Snowflake to BigQuery migration
This document provides a technical background on how to migrate data from Snowflake to BigQuery. It covers the foundational differences between Snowflake and BigQuery. It also provides guidance for a successful migration, such as the following:
- What schema changes are needed
- What migration tools and options are available
- How to migrate data (using a sample export process)
You can also use batch SQL translation to migrate your SQL scripts in bulk, or interactive SQL translation to translate ad hoc queries. Snowflake SQL is supported by both tools in preview.
Terminology
This document uses Snowflake and BigQuery terminology to describe the capabilities that each product provides. The following table maps Snowflake terms to equivalent BigQuery terms:
| Snowflake | BigQuery |
|---|---|
| Database | Dataset |
| Schema | Schema |
| Session-specific temporary or transient table | Anonymous or temporary table |
| View | View |
| Secure views | Authorized Views |
| Virtual warehouse | Reservation |
| Materialized view | Materialized view |
| No equivalent for partitioning (because micro-partitioning is used) | Partitioning |
| Clustering | Clustering |
| Security-enhanced user-defined functions (UDFs) | Authorized UDFs |
Architectural comparison
Snowflake and BigQuery are both analytic data warehouses, but they have some key architectural differences.
The architecture in Snowflake a hybrid of shared-disk database architectures and shared-nothing database architectures. As with shared-nothing architectures, data in Snowflake is managed in a separated cloud object storage service. As with a shared-disk architecture, queries in Snowflake use dedicated compute clusters. In Snowflake, each cluster manages cached portions of the entire dataset to accelerate query performance. For more information, see Snowflake architecture.
BigQuery's architecture is vastly different from node-based cloud data warehouse solutions or MPP systems. It decouples storage and compute, which allows them to scale independently on demand. For more information, see BigQuery under the hood.
User interface comparison
The Snowflake web interface mirrors the Snowflake command line interface (CLI). Both interfaces let you do the following:
- Manage databases
- Manage warehouses
- Manage queries and worksheets
- View historical queries
The web interface also lets you manage your Snowflake password and user preferences.
The Snowflake CLI client uses SnowSQL for connecting to Snowflake to run SQL queries and other operations.
The BigQuery interface is built into the Google Cloud console and contains a list of BigQuery resources that you can view:
- The BigQuery Studio section displays your datasets, tables, views, and other BigQuery resources. This is where you can create and run queries, work with tables and views, see your BigQuery job history, and perform other common BigQuery tasks.
- The Data transfers section opens the BigQuery Data Transfer Service page.
- The Scheduled queries section displays your scheduled queries.
- The Capacity management section displays slot commitments, reservations, and reservation assignments.
- The BI Engine section opens the BigQuery BI Engine page.
BigQuery also has a command-line tool which is Python-based. For more information, see, using the bq command-line tool.
Security
When migrating from Snowflake to BigQuery, you must consider the way that Google Cloud in general, and BigQuery in particular, handles security differently from Snowflake.
Snowflake has various security-related features like the following:
- Network and site access
- Account and user authentication
- Object security
- Data security
- Security validations
Security on Snowflake is based on your cloud provider's features. It provides granular control over access to objects, object operations, and who can create or alter access control policies.
The BigQuery parallel to the access control privileges in Snowflake are Identity and Access Management (IAM) roles in Google Cloud. These privileges determine the operations that are allowed on a resource. Privileges are enforced at a Google Cloud level.
Encryption
In Snowflake, column-level security is supported in the Enterprise edition, and customer-managed encryption keys are supported in the Business Critical edition. These editions have different pricing. In BigQuery, all features and enhanced security measures are offered as standard features at no additional cost.
Snowflake provides end-to-end encryption in which it automatically encrypts all stored data. Google Cloud provides the same feature by encrypting all data at rest and in transit by default.
Similar to Snowflake Business Critical edition, BigQuery supports customer-managed encryption keys for users who want to control and manage key encryption keys in Cloud Key Management Service. BigQuery also allows column-level encryption. For more information about encryption in Google Cloud, see Encryption at rest in Google Cloud and Encryption in transit in Google Cloud.
Roles
Roles are the entities to which privileges on securable objects can be granted and revoked.
Snowflake supports the following two types of roles:
- System-defined roles: These roles consist of system and security-related privileges and are created with privileges related to account management.
- Custom roles:
You can create these roles by using the
SECURITYADMINroles or by using any role that has theCREATE ROLEprivilege. Each custom role in Snowflake is composed of privileges.
In IAM, permissions are grouped into roles. IAM provides three types of roles:
- Basic roles:
These roles include the Owner, Editor, and Viewer roles. You can apply
these roles at the project or service resource levels by using the
Google Cloud console, the Identity and Access Management API, or the
gcloud CLI. In general, for the strongest security, we recommend that you use BigQuery-specific roles to follow the principle of least privilege. - Predefined roles: These roles provide more granular access to features in a product (such as BigQuery) and are meant to support common use cases and access control patterns.
- Custom roles: These roles are composed of user-specified permissions.
Access control
Snowflake lets you grant roles to other roles, creating a hierarchy of roles. IAM doesn't support a role hierarchy but implements a resource hierarchy. The IAM hierarchy includes the organization level, folder level, project level, and resource level. You can set IAM roles at any level of the hierarchy, and resources inherit all the policies of their parent resources.
Both Snowflake and BigQuery support table-level access control. Table-level permissions determine the users, groups, and service accounts that can access a table or view. You can give a user access to specific tables or views without giving the user access to the complete dataset.
Snowflake also uses row-level security and column-level security.
In BigQuery, IAM provides table-level access control. For more granular access, you can also use column-level access control or row-level security. This type of control provides fine-grained access to sensitive columns by using policy tags or type-based data classifications.
You can also create authorized views to limit data access for more fine-grained access control so that specified users can query a view without having read access to the underlying tables.
Things to consider when migrating
There are a few Snowflake features that you cannot port directly to BigQuery. For example, BigQuery doesn't offer built-in support for the following scenarios. In these scenarios, you might need to use other services in Google Cloud.
Time travel: In BigQuery, you can use time travel to access data from any point within the last seven days. If you need to access data beyond seven days, consider exporting regularly scheduled snapshots. Snowflake lets you access historical data (data that has been changed or deleted) at any point within a defined period. You can set this period at any value from 0 to 90 days.
Streams: BigQuery supports change data capture (CDC) with Datastream. You can also use CDC software, like Debezium, to write records to BigQuery with Dataflow. For more information on manually designing a CDC pipeline with BigQuery, see Migrating data warehouses to BigQuery: Change data capture (CDC). In Snowflake, a stream object records data manipulation language changes made to tables and also metadata about each change so that you can take actions with the changed data.
Tasks: BigQuery lets you schedule queries and streams or stream integration into queries with Datastream. Snowflake can combine tasks with table streams for continuous extract, load, and transfer workflows in order to process recently changed table rows.
External functions: BigQuery supports external function calls through Cloud Run functions. However, you can also use user-defined functions (UDF) like SQL UDF, although these functions aren't executed outside of BigQuery. In Snowflake, an external function calls code that runs outside Snowflake. For example, information sent to a remote service is usually relayed through a proxy service.
Migrate data from Snowflake to BigQuery
This section describes how to configure and initiate your migration from Snowflake to BigQuery based on the framework outlined in Migrating data warehouses to BigQuery: What and how to migrate.
Architecture
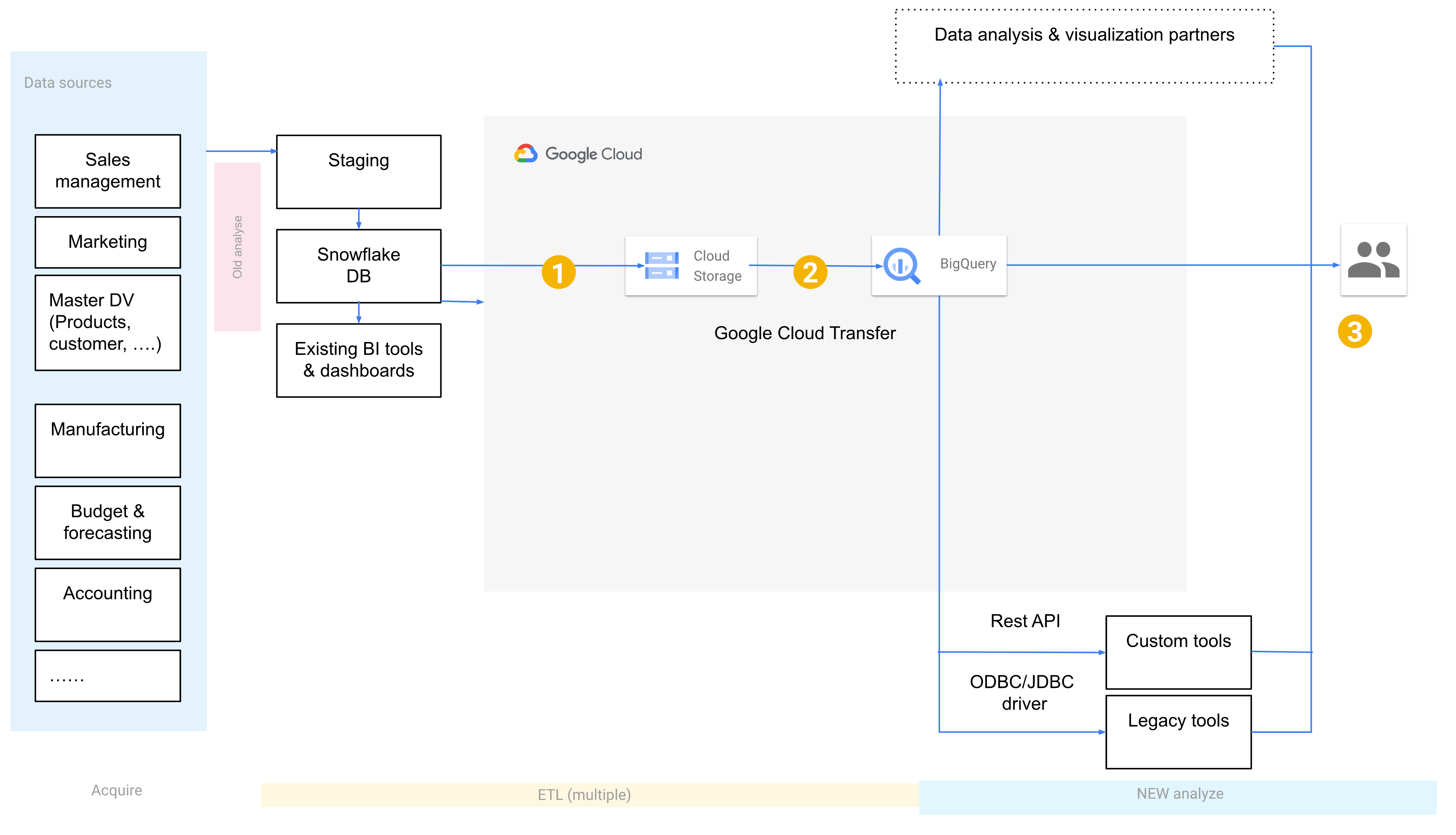
To start the migration, you run both Snowflake and BigQuery. The following diagram shows an architecture that minimally affects existing operations. By transferring clean, quality-controlled data, you can reuse existing tools and processes while offloading workloads to BigQuery. You can also validate reports and dashboards against earlier versions. Nevertheless, because OLAP data is maintained in redundant places, this operation isn't cost effective. It also extends the processing time.
- Point 1 shows data moving from Snowflake to Cloud Storage.
- Point 2 shows the persistence of the data to BigQuery.
- Point 3 shows how the data is sent to the end user.
You can validate reports and dashboards against old iterations. For more information, see Migrating data warehouses to BigQuery: Verify and validate.
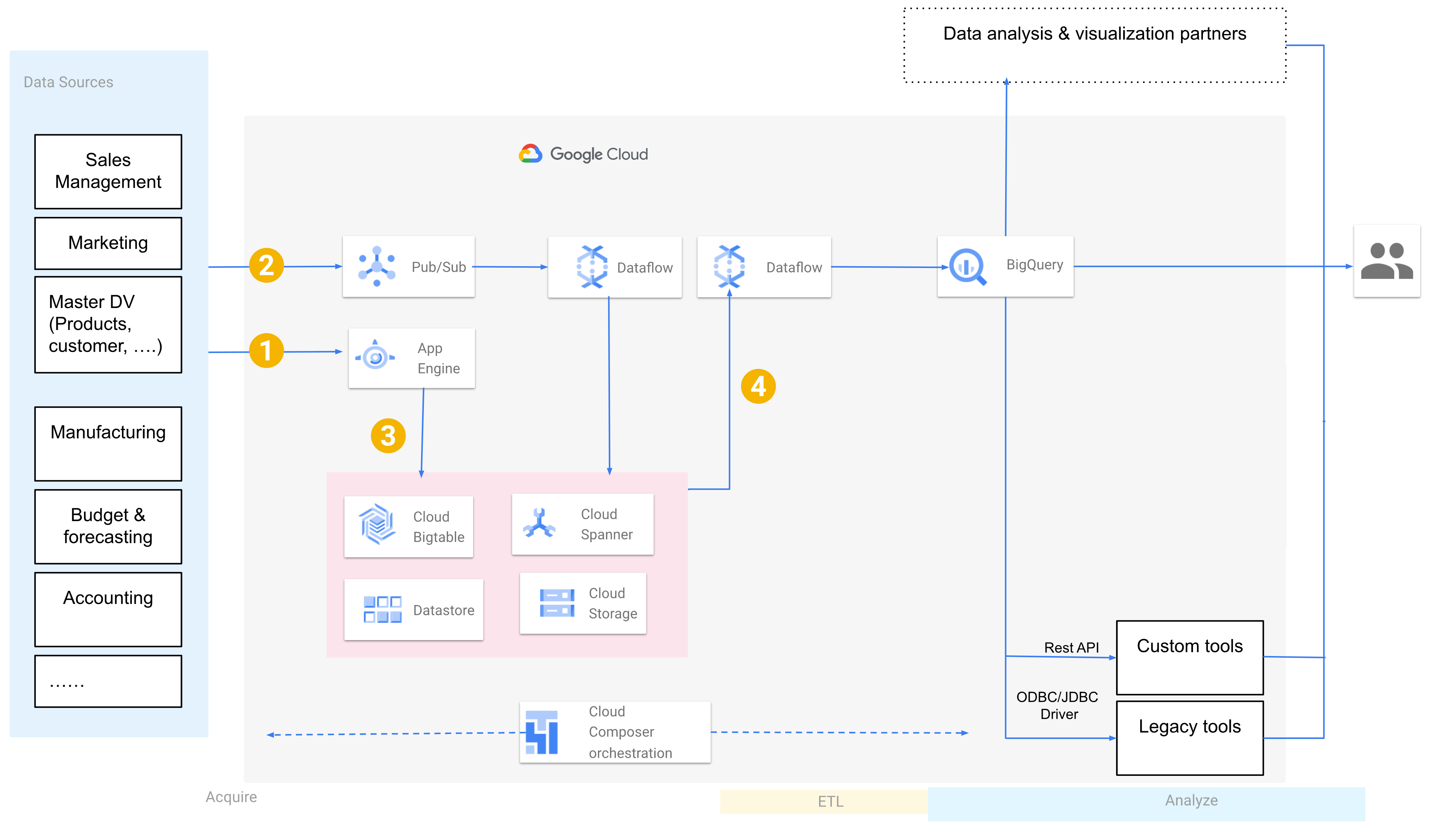
The final architecture for your data warehouse migration has all the data from source systems directly persisted in Google Cloud. Depending on the number and complexity of the source systems, delivering this architecture can be further staged by addressing source systems one at a time according to priority, interdependencies, integration risks, or other business factors.
The following diagram assumes the migration of data pipelines and ingestion to Google Cloud.
- Point 1 shows both synchronous and asynchronous integration points. Synchronous integration is, for example, between data sources and App Engine when dealing with use cases that require explicit user actions as a part of the flow.
- Point 2 shows using Pub/Sub for large volumes of concurrent event data.
- Point 3 shows the persistence of data using one or more Google Cloud products, depending on the nature of the data.
- Point 4 shows the extract, transform, and load (ETL) process to BigQuery.
Prepare your Cloud Storage environment
Google Cloud offers several ways to transfer your data to BigQuery using other ETL tools. The pattern is as follows:
Extract the data from your source: Copy the extracted files from your source into staging storage in your on-premises environment. For more information, see Migrating data warehouses to BigQuery: Extracting the source data.
Transfer data to a staging Cloud Storage bucket: After you finish extracting data from your source, you transfer it to a temporary bucket in Cloud Storage. Depending on the amount of data you're transferring and the network bandwidth available, you have several options.
It's important to ensure that the location of your BigQuery dataset and your external data source, or your Cloud Storage bucket, are in the same region. For more information on geographical location considerations for loading data from Cloud Storage, see Batch loading data.
Load data from the Cloud Storage bucket into BigQuery: Your data is now in a Cloud Storage bucket, closer to its destination. There are several options to upload the data into BigQuery. Those options depend on how much the data has to transform. Alternatively, you can transform your data within BigQuery by following the ETL approach.
When you import your data in bulk from a JSON file, an Avro file, or a CSV file, BigQuery auto-detects the schema, so you don't need to predefine it. To get a detailed overview of the schema migration process for EDW workloads, see Schema and data migration process.
Supported data types, properties, and file formats
Snowflake and BigQuery support most of the same data types, though they sometimes use different names. For a complete list of supported data types in Snowflake and BigQuery, see the Data types section of the Snowflake SQL translation reference. You can also use the batch SQL translator to translate For more information about BigQuery's supported data types, see GoogleSQL data types.
Snowflake can export data in the following file formats. You can load the formats directly into BigQuery:
- CSV: See Loading CSV data from Cloud Storage.
- Parquet: See Loading Parquet data from Cloud Storage.
- JSON (newline-delimited): See Loading JSON data from Cloud Storage.
Schema changes
If you are planning schema changes in your migration to BigQuery, we recommend that you first migrate your schema as-is. BigQuery supports a wide range of data model design patterns, such as star schema or Snowflake schema. Because of this support, you don't need to update your upstream data pipelines for a new schema, and you can use automated migration tools to transfer your data and schema.
Updating a schema
After your data is in BigQuery, you can always make updates to
the schema, such as adding columns to the schema definition or relaxing a
column's mode from REQUIRED to NULLABLE.
Remember that BigQuery uses case-sensitive naming conventions for the table name, whereas Snowflake uses case-insensitive naming patterns. This convention means that you might need to revisit any inconsistencies in the table-naming conventions that might exist in Snowflake, and rectify any inconsistencies that arose during the move to BigQuery. For more information on schema modification, see Modifying table schemas.
Some schema modifications aren't directly supported in BigQuery and require manual workarounds, including the following:
- Changing a column's name.
- Changing a column's data type.
- Changing a column's mode (except for relaxing
REQUIREDcolumns toNULLABLE).
For specific instructions on how to manually implement these schema changes, see Manually change table schemas.
Optimization
After the schema migration, you can test performance and make optimizations based on the results. For example, you can introduce partitioning to make your data more efficient to manage and query. Partitioning in BigQuery refers to a special table that is divided into segments called partitions. Partitioning is different from the micro-partitioning in Snowflake, which happens automatically as data is loaded. BigQuery's partitioning lets you improve query performance and cost control by partitioning by ingestion time, timestamp, or integer range. For more information, see Introduction to partitioned tables.
Clustered tables
Clustered tables are another schema optimization. BigQuery, like Snowflake, lets you cluster tables, enabling you to automatically organize table data based on the contents of one or more columns in the table's schema. BigQuery uses the columns that you specify to colocate related data. Clustering can improve the performance of certain types of queries, such as queries that use filter clauses or queries that aggregate data. For more information on how clustered tables work in BigQuery, see Introduction to clustered tables.
Migration tools
The following list describes the tools that you can use to migrate data from Snowflake to BigQuery. These tools are combined in the Examples of migration using pipelines section to put together end-to-end migration pipelines.
COPY INTO <location>command: Use this command in Snowflake to unload data from a Snowflake table directly into a specified Cloud Storage bucket. For an end-to-end example, see Snowflake to BigQuery (snowflake2bq) on GitHub.- Apache Sqoop: To extract data from Snowflake into either HDFS or Cloud Storage, submit Hadoop jobs with the JDBC driver from Sqoop and Snowflake. Sqoop runs in a Dataproc environment.
- Snowflake JDBC: Use this driver with most client tools or applications that support JDBC.
You can use the following generic tools to migrate data from Snowflake to BigQuery:
- BigQuery Data Transfer Service: Perform an automated batch transfer of Cloud Storage data into BigQuery with this fully managed service. This tool requires you to first export the Snowflake data to Cloud Storage.
- The Google Cloud CLI: Copy downloaded Snowflake files into Cloud Storage with this command-line tool.
- bq command-line tool: Interact with BigQuery using this command-line tool. Common use cases include creating BigQuery table schemas, loading Cloud Storage data into tables, and running queries.
- Cloud Storage client libraries: Copy downloaded Snowflake files into Cloud Storage with a custom tool that uses the Cloud Storage client libraries.
- BigQuery client libraries: Interact with BigQuery with a custom tool built on top of the BigQuery client library.
- BigQuery query scheduler: Schedule recurring SQL queries with this built-in BigQuery feature.
- Cloud Composer: Use this fully managed Apache Airflow environment to orchestrate BigQuery load jobs and transformations.
For more information on loading data into BigQuery, see Loading data into BigQuery.
Examples of migration using pipelines
The following sections show examples of how to migrate your data from Snowflake to BigQuery using three different techniques: extract and load, ETL, and partner tools.
Extract and load
The extract and load technique offers two methods:
- Use a pipeline to unload data from Snowflake
- Use a pipeline and a JDBC driver to export data from Snowflake
Use a pipeline to unload data from Snowflake
To
unload data from Snowflake
directly into Cloud Storage (recommended), or to
download data
and copy it to Cloud Storage using the gcloud CLI or the
Cloud Storage client libraries, use the snowflake2bq tool to migrate
data using the Snowflake COPY INTO <location> command.
You then load Cloud Storage data into BigQuery with one of the following tools:
- BigQuery Data Transfer Service
bqcommand-line tool- BigQuery API Client Libraries
Use a pipeline and a JDBC driver to export data from Snowflake
Use any of the following products to export Snowflake data with the JDBC driver from Snowflake:
- Dataflow
- Cloud Data Fusion
- Dataproc
- BigQuery with Apache Spark
- Snowflake Connector for Spark
- BigQuery Connector for Spark and Hadoop
- The JDBC driver from Snowflake and Sqoop to extract data from Snowflake into Cloud Storage:
Extract, transform, and load
If you want to transform your data before loading it into BigQuery, you can add a transformation step in the pipelines described in the preceding Extract and load section.
Transform Snowflake data
To transform your data before loading it into BigQuery, either unload data directly from Snowflake to Cloud Storage or use the gcloud CLI to copy data over, as described in the preceding Extract and load section.
Load Snowflake data
After transforming your data, load your data into BigQuery with one of the following methods:
- Dataproc
- Read from Cloud Storage with Apache Spark
- Write to BigQuery with Apache Spark
- Hadoop Cloud Storage Connector
- Hadoop BigQuery Connector
- Dataflow
- Read from Cloud Storage
- Write to BigQuery
- Google-provided template: Cloud Storage Text to BigQuery
- Cloud Data Fusion
- Dataprep by Trifacta
Use a pipeline and a JDBC driver to transform and export data from Snowflake
Add a transformation step in the following pipeline options as described in the preceding Extract and load section.
- Dataflow
- Clone the Google-provided JDBC-to-BigQuery template code and modify the template to add Apache Beam transforms.
- Cloud Data Fusion
- Transform your data using the CDAP plugins.
- Dataproc
- Transform your data using Spark SQL or custom code in any of the supported Spark languages (Scala, Java, Python, or R).
You might have an extract, load, and transform use case to load your data from Snowflake into BigQuery and then transform it. To perform this task, load your data from Snowflake to a BigQuery staging table by using one of the methods in the preceding Extract and load section. Then, run SQL queries on the staging table and write the output to the final production table in BigQuery.
Partner tools for migration
There are multiple vendors that specialize in the EDW migration space. For a list of key partners and their provided solutions, see Google Cloud's BigQuery partner website.
Examples of the export process
The following sections show a sample data export from Snowflake to
BigQuery that uses the COPY INTO <location> Snowflake command.
For a detailed, step-by step process that includes code samples, see
the
Google Cloud professional services Snowflake to BigQuery tool.
Prepare for the export
For the unload, use Snowflake SQL statements to create a named file format specification.
This tutorial uses my_parquet_unload_format for the file format, but you can
use a different name.
create or replace file format my_parquet_unload_format
type = 'PARQUET'
field_delimiter = '|'
Export your Snowflake data
After you prepare your data, you need to move the data to Google Cloud. You can do this step in one of the two following ways:
- Exporting your data directly to Cloud Storage from Snowflake.
- Staging your Snowflake data in either an Amazon Simple Storage Service (Amazon S3) bucket or Azure Blob Storage.
To avoid an extra data hop, directly export your data.
Export Snowflake data directly to Cloud Storage
The following instructions show how to use the Snowflake COPY command to
unload data from Snowflake to Cloud Storage:
In Snowflake, configure a storage integration object to let Snowflake write to a Cloud Storage bucket referenced in an external Cloud Storage stage.
This step involves several substeps.
Create an integration with the
CREATE STORAGE INTEGRATIONcommand:create storage integration gcs_int type = external_stage storage_provider = gcs enabled = true storage_allowed_locations = ('gcs://mybucket/unload/')Retrieve the Cloud Storage service account for Snowflake with the
DESCRIBE INTEGRATIONcommand and grant the service account permissions to access the Cloud Storage bucket that is selected as the staging area:desc storage integration gcs_int;+-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+ | property | property_type | property_value | property_default | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | gcs://mybucket1/path1/,gcs://mybucket2/path2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | gcs://mybucket1/path1/sensitivedata/,gcs://mybucket2/path2/sensitivedata/ | [] | | STORAGE_GCP_SERVICE_ACCOUNT | String | [email protected] | | +-----------------------------+---------------+--------------------------------------------------------- --------------------+------------------+
Create an external Cloud Storage stage referencing the integration that you created with the
CREATE STAGEcommand:create or replace stage my_ext_unload_stage url='gcs://mybucket/unload' storage_integration = gcs_int file_format = my_parquet_unload_format;
Use the
COPY INTO <location>command to copy data from the Snowflake database table into a Cloud Storage bucket by specifying the external stage object you created in the previous step:copy into @my_ext_unload_stage/d1 from mytable;
Export Snowflake data to Cloud Storage through Storage Transfer Service from Amazon S3
The following example shows how to
unload data from a Snowflake table to an Amazon S3 bucket
by using the COPY command:
In Snowflake, configure a storage integration object to allow Snowflake to write to an Amazon S3 bucket referenced in an external Cloud Storage stage.
This step involves configuring access permissions to the Amazon S3 bucket, creating the AWS IAM role, and creating a storage integration in Snowflake with the
CREATE STORAGE INTEGRATIONcommand:create storage integration s3_int type = external_stage storage_provider = s3 enabled = true storage_aws_role_arn = 'arn:aws:iam::001234567890:role/myrole' storage_allowed_locations = ('s3://unload/files/')Retrieve the AWS IAM user with the
DESCRIBE INTEGRATIONcommand:desc integration s3_int;+---------------------------+---------------+================================================================================+------------------+ | property | property_type | property_value | property_default | +---------------------------+---------------+================================================================================+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | s3://mybucket1/mypath1/,s3://mybucket2/mypath2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | s3://mybucket1/mypath1/sensitivedata/,s3://mybucket2/mypath2/sensitivedata/ | [] | | STORAGE_AWS_IAM_USER_ARN | String | arn:aws:iam::123456789001:user/abc1-b-self1234 | | | STORAGE_AWS_ROLE_ARN | String | arn:aws:iam::001234567890:role/myrole | | | STORAGE_AWS_EXTERNAL_ID | String | MYACCOUNT_SFCRole=
| | +---------------------------+---------------+================================================================================+------------------+ Grant the AWS IAM user permissions to access the Amazon S3 bucket, and create an external stage with the
CREATE STAGEcommand:create or replace stage my_ext_unload_stage url='s3://unload/files/' storage_integration = s3_int file_format = my_parquet_unload_format;Use the
COPY INTO <location>command to copy the data from the Snowflake database into the Amazon S3 bucket by specifying the external stage object that you created earlier:copy into @my_ext_unload_stage/d1 from mytable;Transfer the exported files into Cloud Storage by using Storage Transfer Service.
Export Snowflake data to Cloud Storage through other cloud providers:
Azure Blob Storage Follow the steps detailed in Unloading into Microsoft Azure. Then, transfer the exported files into Cloud Storage by using Storage Transfer Service.
Amazon S3 Bucket Follow the steps detailed in unloading into Amazon S3. Then, transfer the exported files into Cloud Storage by using Storage Transfer Service.
What's next
- Post migration performance and optimization.
- Explore reference architectures, diagrams, and best practices about Google Cloud. Take a look at our Cloud Architecture Center.