Migrating Teradata to BigQuery tutorial
This document describes how to migrate from Teradata to BigQuery using sample data. It provides a proof-of-concept that walks you through the process of transferring both schema and data from a Teradata data warehouse to BigQuery.
Objectives
- Generate synthetic data and upload it to Teradata.
- Migrate the schema and data to BigQuery, using the BigQuery Data Transfer Service (BQDT).
- Verify that queries return the same results on Teradata and BigQuery.
Costs
This quickstart uses the following billable components of Google Cloud:
- BigQuery: This tutorial stores close to 1 GB of data in BigQuery and processes under 2 GB when executing the queries once. As part of the Google Cloud Free Tier, BigQuery offers some resources free of charge up to a specific limit. These free usage limits are available during and after the free trial period. If you go over these usage limits and are no longer in the free trial period, you are charged according to the pricing on the BigQuery pricing page.
You can use the pricing calculator to generate a cost estimate based on your projected usage.
Prerequisites
- Make sure you have write and execute permissions in a machine that has access to the internet, so that you can download the data generation tool and run it.
- Make sure that you can connect to a Teradata database.
Make sure that the machine has the Teradata BTEQ and FastLoad client tools installed. You can get the Teradata client tools from the Teradata website. If you need help installing these tools, ask your system administrator for details on installing, configuring, and running them. As an alternative, or in addition to BTEQ, you might do the following:
- Install a tool with a graphical interface such as DBeaver.
- Install the Teradata SQL Driver for Python for scripting interactions with Teradata Database.
Make sure that the machine has network connectivity with Google Cloud for the BigQuery Data Transfer Service agent to communicate with BigQuery and transfer the schema and data.
Introduction
This quickstart guides you through a migration proof of concept. During the quickstart, you generate synthetic data and load it into Teradata. Then you use the BigQuery Data Transfer Service to move the schema and data to BigQuery. Finally, you run queries on both sides to compare results. The end state is that the schema and data from Teradata are mapped one-for-one into BigQuery.
This quickstart is intended for data warehouse administrators, developers, and data practitioners in general who are interested in a hands-on experience with a schema and data migration using the BigQuery Data Transfer Service.
Generating the data
The Transaction Processing Performance Council (TPC) is a non-profit organization that publishes benchmarking specifications. These specifications have become de facto industry standards for running data related benchmarks.
The TPC-H specification is a benchmark that's focused on decision support. In this quickstart, you use parts of this specification to create the tables and generate synthetic data as a model of a real-life data warehouse. Although the specification was created for benchmarking, in this quickstart you use this model as part of the migration proof of concept, not for benchmarking tasks.
- On the computer where you will connect to Teradata, use a web browser to download the latest available version of the TPC-H tools from the TPC website.
- Open a command terminal and change to the directory where you downloaded the tools.
Extract the downloaded zip file. Replace file-name with the name of the file you downloaded:
unzip file-name.zip
A directory whose name includes the tools version number is extracted. This directory includes the TPC source code for the DBGEN data generation tool and the TPC-H specification itself.
Go to the
dbgensubdirectory. Use the parent directory name corresponding to your version, as in the following example:cd 2.18.0_rc2/dbgenCreate a makefile using the provided template:
cp makefile.suite makefileEdit the makefile with a text editor. For example, use vi to edit the file:
vi makefileIn the makefile, change the values for the following variables:
CC = gcc # TDAT -> TERADATA DATABASE = TDAT MACHINE = LINUX WORKLOAD = TPCHDepending on your environment, the C compiler (
CC) orMACHINEvalues might be different. if needed, ask your system administrator.Save the changes and close the file.
Process the makefile:
makeGenerate the TPC-H data using the
dbgentool:dbgen -vThe data generation takes a couple of minutes. The
-v(verbose) flag causes the command to report on the progress. When data generation is done, you find 8 ASCII files with the.tblextension in the current folder. They contain pipe-delimited synthetic data to be loaded in each one of the TPC-H tables.
Uploading sample data to Teradata
In this section, you upload the generated data into your Teradata database.
Create the TPC-H database
The Teradata client, called Basic Teradata Query (BTEQ), is used to communicate with one or more Teradata database servers and to run SQL queries on those systems. In this section you use BTEQ to create a new database for the TPC-H tables.
Open the Teradata BTEQ client:
bteqLog in to Teradata. Replace the teradata-ip and teradata-user with the corresponding values for your environment.
.LOGON teradata-ip/teradata-user
Create a database named
tpchwith 2 GB of allocated space:CREATE DATABASE tpch AS PERM=2e+09;Exit BTEQ:
.QUIT
Load the generated data
In this section, you create a FastLoad script to create and load the sample tables. The table definitions are described in section 1.4 of the TPC-H specification. Section 1.2 contains an entity-relationship diagram of the whole database schema.
The following procedure shows how to create the lineitem table, which is the
largest and most complex of the TPC-H tables. When you finish with the
lineitem table, you repeat this procedure for the remaining tables.
Using a text editor, create a new file named
fastload_lineitem.fl:vi fastload_lineitem.flCopy the following script into the file, which connects to the Teradata database and creates a table named
lineitem.In the
logoncommand, replace teradata-ip, teradata-user, and teradata-pwd with your connection details.logon teradata-ip/teradata-user,teradata-pwd; drop table tpch.lineitem; drop table tpch.error_1; drop table tpch.error_2; CREATE multiset TABLE tpch.lineitem, NO FALLBACK, NO BEFORE JOURNAL, NO AFTER JOURNAL, CHECKSUM = DEFAULT, DEFAULT MERGEBLOCKRATIO ( L_ORDERKEY INTEGER NOT NULL, L_PARTKEY INTEGER NOT NULL, L_SUPPKEY INTEGER NOT NULL, L_LINENUMBER INTEGER NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_LINESTATUS CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_COMMITDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_RECEIPTDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_SHIPINSTRUCT CHAR(25) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPMODE CHAR(10) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_COMMENT VARCHAR(44) CHARACTER SET LATIN CASESPECIFIC NOT NULL) PRIMARY INDEX ( L_ORDERKEY ) PARTITION BY RANGE_N(L_COMMITDATE BETWEEN DATE '1992-01-01' AND DATE '1998-12-31' EACH INTERVAL '1' DAY);The script first makes sure that the
lineitemtable and temporary error tables do not exist, and proceeds to create thelineitemtable.In the same file, add the following code, which loads the data into the newly created table. Complete all of the table fields in the three blocks (
define,insertandvalues), making sure you usevarcharas their load data type.begin loading tpch.lineitem errorfiles tpch.error_1, tpch.error_2; set record vartext; define in_ORDERKEY(varchar(50)), in_PARTKEY(varchar(50)), in_SUPPKEY(varchar(50)), in_LINENUMBER(varchar(50)), in_QUANTITY(varchar(50)), in_EXTENDEDPRICE(varchar(50)), in_DISCOUNT(varchar(50)), in_TAX(varchar(50)), in_RETURNFLAG(varchar(50)), in_LINESTATUS(varchar(50)), in_SHIPDATE(varchar(50)), in_COMMITDATE(varchar(50)), in_RECEIPTDATE(varchar(50)), in_SHIPINSTRUCT(varchar(50)), in_SHIPMODE(varchar(50)), in_COMMENT(varchar(50)) file = lineitem.tbl; insert into tpch.lineitem ( L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER, L_QUANTITY, L_EXTENDEDPRICE, L_DISCOUNT, L_TAX, L_RETURNFLAG, L_LINESTATUS, L_SHIPDATE, L_COMMITDATE, L_RECEIPTDATE, L_SHIPINSTRUCT, L_SHIPMODE, L_COMMENT ) values ( :in_ORDERKEY, :in_PARTKEY, :in_SUPPKEY, :in_LINENUMBER, :in_QUANTITY, :in_EXTENDEDPRICE, :in_DISCOUNT, :in_TAX, :in_RETURNFLAG, :in_LINESTATUS, :in_SHIPDATE, :in_COMMITDATE, :in_RECEIPTDATE, :in_SHIPINSTRUCT, :in_SHIPMODE, :in_COMMENT ); end loading; logoff;
The FastLoad script loads the data from a file in the same directory called
lineitem.tbl, which you generated in the previous section.Save the changes and close the file.
Run the FastLoad script:
fastload < fastload_lineitem.flRepeat this procedure for the rest of the TPC-H tables listed in section 1.4 of the TPC-H specification. Make sure that you adjust the steps for each table.
Migrating the schema and data to BigQuery
The instructions for how to migrate the schema and data to BigQuery are in a separate tutorial: Migrate data from Teradata. We've included details in this section on how to proceed with certain steps of that tutorial. When you've finished the steps in the other tutorial, return to this document and continue with the next section, Verifying query results.
Create the BigQuery dataset
During the initial Google Cloud configuration steps, you're asked to
create a dataset in BigQuery to hold the tables after they're
migrated. Name the dataset tpch. The queries at the end of this quickstart
assume this name, and don't require any modifications.
# Use the bq utility to create the dataset
bq mk --location=US tpch
Create a service account
Also as part of the Google Cloud configuration steps, you must create an Identity and Access Management (IAM) service account. This service account is used to write the data into BigQuery and to store temporary data in Cloud Storage.
# Set the PROJECT variable
export PROJECT=$(gcloud config get-value project)
# Create a service account
gcloud iam service-accounts create tpch-transfer
Grant permissions to the service account that let it administer BigQuery datasets and the staging area in Cloud Storage:
# Set TPCH_SVC_ACCOUNT = service account email
export TPCH_SVC_ACCOUNT=tpch-transfer@${PROJECT}.iam.gserviceaccount.com
# Bind the service account to the BigQuery Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/bigquery.admin
# Bind the service account to the Storage Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/storage.admin
Create the staging Cloud Storage bucket
One additional task in the Google Cloud configuration is to create a Cloud Storage bucket. This bucket is used by the BigQuery Data Transfer Service as a staging area for data files to be ingested into BigQuery.
# Use gcloud storage to create the bucket
gcloud storage buckets create gs://${PROJECT}-tpch --location=us-central1
Specify the table name patterns
During the configuration of a new transfer in the BigQuery Data Transfer Service, you're
asked to specify an expression that indicates which tables to include in the
transfer. In this quickstart, you include all of the tables from the tpch
database.
The format of the expression is database.table, and the table name can be
replaced by a wildcard. Because wildcards in Java start with two dots, the
expression to transfer all of the tables from the tpch database is as
follows:
tpch..*
Notice that there are two dots.
Verifying query results
At this point you've created sample data, uploaded the data to Teradata, and then migrated it to BigQuery using the BigQuery Data Transfer Service, as explained in the separate tutorial. In this section, you run two of the TPC-H standard queries to verify that the results are the same in Teradata and in BigQuery.
Run the pricing summary report query
The first query is the pricing summary report query (section 2.4.1 of the TPC-H specification). This query reports the number of items that were billed, shipped, and returned as of a given date.
The following listing shows the complete query:
SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice*(1-l_discount)) AS sum_disc_price,
SUM(l_extendedprice*(1-l_discount)*(1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM tpch.lineitem
WHERE l_shipdate BETWEEN '1996-01-01' AND '1996-01-10'
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;
Run the query in Teradata:
- Run BTEQ and connect to Teradata. For details, see Create the TPC-H database earlier in this document.
Change the output display width to 500 characters:
.set width 500Copy the query and paste it at the BTEQ prompt.
The result looks similar to the following:
L_RETURNFLAG L_LINESTATUS sum_qty sum_base_price sum_disc_price sum_charge avg_qty avg_price avg_disc count_order ------------ ------------ ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------- N O 629900.00 943154565.63 896323924.4600 932337245.114003 25.45 38113.41 .05 24746
Run the same query in BigQuery:
Go to the BigQuery console:
Copy the query into the query editor.
Make sure that the dataset name in the
FROMline is correct.Click Run.
The result is the same as the result from Teradata.
Optionally, you can choose wider time intervals in the query to make sure all of the rows in the table are scanned.
Run the local supplier volume query
The second example query is the local supplier volume query report (section 2.4.5 of the TPC-H specification). For each nation in a region, this query returns the revenue that was produced by each line item in which the customer and the supplier were in that nation. These results are useful for something like planning where to put distribution centers.
The following listing shows the complete query:
SELECT
n_name AS nation,
SUM(l_extendedprice * (1 - l_discount) / 1000) AS revenue
FROM
tpch.customer,
tpch.orders,
tpch.lineitem,
tpch.supplier,
tpch.nation,
tpch.region
WHERE c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE'
AND o_orderdate >= '1996-01-01'
AND o_orderdate < '1997-01-01'
GROUP BY
n_name
ORDER BY
revenue DESC;
Run the query in Teradata BTEQ and in the BigQuery console as described in the previous section.
This is the result returned by Teradata:
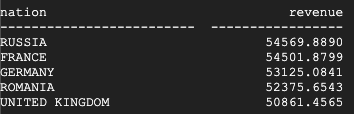
This is the result returned by BigQuery:
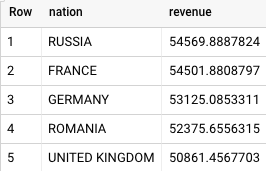
Both Teradata and BigQuery return the same results.
Run the product type profit measure query
The final test to verify the migration is the product type profit measure query last example query (section 2.4.9 in the TPC-H specification). For each nation and each year, this query finds the profit for all parts ordered in that year. It filters the results by a substring in the part names and by a specific supplier.
The following listing shows the complete query:
SELECT
nation,
o_year,
SUM(amount) AS sum_profit
FROM (
SELECT
n_name AS nation,
EXTRACT(YEAR FROM o_orderdate) AS o_year,
(l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity)/1e+3 AS amount
FROM
tpch.part,
tpch.supplier,
tpch.lineitem,
tpch.partsupp,
tpch.orders,
tpch.nation
WHERE s_suppkey = l_suppkey
AND ps_suppkey = l_suppkey
AND ps_partkey = l_partkey
AND p_partkey = l_partkey
AND o_orderkey = l_orderkey
AND s_nationkey = n_nationkey
AND p_name like '%blue%' ) AS profit
GROUP BY
nation,
o_year
ORDER BY
nation,
o_year DESC;
Run the query in Teradata BTEQ and in the BigQuery console as described in the previous section.
This is the result returned by Teradata:
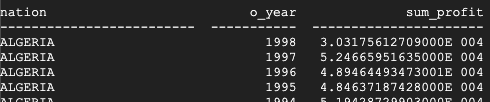
This is the result returned by BigQuery:
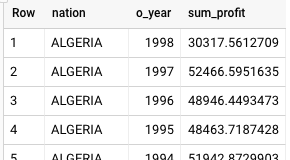
Both Teradata and BigQuery return the same results, although Teradata uses scientific notation for the sum.
Additional queries
Optionally, you can run the rest of the TPC-H queries that are defined in section 2.4 of the TPC-H specification.
You can also generate queries following the TPC-H standard using the QGEN tool,
which is in the same directory as the DBGEN tool. QGEN is built using the same
makefile as DBGEN, so when you run make to compile dbgen, you also produced
the qgen executable.
For more information on both tools and on their command-line options, see the
README file for each tool.
Cleanup
To avoid incurring charges to your Google Cloud account for the resources used in this tutorial, remove them.
Delete the project
The simplest way to stop billing charges is to delete the project you created for this tutorial.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
What's next
- Get step-by-step instructions to Migrate Teradata to BigQuery.