 29 sie 2018 (CEST)
- Widzę to tak jak Peter. Nie pamiętam już, dlaczego tak to kiedyś zaprogramowałem, ale pamiętam że eksperymentowałem z różnymi zestawieniami znaków oraz fontami i wybierałem taki sposób kodowania oraz font, który najlepiej wyglądał na różnych przeglądarkach, więc prawdopodobnie wtedy też tak to widziałem i uznałem że tak jest lepiej bo brewis jest lepiej wyśrodkowany. Olaf (dyskusja) 01:12, 1 wrz 2018 (CEST)
U mnie Firefox, Chrome i Edge w Windowsie 10 wyświetlają te brewisy przesunięte w prawo, bez względu na to, czy jestem zalogowany (skórka Książka), czy nie. Oczywiście jestem za tym, żeby to wyglądało porządnie, ale nie jestem pewny, czy wstawianie dodatkowych znaków jest właściwe. Jeśli ktoś będzie chciał nie tylko popatrzeć na wymowę, ale i ją skopiować, to się może zdziwić, tym bardziej że w Chromie i Edge'u dwuklik zatrzymuje się na tej spacji i nie zaznacza całego wyrazu. Piotr89 (dyskusja) 14:09, 1 wrz 2018 (CEST)
- Poprawiam się: na Linuksie (FF) widzę brewis na swoim miejscu, a na Windowsie (też FF) jest przesunięty w prawo. Peter Bowman (dyskusja) 17:41, 3 wrz 2018 (CEST)
Read-only mode for up to an hour on 12 September and 10 October
Przeczytaj w innym języku • Pomóż przetłumaczyć na Twój język
Wikimedia Foundation będzie testowała swoją drugą, zapasową serwerownię. Upewni to nas, że Wikipedia i inne strony Wikimedia będą zawsze online, nawet w przypadku kataklizmu. Aby upewnić się, że wszystko działa, departament Technologii Wikimedia musi przeprowadzić zaplanowany test. Pokaże on, czy są w stanie przełączyć się z jednej serwerowni na inną. Wymaga to przygotowań do testu przez wiele zespołów i ich dostępności w celu naprawy jakichkolwiek nieprzewidzianych problemów.
Cały ruch zostanie przełączony na zapasową serwerownię w środę 12 września 2018. W środę 10 października przełączą z powrotem na podstawową serwerownię.
Niestety, z powodu niektórych ograniczeń w MediaWiki, wszystkie operacje edycyjne muszą zostać przerwane podczas tych dwóch przełączeń. Przepraszamy za te utrudnienia. Będziemy pracować nad tym, aby je zminimalizować w przyszłości.
Każdą wiki przez krótki czas będzie można tylko czytać, ale nie edytować.
- Edytowanie nie będzie możliwe przez maksymalnie godzinę, w środę, 12 września i 10 października. Test rozpocznie się o 14:00 UTC (15:00 BST, 16:00 CEST, 10:00 EDT, 07:00 PDT, 23:00 JST oraz w Nowej Zelandii o 02:00 NZST w czwartek 13 września i czwartek 11 października).
- Jeżeli będziesz próbował edytować lub zapisywać podczas tych okresów, zobaczysz komunikat błędu. Mamy nadzieję, że żadne edycje nie zostaną utracone podczas tego czasu, ale nie możemy tego zagwarantować. Jeżeli zauważysz komunikat o błędzie, poczekaj aż wszystko wróci do normy. Wtedy będzie możliwość zapisania swoich zmian. Zalecamy jednak zrobienie kopii swoich zmian na wszelki wypadek.
Inne skutki:
- Zadania w tle będą wolniejsze, a niektóre mogą być przerywane. Czerwone linki mogą nie być aktualizowane tak szybko jak zwykle. Jeżeli utworzysz artykuł, do którego gdzieś prowadzi jakiś link to ten link będzie dłużej czerwony niż zwykle. Niektóre długo działające skrypty zostaną zatrzymane.
- Nie będzie zmian w kodzie na serwerze między 10 września 2018 a 8 października 2018. Nie będą miały miejsca wdrożenia kodu o małym znaczeniu.
W razie konieczności, terminy testu mogą się przesunąć. Możesz zapoznać się z harmonogramem na wikitech.wikimedia.org. Wszelkie zmiany będą ogłoszone w tymże harmonogramie. Będzie więcej powiadomień na ten temat. Prosimy, podziel się tą informacją ze swoją społecznością. /User:Johan(WMF) (talk)
15:33, 6 wrz 2018 (CEST)
Przykłady z głowy
W polskojęzycznej Wikipedii pojawił się niedawno artykuł w:pl:Praktyczny słownik współczesnej polszczyzny a w nim sekcja "Krytyka" a w niej zdanie: "Skrytykowano również przykłady, których nie zaczerpnięto z korpusów językowych, a które zostały stworzone przez autorów słownika, w związku z czym ich funkcja ilustracyjna jest iluzoryczna." Sęk w tym, że w naszych hasłach jest mnóstwo przykładów nie zaczerpniętych ze źródeł, tylko napisanych własnoręcznie przez autorów haseł. Czy w trosce o jakość nie powinniśmy wdrożyć jakichś narzędzi do wyłapywania przykładów bez źródeł i zastępowania ich przykładami ze źródłem. Co o tym myślicie? KaMan (dyskusja) 14:17, 24 wrz 2018 (CEST)
- Jaka jest rola rola przykładów w artykule słownika?
- Podać prawidłowe konstrukcje i konteksty, tak jak słowo hasłowe jest NATURALNIE UŻYWANE przez użytkowników języka.
- Podać UŻYWANE odcienie znaczeniowe słowa hasłowego, które jest trudno (albo prawie niemożliwe) podać za pomocą definicji opisowych albo listy synonimów lub słów bliskoznacznych.
- • Dla obu tych funkcji jest ważne aby przykłady były oparte na autentycznych wypowiedziach. Wymyślone przykłady nie spełniają tej roli: są SZTUCZNE, albo sztucznie uproszczone. Słownik jest przeznaczony nie tylko dla początkujących, ale również dla uczących się na poziomie zaawansowanym, a nawet tłumaczy, którzy szukają najwłaściwszego sposobu wyrażenia jakiejś treści. A nasz Wikisłownik zawiera niestety aż za dużo przykładów typu "Ala ma kota".
- • Z tego wszystkiego nie wynika jednak, że wszystkie przykłady powinny być wiernymi cytatami autentycznych wypowiedzi. Odwrotnie: natłok zbędnych, nieistotnych dla słowa hasłowego, wyrazów utrudnia zarówno zrozumienie jak i używanie definiowanego słowa. Zatem, przykłady słownikowe powinny być raczej uproszczonymi wersjami autentycznych wypowiedzi. Zastanawiam się nawet, czy muszą to być pełne zdania. Może wystarczyłyby zręcznie wybrane, w miarę samodzielne, frazy? Wiele profesjonalnych słowników tak właśnie robi.
- • Z tego nie wynika również, że przykłady nie mogą być wiernymi cytatami autentycznych wypowiedzi. Odwrotnie: znane cytaty z wierszy, piosenek, przemówień itp., a które może nie są w pełni skonwencjonalizowanymi zwrotami - typu "Litwo, ojczyzno moja..." - mogą podawać ważne wartości stylistyczne i kulturowe, co też należy do języka. Wiele profesjonalnych słowników zamieszcza takie cytaty - chociażby dla zwiększenia atrakcyjności słownika.
- • W sumie uważam, że wymaganie aby wszystkie przykłady były wiernymi cytatami autentycznych wypowiedzi - z podanymi źródłami - jest zbyt formalistyczne i nadaje się tylko do opracowań naukowych. Jednak wszystkie przykłady powinny być oparte na autentycznych wypowiedziach - bez podawania źródeł. Wierne cytaty są pożądane i wartościowe, ale tylko wtedy, gdy mają swoje uzasadnienie - kulturowe lub stylistyczne.
- --Meander (dyskusja) 16:56, 24 wrz 2018 (CEST)
- @Meander Z drugiej strony cały słownik Doroszewskiego opiera się na cytatach opartych na źródłach. Nie ma tam chyba ani jednego przykładu z głowy, a przykładów tam tysiące. Pierwszy lepszy przykład z brzegu: https://sjp.pwn.pl/doroszewski/puszcza;5488173.html Cała sztuka polega na wyborze takiego cytatu, który będzie zwięzły bez zbędnych wtrąceń. NKJP.pl ma obszerne zasoby do wyboru. Nie wiem niestety czy inne języki mają jakiś odpowiednik NKJP. KaMan (dyskusja) 12:19, 25 wrz 2018 (CEST)
- @Meander Z drugiej strony cały słownik Doroszewskiego opiera się na cytatach opartych na źródłach. Nie ma tam chyba ani jednego przykładu z głowy, a przykładów tam tysiące. Pierwszy lepszy przykład z brzegu: https://sjp.pwn.pl/doroszewski/puszcza;5488173.html Cała sztuka polega na wyborze takiego cytatu, który będzie zwięzły bez zbędnych wtrąceń. NKJP.pl ma obszerne zasoby do wyboru. Nie wiem niestety czy inne języki mają jakiś odpowiednik NKJP. KaMan (dyskusja) 12:19, 25 wrz 2018 (CEST)
- Jestem tu od niedawna, ale chyba mogę się wtrącić? Wiele słowników, zwłaszcza języka potocznego, socjolektów czy gwar, jako źródło podaje „zasłyszane”. W pracach naukowych dotyczących słownictwa i jego używania też często podaje się cytaty spisane ze słuchu, podane w ankietach przez „zwykłych” ludzi (np. prosi się iluś policjantów, żeby napisali, jak mówią na różne przedmioty czy czynności związane z ich pracą) lub zaczerpnięte z komentarzy zamieszczanych w Internecie. Nie bardzo rozumiem, dlaczego zdanie wymyślone przez zwykłego użytkownika języka ma być gorsze, a masowe cytowanie z tekstów literackich (w których zresztą w ogóle nie znajdziemy wszystkich słów), co do których nie wygasły majątkowe prawa autorskie, jest niezbyt rozsądne. Nie widzę racjonalnych powodów, dla których co do współczesnego języka należałoby zakazać tworzenia przykładów z głowy – język tworzą jego użytkownicy i to nie tylko nobliści, ale też pan X spod monopolowego. Uważam, że jedynie nie powinno być w przykładach błędów językowych, bo uznaję je za wzór stosowania danego słowa czy zwrotu. Natomiast jeśli chodzi o słownictwo dawne czy wręcz np. j. staropolski, tutaj byłoby wskazane użyć cytatu, który pokazałby autentyczne zastosowanie wyrazów w dawnych czasach.
Myślę też, że we wspomnianej krytyce Praktycznego słownika współczesnej polszczyzny chodziło nie o to, że przykłady były wymyślone, lecz że były wymyślone przez językoznawców (bądź językoznawcę), a przez to mogłyby być naciągnięte do punktu widzenia danego lingwisty, ale Wikisłownik tworzą różni ludzie z różnych środowisk, o różnym wykształceniu i poglądach, więc chyba nie ma tu zagrożenia, że cały słownik zostanie podporządkowany jakiejś osobistej idei. Raczej przeciwnie – przykłady mogą być bardzo różnorodne. Zoriana77 (dyskusja) 13:32, 25 wrz 2018 (CEST)- @Zoriana77: (edytowane) Tak, to właśnie o to chodzi, że "język tworzą jego użytkownicy", również "pan X spod monopolowego", a cytaty spisane ze słuchu są - w pewnym sensie - najbardziej autentyczne, jakie można sobie wyobrazić. Natomiast słownikarze języka nie tworzą, lecz go rejestrują. Co prawda słownikarz "wymyślający" przykłady w swoim języku ojczystym też jest użytkownikiem tego języka, jednak aby jego przykłady uważać za autentyczne musiałby on zapomnieć, że jest słownikarzem i całkowicie wczuć się w tę sytuację, którą jego przykład opisuje - tak jakby się w niej znajdował. Taką zdolność mają pisarze i dlatego ich język można uważać za autentyczny. Niestety, nie każdy słownikarz takie umiejętności posiada i wtedy jego przykłady są - jak to nazwałaś - naciągane (bardzo trafne określenie!). Naciągane do celu słownikarza, tzn. stworzenia ilustracji dla jakiegoś zjawiska językowego. Dla mnie nie jest to "prawdziwy" język.
- • Ja prawdopodobnie dlatego tak ostro widzę te sprawy, gdyż zajmuję się tu językiem, który nie jest moim ojczystym. W ten sposób widzę go niejako z zewnątrz, obiektywnie. I choć żyję w tym kraju, gdzie mówi się tym językiem, to w zasadzie zawsze sprawdzam, czy dana wypowiedź jest naturalna dla rodowitych użytkowników tego języka. Na szczęście nie jest to trudne w erze internetu i korpusów. --Meander (dyskusja) 04:35, 26 wrz 2018 (CEST)
- @Meander: No i widać, że nie jest to takie proste zagadnienie. Wydawało mi się, że umiejętność wymyślenia logicznego i naturalnego zdania z użyciem danego słowa w ojczystym języku to poziom jakiejś 5 klasy szkoły podstawowej. A z drugiej strony w użytym w Wikisłowniku przykładzie z korpusu widziałam ewidentny błąd składniowy…
Jesteś pewien, że wśród użytkowników Wikisłownika nie ma osób utalentowanych literacko? :-)
Natomiast przykłady w językach obcych to osobna bajka. Może to głupie pytanie, ale czy nie można by kopiować ich z Wikisłownika w danym języku? Zawsze to bardziej prawdopodobne, że zdanie będzie naturalne, a pewnie większość haseł w polskim tworzą Polacy, w szwedzkim Szwedzi itd. Na razie raczej się przyglądam i edytuję głównie drobiazgi, ale pragnę w przyszłości tworzyć więcej haseł w j. czeskim, więc też chciałabym mieć jasność, jak będzie najlepiej. Zoriana77 (dyskusja) 12:13, 27 wrz 2018 (CEST)
- @Zoriana77: Nie twierdziłem, że "wśród użytkowników Wikisłownika nie ma osób utalentowanych literacko", lecz że "nie każdy słownikarz takie umiejętności posiada". Nie wiem ilu wikisłownikarzy ma takie talenty, ale myślę, że nie są one potrzebne. Uważam bowiem, że zajęciem słownikarza jest badanie języka, a nie twórczość literacka.
- • Źródła internetowe, zasłyszane, czy nawet media, mimo że są autentycznymi źródłami bynajmniej nie muszą być bezbłędne. Ludzie na co dzień wyrażają się często nieskładnie i niepoprawnie - z pośpiechu i z innnych przyczyn. Język idealny jest zakłócany w świecie rzeczywistym. Ale wydaje mi się, że językoznawcy nie mają kłopotu z filtrowaniem tych zakłóceń.
- • Oczywiście, że korzystam ze szwedzkiego wikisłownika - nie tylko jeśli chodzi o przykłady. Sam byłem tam czynny przez kilka lat, więc czasem kopiuję po prostu swoją pracę. Ale z przykładami jest tam podobnie jak w polskim wikisłowniku. Wiele przykładów też jest zmyślonych i sztucznych. Choć jest też wiele autentycznych i wtedy oszczędza się żmudnego przeszukiwania internetu i korpusów, żeby znaleźć pasujący przykład. Chociaż ja osobiście akurat to lubię. Jestem zawodowo naukowcem - choć w innej dziedzinie - i mam we krwi grzebanie w faktach, a także szacunek dla rzeczywistości w ogóle.
- -- Ciekawie wymienia się z Tobą doświadczenia. Pozdrawiam. --Meander (dyskusja) 15:27, 28 wrz 2018 (CEST)
- Wzajemnie. Zoriana77 (dyskusja) 16:24, 28 wrz 2018 (CEST)
- @Meander: No i widać, że nie jest to takie proste zagadnienie. Wydawało mi się, że umiejętność wymyślenia logicznego i naturalnego zdania z użyciem danego słowa w ojczystym języku to poziom jakiejś 5 klasy szkoły podstawowej. A z drugiej strony w użytym w Wikisłowniku przykładzie z korpusu widziałam ewidentny błąd składniowy…
- Nie uważam, że należy wszędzie konsekwentnie używać przykładów z literatury. Nie mamy własnego korpusu (jest tylko Wikipedia i Wikiźródła - opóźnione z wiadomych przyczyn o jakieś 100 lat). Korpusy publicznie dostępne zawierają zbyt mały zasób słownictwa w stosunku do tego co opisuje Wikipedia i Wikisłownik. Najważniejsze jednak, że w wielu przypadkach takie autentyczne cytaty nic nie wnoszą, ale są długie, bardzo długie (jak oceniasz cytaty z moich haseł baszybuzuk i kluczwójt?). Ich znaczenie bywa kulturowe, albo historyczne (np. przymiotnik kilimandżarski, niby nie istnieje, ale w źródłach wiąże się z wyprawą Henryka Sienkiewicza). Narażamy się też na to, że cytaty będą mocno wartościujące, choć to nie problem jeśli koniecznie chcemy prezentować tło kulturowe. Często szukanie cytatów jest trudne. Przeczesanie wyników Gugla by wśród dziesiątek kopii Wikipedii znaleźć 3-4 autentyczne użycia słowa addisabebski, wychodzi z tego dowód istnienia, a w mniejszym stopniu użycie. Mamy też zwykle masę cytatów z czasów, gdy ortografia polska była inna. A jeszcze co do Doroszewskiego to coś mi się zdaje, że niektóre cytaty (czy definicje) tam są takie same jak u Lindego, Okcydent (dyskusja) 12:41, 25 wrz 2018 (CEST)
- Jestem tu od niedawna, ale chyba mogę się wtrącić? Wiele słowników, zwłaszcza języka potocznego, socjolektów czy gwar, jako źródło podaje „zasłyszane”. W pracach naukowych dotyczących słownictwa i jego używania też często podaje się cytaty spisane ze słuchu, podane w ankietach przez „zwykłych” ludzi (np. prosi się iluś policjantów, żeby napisali, jak mówią na różne przedmioty czy czynności związane z ich pracą) lub zaczerpnięte z komentarzy zamieszczanych w Internecie. Nie bardzo rozumiem, dlaczego zdanie wymyślone przez zwykłego użytkownika języka ma być gorsze, a masowe cytowanie z tekstów literackich (w których zresztą w ogóle nie znajdziemy wszystkich słów), co do których nie wygasły majątkowe prawa autorskie, jest niezbyt rozsądne. Nie widzę racjonalnych powodów, dla których co do współczesnego języka należałoby zakazać tworzenia przykładów z głowy – język tworzą jego użytkownicy i to nie tylko nobliści, ale też pan X spod monopolowego. Uważam, że jedynie nie powinno być w przykładach błędów językowych, bo uznaję je za wzór stosowania danego słowa czy zwrotu. Natomiast jeśli chodzi o słownictwo dawne czy wręcz np. j. staropolski, tutaj byłoby wskazane użyć cytatu, który pokazałby autentyczne zastosowanie wyrazów w dawnych czasach.
- Dawniej pisałem dużo haseł hiszpańskich, chyba tylko trzy razy sięgnąłem po przykłady z literatury. Zdałem sobie sprawę, że nie ma to sensu: albo szukam „oficjalnego” przekładu (czyli znajdę tę samą książkę przetłumaczoną po polsku), co czasem jest utrudnione lub niemożliwe i, z wiadomych powodów, wymaga podania dwóch przypisów, albo tłumaczę „z głowy”, co w przypadku literatury klasycznej, na którą się wtedy zdecydowałem, przychodziło mi z trudnością. W drugim przypadku polskojęzyczna część przykładu jest wymyślona przeze mnie – wolę więc wymyślić też hiszpańską, a potem swobodnie przetłumaczyć. Podobna dyskusja wywiązała się kilka lat temu: WS:Bar/Archiwum 15#Uźródławianie cytatów. Pozdrawiam, Peter Bowman (dyskusja) 13:40, 25 wrz 2018 (CEST)
- @Peter Bowman: (edytowane) Poruszyłeś ważny temat tłumaczenia, gdzie problem naturalności przykładów jest spotęgowany do kwadratu. Ponieważ tłumaczenie między językami rzadko jest odpowiedniością jeden do jednego, to poszczególne tłumaczenia mogą różnić się między sobą, nawet jeśli są poprawne i naturalne - zależnie od kryteriów tłumacza. Ponadto, tłumacze nie zawsze są (dobrymi) pisarzami, czego skutkiem są nieudane tłumaczenia. Moja metoda polega na szukaniu autentycznych przykładów szwedzkich (w języku, którym się tu zajmuję), a następnie własnoręcznym ich tłumaczeniu na polski. Wychodzę po prostu z założenia, że w haśle obcojęzycznym część obcojęzyczna jest najważniejsza - to jest to, czego zwykły użytkownik słownika przede wszystkim szuka.
- • Mam natomiast wrażenie jakby wielu wikisłownikarzy stosowało metodę "odwrotnego naciągania" (z tego, co piszesz, nie jest to Twoją, Peter, metodą): najpierw wymyślają polski przykład, a potem tłumaczą go własnoręcznie na język oryginalny. Widuję tu szwedzkie przykłady, które niby są formalnie poprawne, ale żaden Szwed tak nie powie. Są to po prostu polskie przykłady wyrażone szwedzkimi słowami i szwedzką gramatyką, a jednak nie jest to po szwedzku. --Meander (dyskusja) 04:35, 26 wrz 2018 (CEST)
- Dawniej pisałem dużo haseł hiszpańskich, chyba tylko trzy razy sięgnąłem po przykłady z literatury. Zdałem sobie sprawę, że nie ma to sensu: albo szukam „oficjalnego” przekładu (czyli znajdę tę samą książkę przetłumaczoną po polsku), co czasem jest utrudnione lub niemożliwe i, z wiadomych powodów, wymaga podania dwóch przypisów, albo tłumaczę „z głowy”, co w przypadku literatury klasycznej, na którą się wtedy zdecydowałem, przychodziło mi z trudnością. W drugim przypadku polskojęzyczna część przykładu jest wymyślona przeze mnie – wolę więc wymyślić też hiszpańską, a potem swobodnie przetłumaczyć. Podobna dyskusja wywiązała się kilka lat temu: WS:Bar/Archiwum 15#Uźródławianie cytatów. Pozdrawiam, Peter Bowman (dyskusja) 13:40, 25 wrz 2018 (CEST)
- Kolegom z Wikisłownika podrzucę taką ciekawą lekturę (s.34). Wydaje się, że ten temat już przerobiono i nie ma idealnego wyjścia. Z wikipozdrowieniem Kicior99 (dyskusja) 20:05, 25 wrz 2018 (CEST)
- Ja nie uważam cytatów zaczerpniętych z autentycznych tekstów za wymagane, ale mocno wskazane. Pokazują prawdziwe użycie wyrazu w prawdziwym otoczeniu, a na dokładkę uźródławiają artykuł i podnoszą jego wiarygodność. Oczywiście trzeba mieć trochę wyczucia, aby wybrać np. z korpusu przykład dobry; jednak z tego, co widuję, to przykłady wymyślane wymagają wyczucia znacznie więcej, widzę niestety, że wiele u nas jest wymyślonych przykładów, których sztuczność wręcz bije po oczach, jako że nie każdy wyczucie do wymyślania przykładów ma. Banalne przykład mogą być pomocne w podstawowych hasłach obcojęzycznych uczącym się danego języka, ale nie przy opisywaniu języka polskiego.
- Co innego wyrazy dawne – uważam, że w ich przypadku cytaty muszą być „naturalne”.
- Pozdrawiam, PiotrekDDYSKUSJA 20:14, 25 wrz 2018 (CEST)
- PS: Krytyka braku autentycznych cytatów w PSWP dotyczyła tego słownika jako pracy naukowej. Nie wyjawię swojej opinii na te tematy, ale wspomnę, że ja nie widzę, byśmy my dążyli do uczynienia z Wikisłownika poważnego dzieła naukowego? Raczej chyba w kierunku praktycznego użycia?
- Przykłady z głowy mają (powinny mieć) tę zaletę, że są wymyślane pod kątem potrzeb słownika, tzn. mają być proste (ale nie prostackie), mają możliwie wyczerpująco zawierać elementy składni/rekcji danego słowa (nie brzmiąc dziwacznie) - trudno znaleźć coś takiego w dostępnych materiałach. Uważam, ze jeżeli dysponuje się (poszuka się) dobrego przykładu, to warto taki przykład przytoczyć, ale jeżeli nie, to lepszy jest skrojony na potrzeby słownika przykład z głowy (zrozumiały dla kogoś, kto uczy się np. polskiego), aniżeli literacki przykład często archaicznej polszczyzny. --EdytaT (dyskusja) 20:59, 25 wrz 2018 (CEST)
- @EdytaT: Tak, trudno jest znaleźć autentyczne wypowiedzi, które dobrze ilustrują prawidłowe konstrukcje i konteksty oraz odcienie znaczeniowe słowa hasłowego, a jednocześnie nie zawierają zbędnego balastu. Wyjściem są uproszczone, zmodyfikowane wersje autentycznych wypowiedzi, gdzie ten zbędny balast jest usunięty. W ten sposób zaspokajamy potrzeby słownika z szacunkiem dla autentyczności. Wiele profesjonalnych słowników tak właśnie robi. --Meander (dyskusja) 19:34, 27 wrz 2018 (CEST)
- Na marginesie: mam złe zdanie o Zgółkowej jako autorce. Swój słownik gwary uczniowskiej zbudowała na podstawie ankiet rozdawanych wśród studentów. Ich wypełnienie było warunkiem zaliczenia jakiegoś tam przedmiotu. Zatem niektórzy studenci wpisywali jakieś głupoty z głowy, i one potem trafiały do tego słownika jako "gwara uczniowska". Znam osobę, która tak właśnie zrobiła i potem odkryła, że jakieś tam wymyślone słowo czy znaczenie jest w druku. Wiem, że to tylko anegdota i nie mam ku temu żadnych dowodów, ale w jej PSWP jest np. złytoptak, pytanie skąd się wzięło to słowo i czy też nie z jakichś mało wiarygodnych ankiet? Nostrix (dyskusja) 12:25, 26 wrz 2018 (CEST)
- @Nostrix Aż pogóglowałem za złytoptakiem. Coś jest - lata 50-70 XX wieku.
- (1957) O POTRZEBIE „ZŁYTOPTAKÓW" Po odczycie Artura Sandauera o literaturze polskiej ostatniego dziesięciolecia, wygłoszonym w Paryżu pod egidą ,J^ettres Nouvelles", odezwał się w prasie krajowej dobrze nam znany motyw „złytoptaka"
- (1974) Jan Błoński Prawdziwa szkoła krytyk się nie boi (II) : głos złytoptaka
- Może autorzy mieli dobre korpusy językowe? Albo spisywali wszystko jak leci :) Okcydent (dyskusja) 12:41, 26 wrz 2018 (CEST)
- @Nostrix, @Okcydent: Jeśli już jesteśmy w temacie złytoptaków, które Okcydent znalazł w tekstach z lat 50. i 70. (:D), to chciałbym wskazać na tworzone czasami w Wikisłowniku przez niektórych hasła o słowach z rzekomej mowy potocznej czy młodzieżowej, które nie pojawiają się w żadnych dostępnych powszechnie na Internecie słownikach, bez żadnego odniesienia do źródła słownikowego, z wymyślonymi cytatami, na zasadzie, że autor twierdzi „a u mnie w szkole tak muwio!” i my mamy mu na słowo wierzyć, bo przecież ludzie w sieci nie kłamią. Pytanie – kto i jak będzie mógł to zweryfikować za 50, 60 czy 70 lat? (Zanim ktoś wspomni o Internecie – już teraz większość stron amerykańskich z lat 90. jest poza naszym zasięgiem, a minęło ponad 20 lat, nie 50). Taka kwestia łącząca oba tematy w tej sekcji. Pozdrawiam serdecznie z moją obsesją na punkcie weryfikowalności, PiotrekDDYSKUSJA 15:13, 26 wrz 2018 (CEST)
- Ale chyba kwestię weryfikowalności danego słowa rozwiązuje ewentualny przypis przy znaczeniu, a nie przykład?
Co do Zgółkowej nie bardzo chce mi się w wierzyć w taką postawę wykładowcy. Na moich studiach kiedyś zaproponowano dobrowolne wypełnienie ankiety na temat poprawności językowej i nikt nie dostawał za to zaliczenia, tylko podziękowanie za poświęcony czas. Jeśli jednak faktycznie tak zrobiła, to fatalnie. Z tym że wypisywanie głupot w ankiecie, która ma stanowić materiał leksykalny do pracy naukowej/słownika, to też nieetyczne postępowanie i dziwię się, że ktoś się tym chwali.
Słowa złytoptak nie znałam, ale swego czasu na mojej uczelni funkcjonował tuptak (< tu ptak) i dla wszystkich z mojego roku (i nie tylko), było jasne, co to znaczy; dla kogoś z zewnątrz – już nie. :-) Sama kiedyś pisałam pracę na podstawie ankiet i wyrazy, które pojawiały się w jednej tylko ankiecie, a w innych nie, uznałam za prawdopodobnie funkcjonujące bardzo lokalnie, więc nieoddające słownictwa całego środowiska. Nie ujmowałam ich w stworzonym słowniczku socjolektu. Dlatego nie zarzucałabym z góry komuś kłamstwa, lecz raczej zwróciłabym uwagę, że to, iż w jednej szkole tak mówią, nie znaczy, że mówią tak w większości szkół. :-) Choć oczywiście wygłupy się zdarzają. Niedawno czytałam artykuł, który też był oparty na ankietach, i – niestety – autorka postanowiła nie pomijać odpowiedzi, które były jawnymi drwinami, np. na pytanie, z jakiego języka pochodzi ta nazwa, ktoś odpowiadał „z języka nienawiści”, „z jakiegoś skośnookiego” itd. Nie pasowało mi to w pracy naukowej. Zoriana77 (dyskusja) 16:44, 26 wrz 2018 (CEST)
- Ale chyba kwestię weryfikowalności danego słowa rozwiązuje ewentualny przypis przy znaczeniu, a nie przykład?
- @Nostrix, @Okcydent: Jeśli już jesteśmy w temacie złytoptaków, które Okcydent znalazł w tekstach z lat 50. i 70. (:D), to chciałbym wskazać na tworzone czasami w Wikisłowniku przez niektórych hasła o słowach z rzekomej mowy potocznej czy młodzieżowej, które nie pojawiają się w żadnych dostępnych powszechnie na Internecie słownikach, bez żadnego odniesienia do źródła słownikowego, z wymyślonymi cytatami, na zasadzie, że autor twierdzi „a u mnie w szkole tak muwio!” i my mamy mu na słowo wierzyć, bo przecież ludzie w sieci nie kłamią. Pytanie – kto i jak będzie mógł to zweryfikować za 50, 60 czy 70 lat? (Zanim ktoś wspomni o Internecie – już teraz większość stron amerykańskich z lat 90. jest poza naszym zasięgiem, a minęło ponad 20 lat, nie 50). Taka kwestia łącząca oba tematy w tej sekcji. Pozdrawiam serdecznie z moją obsesją na punkcie weryfikowalności, PiotrekDDYSKUSJA 15:13, 26 wrz 2018 (CEST)
- W kwestii przykładów zgadzam się z EdytąT. Pozdrawiam Krokus (dyskusja) 17:46, 26 wrz 2018 (CEST)
- I ja również --Richiski (dyskusja) 13:14, 27 wrz 2018 (CEST)
- @Nostrix Aż pogóglowałem za złytoptakiem. Coś jest - lata 50-70 XX wieku.
Domena Wikisłownik.pl
Niektórzy z was mogą pamiętać, iż domena internetowa wikisłownik.pl (xn--wikisownik-e0b.pl) była przez wiele lat zarejestrowana przez firmę zajmującą się cybersquattingiem, tj. kupowaniem domen internetowych w celu odsprzedania ich z zyskiem. Kilka lat temu wyszedłem z wnioskiem do Stowarzyszenia Wikimedia Polska o odzyskanie polskich domen zawierających nazwy projektów Wikimedia, jednak uzyskałem odpowiedź odmowną i domena wikisłownik.pl (i kilka innych) musiała czekać na swoją kolej.
Wobec tego z radością informuję, iż dzisiaj — po sześciu latach oczekiwania — udało mi się w końcu odzyskać tę domenę i jest ona moją własnością. Po odkupieniu przeze mnie domeny wiktionary.pl w styczniu 2017, domena wikisłownik.pl była ostatnią domeną internetową powiązaną z projektami Wikimedia, która znajdowała się w posiadaniu cybersquatterów, stąd też moja ogromna radość z jej odzyskania.
Domena wikisłownik.pl została przeze mnie opłacona na kolejnych 6 lat (do 6 października 2024) i skonfigurowałem ją jako przekierowanie na stronę główną Wikisłownika, tzn. pod adres pl.wiktionary.org. Na tę chwilę nie planuję żadnych zmian w tym zakresie, ale gdyby ktoś chciał użyć tej domeny w innym celu, proszę o kontakt. Z pozdrowieniami, odder (dyskusja) 01:01, 6 paź 2018 (CEST)
- @odder: Dzięki za starania. PiotrekDDYSKUSJA 18:03, 6 paź 2018 (CEST)
- @odder: Również dzięki za zaangażowanie (w tym własnych środków finansowych) w sprawę. Pamiętam tamtą dyskusję z władzami WMPL (bo tak samo nie chcieli kilka lat temu sfinansować domeny wikiźródła.pl), ale obecnie pełnią tę funkcję już inni ludzie i jestem przekonany, że oni byliby skłonni zwrócić Ci koszty po cesji domen na WMPL. Rozważ to :). Nostrix (dyskusja) 08:40, 8 paź 2018 (CEST) (PS. wiktionary.pl nie działa -?)
- @Nostrix: Dzięki za miłe słowa. Zarówno wikiźródła.pl, jak i wikisłownik.pl przedłużyłem na co najmniej 5 lat (wikiźródła.pl wygasa w maju 2023 roku), więc jeśli Wikimedia Polska chciałoby przejąć opiekę nad tą domeną, to mamy jeszcze dużo czasu na ustalenie wszelkich szczegółów. Jeśli zaś chodzi o wiktionary.pl, to przekazałem ją Wikimedia Foundation, ale ze względów na komplikacje techniczne domena nie została ustawiona przez nich jako przekierowanie i dlatego nie działa. Jest jednak jak najbardziej w ich portfolio i, o ile wiem, jest przedłużana z roku na rok przez firmę MarkMonitor, która zarządza domenami w imieniu Wikimedia Foundation. odder (dyskusja) 17:14, 8 paź 2018 (CEST)
Zaimki vs. zaimki przymiotne, czyli niewydolność klasyfikacji części mowy
Przytaczam poniżej mój wpis w dyskusji hasła każdy, chociaż ten sam problem tyczy wielu innych haseł j. polskiego, a ponieważ tam temat ten był mało widoczny, więc kopiuję poniżej tekst mojego wpisu.
Próbując uzupełnić tłumaczenia tego hasła na inne języki (hiszpański, francuski, nowogrecki) napotykam na przeszkodę kwalifikacji tego hasła, gdyż nie uwzględnia się tutaj zastosowania przymiotnego tego słowa. Uważam zatem, iż powinno się odróżniać zaimek upowszchniający/wskazujący/pytajny/względny itp., od zaimka przymiotnego upowszchniającego/wskazującego/pytajnego/względnego. W obecnym stanie hasło to ma tłumaczenia np. na francuski: chaque (przymiotnik), chacun (zaimek), tout (przymiotnik albo zaimek). Użytkownik polskojęzyczny chcąc przetłumaczyć przykład polski (1.1) nie będzie wiedział, którego słowa użyć każda kobieta → chaque femme czy chacune femme (nawiasem mówiąc autor strony francuskiego hasła chaque stosuje - myśląc polskimi kategoriami - klasyfikację polską i mylnie klasyfikuje to słowo jako zaimek, a przecież jest to adjectif indéfini, czyli przymiotnik nieokreślony. Podobnie zresztą sprawa się ma z hiszpańskim czy nowogreckim (nie wiem, czy w innych też). Zatem proponuję przyjęcie pewnych cech kwalifikacji części mowy Milewskiego, aby ułatwić użytkownikom WS rozróżnienie tych pojęć w tłumaczeniach na inne języki. --Richiski (dyskusja) 21:11, 4 paź 2018 (CEST) --Richiski (dyskusja) 11:13, 6 paź 2018 (CEST)
Pokrycie słownictwa w polskich słownikach online
Przy okazji wprowadzania w Wikadanych słownictwa wraz z odsyłaczami do polskich słowników online (z wyjątkiem niestety Wikisłownika, ponieważ Wikidane nie udostępniają jeszcze powiązania z Wikisłownikiem) okazało się, że powstała ładna próbka prezentująca pokrycie słownictwa. Wybór słownictwa jest "prawie" losowy, co dzień wprowadzałem jeden pierwiastek chem, jeden owoc lub warzywo, jedno zwierzę, jedno słowo z naszej listy frekwencyjnej oraz to na co miałem ochotę jeśli miałem jeszcze wolny czas. Do tego wszystkie planety, wszystkie miesiące i wszystkie dni tygodnia. Są związki frazeologiczne jak "w aksamitnych rękawiczkach" czy "Układ Słoneczny" oraz nazwy własne jak Apolinary czy Koszalin. Osobno były liczone osobne części mowy tych samych leksemów. W ten sposób powstała próbka 1271 słów z których każde zostało zestawione z polskimi słownikami online. Pokrycie wygląda jak poniżej:
| słownik | haseł | % |
|---|---|---|
| Wikidane | 1271 | 100,00% |
| sgjp.pl | 1155 | 90,87% |
| SJP PWN | 1154 | 90,79% |
| WSO PWN | 1078 | 84,82% |
| Doroszewski PWN | 1048 | 82,45% |
| WSJP | 715 | 56,25% |
| Dobrysłownik | 645 | 50,75% |
| Kopaliński | 142 | 11,17% |
W powyższym zestawieniu dobrze wypadają SGJP i SJP PWN, ale pierwszy zawiera głównie tylko fleksję a drugi tylko definicje. Co prawda PWN w weekend uruchomił nową funkcjonalność i do każdego hasła dołącza teraz przykłady ze swojego korpusu (działa w SJP PWN i WSO PWN) ale daleko tej funkcji do doskonałości (dla pierwiastka "ameryk" zwraca przykłady z "Ameryką"). Mnie najbardziej interesuje porównanie Dobregosłownika.pl z WSJP.pl. Oba to słowniki tworzone od podstaw, oba starają się przedstawiać wszystkie aspekty słów z tym, że WSJP zdaje się kierować w doborze słownictwa frekwencją, podczas gdy Dobrysłownik chyba tworzy słowa "na zamówienie" (takie z zapytań użytkowników). Moje wrażenie jest takie, że wynik dla Dobregosłownika jest zawyżony, bowiem hasła teoretycznie istnieją ale w wielu poza listą form nie ma nic (Wystarczy porównać "spacerowicz" z WSJP z "spacerowicz" z Dobregosłownika. Najbardziej kompletne są hasła z WSJP, mają prawie zawsze etymologię, dobrze dobrane przykłady użycia i wiele innych cennych informacji. W trakcie pracy znajdywałem błędy merytoryczne zarówno w WSJP jak i Dobrymsłowniku i oba słowniki prawie natychmiast nanosiły poprawki po zawiadomieniu. Ot, takie refleksje :) KaMan (dyskusja) 14:32, 8 paź 2018 (CEST)
Rzeczowniki pospolite a zarejestrowane nazwy znaków towarowych
Niejako kontynuacja wątku Specjalna:Niezmienny link/6284911#trytytka z WS:ZB.
Otrzymałem wiadomość na skrzynkę pocztową od użytkowniczki @Anelmarianka z najwyraźniej słusznym wskazaniem, w tym przypadku odnośnie hasła „adidas”, że może dojść do naruszenia praw z naszej strony. Ten argument opiera się na Rozporządzeniu Parlamentu Europejskiego i Rady nr 2017/1001 z 14 czerwca 2017 r. w sprawie znaku towarowego. Załączam pełny tekst artykułu 12 pt. „Reprodukcja unijnego znaku towarowego w słowniku”:
- Jeżeli reprodukcja unijnego znaku towarowego w słowniku, encyklopedii lub w podobnym zbiorze informacji stwarza wrażenie, że stanowi on nazwę rodzajową towarów lub usług, dla których znak towarowy jest zarejestrowany, wydawca utworu zapewnia, na żądanie właściciela unijnego znaku towarowego, aby reprodukcji znaku towarowego, najpóźniej w następnym wydaniu publikacji, towarzyszyło wskazanie, że jest to zarejestrowany znak towarowy.
Jeżeli podążymy tą drogą – co wydaje mi się rozsądne – chyba właściwym miejscem na wskazanie pochodzenia jako nazwy znaku towarowego będzie pole etymologii. Z taką praktyką spotkałem się już w niektórych hasłach niemieckich. Peter Bowman (dyskusja) 20:48, 18 paź 2018 (CEST)
- Ja byłbym za uwagą w polu uwag, jak w haśle „paczkomat”. W polu etymologii swoją drogą. PiotrekDDYSKUSJA 21:35, 18 paź 2018 (CEST)
- Czyli w etymologii informacja, że nazwa pochodzi od firmy (tak, jak jest teraz w adidas), a w uwagach, że jest to nazwa zastrzeżona. Nostrix (dyskusja) 22:24, 18 paź 2018 (CEST)
- Niektóre hasła niemieckie zaznaczają tę informację w uwagach – czasem też w synonimach oraz w tabelce odmiany (tutaj moim zdaniem do przeniesienia w inne miejsce) – za pomocą znaków ®/©: Zyklon, Trowalisieren, Aspirin, Föhn, Fiat, BMW, Packstation, Capecitabin, Fön, Haartrockner, Schufa, Flip-Flop, Aspartam, Volkswagen, Opel, Ford, Porsche, Rolls-Royce, Audi, Mercedes-Benz, Renault, Ferrari. Niegdyś opisałem hiszpańskie hasło „tirita” pochodzące od nazwy zastrzeżonej. Peter Bowman (dyskusja) 21:02, 21 paź 2018 (CEST)
Nawiązuję do powyższego. Rozumiem, że Wikisłownik aspiruje do objęcia jak największej liczby słów występujących w korpusie języka polskiego, pozyskując je bezpośrednio od użytkowników.
Nie jest dla mnie jasne, dlaczego w 'znaczeniach' hasła "adidas" nie może być umieszczone znaczenie podstawowe, tj. że jest to zarejestrowany znak towarowy, tak jak uczyniono to w szeregu słowników języka polskiego, w tym PWN
https://sjp.pwn.pl/szukaj/adidas.html czy PAN http://www.wsjp.pl/index.php?id_hasla=1879&id_znaczenia=5230670&l=1&ind=0 Możliwe, że uzus, na który powołujemy się w Wikisłowniku, nie jest wart dalszego kultywowania. Tym bardziej, że obowiązujące przepisy prawa stanowią jednoznacznie o sposobie zamieszczania znaków towarowych w słownikach. Nie chodzi jednak o to, aby zawrzeć w Wikisłowniku wszystkie chronione znaki towarowe, ale na pewno powinny się w nim znaleźć te, które się w danym języku zadomowiły.
Jeżeli chodzi o cytowane hasło „tirita”, to – prawdę mówiąc – nie do końca rozumiem informację zamieszczoną w dziale ‘etymologia’. Po pierwsze, termin ‘nazwa komercyjna’ jest bardzo ogólnikowy, a przez to mylący. Po drugie, określenie ‘marka’ sugeruje, że jest to jednak znak towarowy. Po trzecie, wyrażenie ‘marka stworzona przez […] i produkowana w […]’ jest dalekie od precyzji, a nawet poprawności, bo przecież nie marki się produkuje.
Chciałabym na zakończenie podkreślić, że – mimo wszelkich wątpliwości i postulatów – jestem w pełni uznania dla wszystkich osób zaangażowanych w tworzenie Wikisłownika i dla ostatecznego rezultatu. Uwzględnienie wymowy, znaczenia, odmiany, kolokacji, synonimów, etymologii poszczególnych wyrazów-haseł, a także przejrzyste opracowanie graficzne sprawiło, że Wikisłownik stał się poręcznym i podręcznym źródłem wiedzy o języku dla osób zajmujących się zawodowo tworzeniem tekstów wszelkiego rodzaju, a tym się właśnie paramy. Dlatego też zależy nam na poprawności zamieszczanej w Wikisłowniku informacji.
Sądzę, że informacja, iż adidas to zarejestrowany znak towarowy powinna być umieszczona w 'znaczeniu' hasła adidas.
- Niepodpisany komentarz User:Anelmarianka. 11:11, 30 paź 2018 (CET)
źródłosłów 2018
Ze zjazdu z Łodzi mamy sprawy do przemyślenia:
- nagrania słów
- włączenie gadżetu domyślnie dla edytowania przez formularz
Marek Mazurkiewicz (dyskusja) 11:53, 27 paź 2018 (CEST)
- Kilka lat temu @Sp5uhe zapowiadał masowe wprowadzanie nagrań wymowy: WS:Bar/Archiwum 17#Wymowa - nagrania. Peter Bowman (dyskusja) 14:02, 27 paź 2018 (CEST)
Sprawozdanie Nostriksa
Na Źródłosłowie poruszyliśmy kilka kwestii, oczywiście nie zapadły żadne decyzje - te mogą zapaść dopiero tutaj po dyskusji. Poniżej zamieszczam szersze sprawozdanie.
- Pojawił się pomysł, aby ilustrować dźwiękowo także przykłady, a nie tylko same wyrazy. Argument: czasami słowo brzmi inaczej w zdaniu, niż w izolacji. Uczący się danego języka mieliby więc lepszy materiał do nauki. Oczywiście takich nagrań byłoby początkowo dużo mniej w projekcie i byłyby to raczej głównie nagrania polskich przykładów. Bylibyśmy jednak pierwszym projektem z czymś takim, a myślę, że w przyszłości inne Wikisłowniki poszłyby naszym śladem. Stowarzyszenie mogłoby sfinansować projekt nagrania takich przykładów przez profesjonalnego lektora w studio nagraniowym (oczywiście trudno w tej chwili oszacować koszty).
- @Natalia Szafran-Kozakowska (WMPL) zorganizuje dla wikisłownikarzy konkurs edycyjny - czyli zabawę, jakich wiele jest na Wikipedii, ale na Wikisłowniku nigdy czegoś takiego nie było. Będzie to coś na wzór zabawy edycyjnej na Wikipedii. Konkurs zacznie się 1 stycznia i będzie trwał rok. W tym czasie ci wikisłownikarze, którzy będą chcieli się pobawić będą musieli wypełnić przynajmniej 80% zadań z listy (zadania nie będą się ograniczały do konkretnego języka). Pierwsze 20 osób otrzyma nagrody, którymi mają być spersonalizowane gadżety związane ze swoim nickiem i Wikisłownikiem jako takim. Już wkrótce Natalia utworzy stronę konkursu i opublikuje listę zadań, które wymyślaliśmy wspólnie podczas burzy mózgów na Źródłosłowie (wyszło nam ich 17) - ale będzie można też zaproponować własne :).
- Poruszyłem temat aplikacji mobilnej dla Wikisłownika - jak wiadomo była taka, ale Fundacja ją porzuciła i przestała rozwijać. Sama zresztą aplikacja była bardzo kiepska i niefunkcjonalna (już lepiej projekt wyglądał w mobilnych przeglądarkach, niż na niej). Powstał więc pomysł, aby dla czytelników (a więc na razie bez możliwości edycji stron) stworzyć apkę na Androida i iOS, która będzie przypominać tę z Wikipedii. Najważniejsze to to, by umożliwiała ona zaznaczenie w preferencjach tych języków, które chce się przeszukiwać. W efekcie w apce na liście tłumaczeń byłyby tylko te języki, które wybrał użytkownik, a nie cała długa lista, jak to niekiedy jest w haśle. Oczywiście koszt stworzenia takiej apki jest bardzo wysoki. Środki na to mogłyby pochodzić bezpośrednio od Stowarzyszenia lub mogłyby być pozyskane z grantu celowego APG, ale wtedy moglibyśmy zacząć dopiero pracę nad tym projektem w 2020 roku (o ile Fundacja przyznałaby finansowanie).
- @PiotrekD poruszył temat bałaganu w kursywach w etymologii (i – co chyba istotniejsze, a na pewno spotkało się z większym zainteresowaniem – w znaczeniach, ~PiotrekDDYSKUSJA) - ale tutaj lepiej, aby on sam się wypowiedział, ponieważ temat dotyczy głównie haseł polskich.
- Ostatnie 20 minut czasu wykorzystałem na poruszenie kwestii wersji przejrzanych w Wikisłowniku - czy to w ogóle jest potrzebne, czy nie odstraszamy nowicjuszy, skoro niektóre zmiany czekają na oznaczenie rok. Ale do tej kwestii jeszcze powrócę w przyszłości w Barze.
- Borys Kozielski uczył nas nagrywać wymowę za pomocą smarfona i aplikacji Auphonic. Apka jest rzeczywiście bardzo prosta i umożliwia po założeniu konta zapisywać pliki w formacie ogg. Wersja darmowa umożliwia 2 godziny nagrania miesięcznie. Sam się jeszcze chętnie tym pobawię i pewnie ponagrywam brakujące wyrazy :).
To chyba tyle. Uważam, że Źródłosłów w tym roku był o wiele bardziej merytoryczny dla Wikisłownika, niż ten ubiegłoroczny i naprawdę szkoda, że reprezentacja naszego projektu była tak niewielka. Liczę, że zlot odbędzie się ponownie za rok i wtedy frekwencja będzie większa :). Nostrix (dyskusja) 08:57, 29 paź 2018 (CET)
- Dzięki @Nostrix za sprawozdanie. Jeśli chodzi o nagrywanie przykładów to chciałbym nieśmiało zauważyć, że jesteśmy liderem w Wikidanych jeśli chodzi o liczbę przykładów. Fajnie by było gdyby przykłady z Wikidanych od zarania były nagrywane, wszystkie są z NKJP. Pełną listę polskich przykładów z Wikidanych można przejrzeć uruchamiając to zapytanie KaMan (dyskusja) 11:51, 29 paź 2018 (CET)
- Szablon {{audio-A}}, teoretycznie przenaczony dla aneksów, jest już wykorzystywany w ok. 20 przykładach w przestrzeni głównej: linkujące. W kwestii wersji mobilnej przypomnę, że mamy możliwość dostosowania jej do naszych potrzeb, tworząc odpowiednie gadżety i nadając właściwe style (MediaWiki:Mobile.js, MediaWiki:Mobile.css oraz gadżety z MediaWiki:Gadgets-definition z oznaczeniem targets=mobile) – w przeciwieństwie do apki dla Androida lub innego systemu. Do tej pory m.in. umożliwiono ukrywanie pustych sekcji, zwijanie tabelek oraz dostosowano wygląd tak, by przypominał wersję standardową. Mogę napisać nowy gadżet, który filtrowałby tłumaczenia wg preferencji użytkownika. Pozdrawiam, Peter Bowman (dyskusja) 13:09, 29 paź 2018 (CET)
- Co do wersji przejrzanych: mamy szczęście, że w ogóle uruchomiono je u nas, bodajże dzięki zbiegnięciu się w czasie z aktywacją tego rozszerzenia w Wikipedii. Projekty ubiegające się o to mogą czekać miesiącami na ukończenie odpowiednich testów. Peter Bowman (dyskusja) 13:55, 29 paź 2018 (CET)
- Ad wersje przejrzane: założę wątek na ten temat w innym miejscu w przyszłości i wyjaśnię dokładnie o co mi chodzi :).
- Ad wersja mobilna: należy zrobić obie rzeczy, tj. dopracować wersję mobilną strony i stworzyć (w dalszej przyszłości) aplikację. Jedno drugiemu nie przeszkadza. To drugie rozwiązanie, choć kosztowne, ma ogromne zalety, których nie ma wersja przeglądarkowa. Problemy, przed którymi stoimy, to znalezienie źródła finansowania oraz uzyskanie zgody Fundacji na użycie znaku towarowego Wikisłownik w aplikacji. Cały content i tak jest na wolnej licencji, zatem teoretycznie każdy, amatorsko czy profesjonalnie, może sobie taką apkę napisać.
- Ad nagrania wymowy w przykładach: czy w świetle tego, co napisał Peter Bowman dodawanie nagrań przykładów jest niekontrowersyjne i nie wymaga szerokiego konsensusu społeczności?
- Chciałem się jeszcze na koniec odnieść do punktu @Marek Mazurkiewicz włączenie gadżetu domyślnie dla edytowania przez formularz - tutaj niestety nie było mnie na sali, więc mam prośbę o rozwinięcie tego. Czy chodzi o gadżet Wikisłownik:Projekt formularza? Nostrix (dyskusja) 20:23, 29 paź 2018 (CET)
- Co do wersji przejrzanych: mamy szczęście, że w ogóle uruchomiono je u nas, bodajże dzięki zbiegnięciu się w czasie z aktywacją tego rozszerzenia w Wikipedii. Projekty ubiegające się o to mogą czekać miesiącami na ukończenie odpowiednich testów. Peter Bowman (dyskusja) 13:55, 29 paź 2018 (CET)
The Community Wishlist Survey
Badanie Życzeń Społeczności.
Witajcie,
Badanie Życzeń Społeczności to proces podczas którego społeczności Wikimedia decydują nad czym zespół Community Tech z Wikimedia Foundation ma pracować w przyszłym roku.
Zespół Community Tech skupia się na narzędziach dla doświadczonych redaktorów w projektach Wikimedia. Od teraz do 11 listopada możesz wysłać propozycje potrzebnych rozwiązań technicznych. Następnie społeczność będzie mogła głosować na te propozycje od 16 listopada do 30 listopada. Więcej informacji na stronie tej ankiety.
/User:Johan (WMF)12:06, 30 paź 2018 (CET)
Change coming to how certain templates will appear on the mobile web
Nadchodzi zmiana wpływająca na wyświetlanie niektórych szablonów w wersji mobilnej
Pomóż przetłumaczyć na Twój język

Witajcie,
W najbliższych tygodniach zespół Readers web zmieni sposób wyświetlania niektórych szablonów na wersji mobilnej. Zrobimy tak, że te szablony będą bardziej przykuwać uwagę podczas czytania artykułów. Prosimy o pomoc w aktualizacji tych szablonów, które nie wyglądają prawidłowo.
O jakie szablony chodzi? Konkretnie o szablony informujące czytelników i redaktorów o problemach w treści artykułów – o treści i informacjach w artykule. Przykłądy to Szablon:Źródła lub więcej przypisów lub Szablon:Dopracować. Do tej pory te powiadomienia były ukryte pod linkiem pod tytułem artykułu. Będziemy formatować takie szablony (w większości wykorzystujące Szablon:Ambox czy w ogóle szablony do tworzenia komunikatów) tak, aby pokazywały krótką informację pod tytułem strony. Można będzie kliknąć link "Dowiedz się więcej", aby dowiedzieć się więcej o danym rodzaju problemów.
Dla osób opiekujących się szablonami mamy zalecenia jak tworzyć szablony tak, aby były przyjazne dla użytkowników urządzeń mobilnych oraz dokumentację naszej pracy.
Jeżeli macie jakieś pytania na temat formatowania szablonów dla wersji mobilnych, można je zadać na stronie dyskusji tego projektu lub napisać zgłoszenie w Phabricatorze, pomożemy.
Dziękujemy!
CKoerner (WMF) (talk) 20:35, 13 lis 2018 (CET)
Community Wishlist Survey vote
Badanie Życzeń Społeczności.
Witajcie,
Badanie Życzeń Społeczności to proces podczas którego społeczności Wikimedia decydują nad czym zespół Community Tech z Wikimedia Foundation ma pracować w przyszłym roku.
Zespół Community Tech skupia się na narzędziach dla doświadczonych redaktorów w projektach Wikimedia. Członkowie społeczności zamieścili już pełno propozycji o sprawach technicznych. Od teraz do 30 listopada możesz głosować na propozycje. Więcej informacji na stronie tej ankiety.
/User:Johan (WMF)19:13, 22 lis 2018 (CET)
Nazwy partii politycznych
Witam. Mam dwa pytania dotyczące zasad w tym projekcie.
- Czy obowiązują w tym projekcie jakieś ustalone zasady mówiące o tym, które nazwy partii politycznych nadają się do utworzenia hasła? Z tego co się zorientowałem, to jest już Prawo i Sprawiedliwość, PZPR, Platforma Obywatelska, SDPRR, League of Polish Families, Polish Worker's Party, Civic Platform, Law and Justice, Medborgarplattformen, Lag och rättvisa. Dziś usunięto mi Partia Zielonych, choć to dość problematyczny związek wyrazowy ze względu na kłopotliwą odmianę.
- Czy nie obowiązuje tutaj ogólna zasada Wikipedii, żeby dyskutować i wypracowywać konsensus przed usunięciem czyjejś pracy? Czy komunikujecie się tutaj dopiero po fakcie usunięcia hasła?
Grzegorz Wysocki (dyskusja) 00:57, 27 lis 2018 (CET)
- Nie chciałbym zabrzmieć ironicznie – zasady czytamy przecież przed podjęciem określonego zadania, zarówno tutaj (Wikisłownik), jak i w innym dowolnym kontekście. Większość wspomnianych haseł narusza obecne zasady nazewnictwa (WS:NAZ#nazwy własne), jednak zauważ, że powstały, zanim te zostały sformułowane (2011). Skrótowce natomiast – nie: „wszystkie skrótowce są dopuszczalne, niezależnie od tego, czy ich rozwinięcia spełniają kryteria słownikowości dla nazw własnych”. Gwoli ścisłości Twojej pracy nie usunąłem, lecz przeniosłem do Twojego brudnopisu, aby można było mieć wgląd w jego treść w trakcie ewentualnej dyskusji. Powiadomienie o wątpliwościach zostało nadane kilkadziesiąt godzin wcześniej na WS:ZB, reakcji brak. Pozdrawiam, Peter Bowman (dyskusja) 01:52, 27 lis 2018 (CET)
- Rozumiem, że hasła Prawo i Sprawiedliwość, Platforma Obywatelska, League of Polish Families, Polish Worker's Party, Civic Platform, Law and Justice, Medborgarplattformen, Lag och rättvisa zostaną usunięte? Grzegorz Wysocki (dyskusja) 22:24, 27 lis 2018 (CET)
- @Grzegorz Wysocki Sam wzdragałbym się przed usunięciem tych haseł, w szczególności stronnictwa obecnie rządzącego i tego, które rządziło poprzednio. Jeśli jednak będzie taka wola to ewentualne usunięcie poprzedzi głosowanie. Istnieje jednak i inny zarzut. Odmiana. Intuicja podpowiada mi, że mamy Partia (odmienne) + Zieloni (nieodmienne). Natomiast jak jest w rzeczywistości? Guglujemy stronę stronnictwa i mamy: „Partia Zieloni - Oficjalna strona Partii Zieloni. Dołącz do nas!”. Szukamy dalej. Mamy oficjalny (?) dokument - statut partii: Statut Partii Zieloni.
- 1. Partia nosi nazwę PARTIA ZIELONI. Dopuszcza się używanie skrótu nazwy: Zieloni. (Hm. Dlaczego wielkimi literami?)
- § 4 Członkostwo Partii Zieloni może uzyskać każda pełnoletnia osoba posiadająca obywatelstwo Rzeczpospolitej Polskiej, posiadająca pełną zdolność do czynności prawnych, korzystająca w pełni z praw obywatelskich, przyjęta do Partii zgodnie z przepisami niniejszego statutu.
- Członkinie/członkowie Partii Zieloni nie mogą jednocześnie należeć do innej partii politycznej.
- Formy odmienne (Zielonych) pojawiają się przy okazji uznanego skrótu, czyli Zieloni oraz przy nazwie Europejskiej Partii Zielonych.
- Okcydent (dyskusja) 23:18, 27 lis 2018 (CET)
- @Grzegorz Wysocki Sam wzdragałbym się przed usunięciem tych haseł, w szczególności stronnictwa obecnie rządzącego i tego, które rządziło poprzednio. Jeśli jednak będzie taka wola to ewentualne usunięcie poprzedzi głosowanie. Istnieje jednak i inny zarzut. Odmiana. Intuicja podpowiada mi, że mamy Partia (odmienne) + Zieloni (nieodmienne). Natomiast jak jest w rzeczywistości? Guglujemy stronę stronnictwa i mamy: „Partia Zieloni - Oficjalna strona Partii Zieloni. Dołącz do nas!”. Szukamy dalej. Mamy oficjalny (?) dokument - statut partii: Statut Partii Zieloni.
- Rozumiem, że hasła Prawo i Sprawiedliwość, Platforma Obywatelska, League of Polish Families, Polish Worker's Party, Civic Platform, Law and Justice, Medborgarplattformen, Lag och rättvisa zostaną usunięte? Grzegorz Wysocki (dyskusja) 22:24, 27 lis 2018 (CET)
New Wikimedia password policy and requirements
Nowa polityka haseł Wikimedia i wymagania
Wikimedia Foundation wdraża nową politykę i wymagania dotyczące haseł. Więcej o tym projekcie przeczytasz na MediaWiki.org.
Nowe wymogi mają zastosowanie do nowo zakładanych kont i kont z zaawansowanymi uprawnieniami. Dla nowych kont wymagane będą hasła o minimalnej długości 8 znaków. Dla kont z uprawnieniami zaawansowanymi będzie wyświetlana prośba o zmianę hasła na takie, które będzie miało minimum 10 znaków.
Zmiana zostanie wcielona w życie 13 grudnia. Jeżeli sądzisz, że ta zmiana ma wpływ na twoje działania lub narzędzia, powiadom nas na stronie dyskusji.
Dziękujemy!